PySpark 中的 GroupBy 和过滤数据
在本文中,我们将使用Python对 PySpark 中的数据进行分组和过滤。
让我们创建用于演示的数据框:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
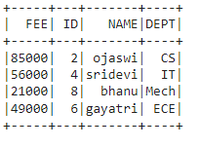
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum()
# to get FEE greater than 56700
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).filter(
col('Total Fee') >= 56700).show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum()
# to get FEE greater than or equal to
# 56700 and less than or equal to 100000
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).filter(
col('Total Fee') >= 56700).filter(
col('Total Fee') <= 100000).show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum() to get
# FEE greater than or equal to 56700
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).where(
col('Total Fee') >= 56700).show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum() to get
# FEE greater than or equal to 56700
# and less than or equal to 100000
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).where(
col('Total Fee') >= 56700).where(
col('Total Fee') <= 100000).show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import functions
from pyspark.sql import functions as f
# import window module
from pyspark.sql import Window
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.withColumn('FEE max', f.max('FEE').over(
Window.partitionBy('DEPT'))).where(
f.col('FEE') == f.col('FEE max')).show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import functions
from pyspark.sql import functions as f
# import window module
from pyspark.sql import Window
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.join(dataframe.groupBy('DEPT').agg(
f.max('FEE').alias('FEE')), on='FEE',
how='leftsemi').show()输出:
在 PySpark 中,groupBy() 用于将相同的数据收集到 PySpark DataFrame 上的组中,并对分组数据执行聚合函数。在使用该方法时,我们必须使用 groupby 中的任何一个功能
Syntax: dataframe.groupBy(‘column_name_group’).aggregate_operation(‘column_name’)
过滤数据意味着根据条件删除一些数据。在 PySpark 中,我们可以使用 filter() 和 where()函数进行过滤
方法一:使用 filter()
这用于根据条件过滤数据帧并返回结果数据帧
Syntax: filter(col(‘column_name’) condition )
filter with groupby():
dataframe.groupBy(‘column_name_group’).agg(aggregate_function(‘column_name’).alias(“new_column_name”)).filter(col(‘new_column_name’) condition )
where,
- dataframe is the input dataframe
- column_name_group is the column to be grouped
- column_name is the column that gets aggregated with aggregate operations
- aggregate_function is among the functions – sum(),min(),max() ,count(),avg()
- new_column_name is the column to be given from old column
- col is the function to specify the column on filter
- condition is to get the data from the dataframe using relational operators
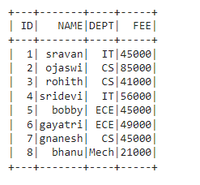
示例 1:通过使用 sum() 获得大于或等于 56700 的 FEE 来过滤数据
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum()
# to get FEE greater than 56700
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).filter(
col('Total Fee') >= 56700).show()
输出:

示例 2:具有多个条件的过滤器
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum()
# to get FEE greater than or equal to
# 56700 and less than or equal to 100000
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).filter(
col('Total Fee') >= 56700).filter(
col('Total Fee') <= 100000).show()
输出:
方法二:使用 where()
这用于根据条件选择数据帧并返回结果数据帧
Syntax: where(col(‘column_name’) condition )
where with groupby():
dataframe.groupBy(‘column_name_group’).agg(aggregate_function(‘column_name’).alias(“new_column_name”)).where(col(‘new_column_name’) condition )
where,
- dataframe is the input dataframe
- column_name_group is the column to be grouped
- column_name is the column that gets aggregated with aggregate operations
- aggregate_function is among the functions – sum(),min(),max() ,count(),avg()
- new_column_name is the column to be given from old column
- col is the function to specify the column on where
- condition is to get the data from the dataframe using relational operators
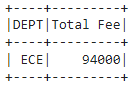
示例 1:通过使用 sum() 获得大于或等于 56700 的 FEE 来过滤数据
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum() to get
# FEE greater than or equal to 56700
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).where(
col('Total Fee') >= 56700).show()
输出:

示例 2:具有多个条件的过滤器
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum() to get
# FEE greater than or equal to 56700
# and less than or equal to 100000
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).where(
col('Total Fee') >= 56700).where(
col('Total Fee') <= 100000).show()
输出:

方法三:使用窗口函数
窗口函数用于对数据框中的列进行分区
Syntax: Window.partitionBy(‘column_name_group’)
where, column_name_group is the column that contains multiple values for partition
我们可以对包含组值的数据列进行分区,然后使用 min()、max 等聚合函数来获取数据。这样,我们将使用 where 子句过滤来自 PySpark DataFrame 的数据。
Syntax: dataframe.withColumn(‘new column’, functions.max(‘column_name’).over(Window.partitionBy(‘column_name_group’))).where(functions.col(‘column_name’) == functions.col(‘new_column_name’))
where,
- dataframe is the input dataframe
- column_name_group is the column to be partitioned
- column_name is to get the values with grouped column
- new_column_name is the new filtered column
示例:PySpark 程序仅过滤来自所有部门的数据框中的最大行
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import functions
from pyspark.sql import functions as f
# import window module
from pyspark.sql import Window
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.withColumn('FEE max', f.max('FEE').over(
Window.partitionBy('DEPT'))).where(
f.col('FEE') == f.col('FEE max')).show()
输出:

方法四:使用连接
我们可以使用 leftsemi join 过滤聚合操作的数据,这个 join 将返回 dataframe1 中的左匹配数据和聚合操作
Syntax: dataframe.join(dataframe.groupBy(‘column_name_group’).agg(f.max(‘column_name’).alias(‘new_column_name’)),on=’FEE’,how=’leftsemi’)
示例:过滤来自所有部门的最高费用数据
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import functions
from pyspark.sql import functions as f
# import window module
from pyspark.sql import Window
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.join(dataframe.groupBy('DEPT').agg(
f.max('FEE').alias('FEE')), on='FEE',
how='leftsemi').show()
输出: