Python中的探索性数据分析
什么是探索性数据分析(EDA)?
EDA 是数据分析下的一种现象,用于更好地理解数据方面,例如:
– 数据的主要特征
– 变量和它们之间的关系
– 确定哪些变量对我们的问题很重要
我们将研究各种探索性数据分析方法,例如:
- 描述性统计,这是一种简要概述我们正在处理的数据集的方法,包括样本的一些度量和特征
- 分组数据 [使用group by 进行基本分组]
- ANOVA,方差分析,这是一种计算方法,可将观察集中的变化划分为不同的分量。
- 相关和相关方法
我们将使用的数据集是子投票数据集,您可以在Python中将其导入为:
Python3
import pandas as pd
Df = pd.read_csv("https://vincentarelbundock.github.io / Rdatasets / csv / car / Child.csv")Python3
DF.describe()Python3
DF["education"].value_counts()Python3
import pandas as pd
import matplotlib.pyplot as plt
DF = pd.read_csv("https://raw.githubusercontent.com / fivethirtyeight / data / master / airline-safety / airline-safety.csv")
y = list(DF.population)
plt.boxplot(y)
plt.show()Python3
DF.groupby(['education', 'vote']).mean()描述性统计
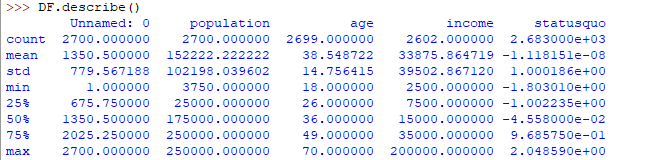
描述性统计是了解数据特征和快速总结数据的有用方法。 Python中的 Pandas 提供了一个有趣的方法describe() 。 describe函数对数据集应用基本统计计算,如极值、数据点计数标准差等。任何缺失值或 NaN 值都会被自动跳过。 describe()函数很好地描绘了数据的分布情况。
Python3
DF.describe()
这是您在运行上述代码时将获得的输出:
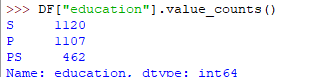
另一种有用的方法是 value_counts(),它可以获取分类属性值系列中每个类别的计数。例如,假设您正在处理一个客户数据集,这些客户在列名 age 下分为青年、中年和老年类别,并且您的数据框是“DF”。您可以运行此语句以了解有多少人属于各个类别。在我们的数据集示例中可以使用教育列
Python3
DF["education"].value_counts()
上述代码的输出将是:
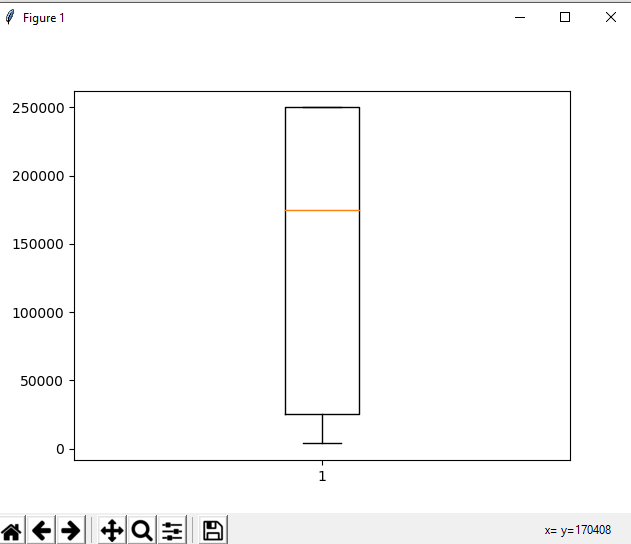
另一个有用的工具是 boxplot,您可以通过 matplotlib 模块使用它。箱线图是数据分布的图形表示,显示极值、中位数和四分位数。我们可以使用箱线图轻松找出异常值。现在再次考虑我们一直在处理的数据集,让我们在属性总体上绘制一个箱线图
Python3
import pandas as pd
import matplotlib.pyplot as plt
DF = pd.read_csv("https://raw.githubusercontent.com / fivethirtyeight / data / master / airline-safety / airline-safety.csv")
y = list(DF.population)
plt.boxplot(y)
plt.show()
发现异常值后,输出图将如下所示:
分组数据
Group by 是 pandas 中可用的一个有趣的度量,它可以帮助我们找出不同分类属性对其他数据变量的影响。让我们看一个在同一数据集上的示例,我们想找出人们的年龄和教育对投票数据集的影响。
Python3
DF.groupby(['education', 'vote']).mean()
输出会有点像这样:
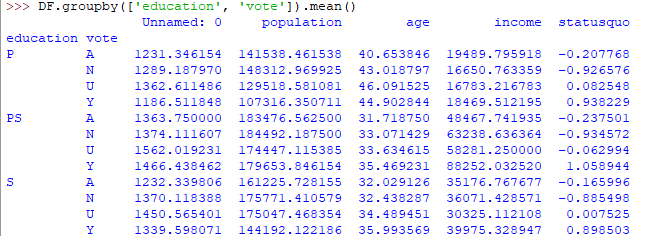
如果按输出表进行分组难以理解,则进一步的分析师使用数据透视表和热图对其进行可视化。
方差分析
ANOVA 代表方差分析。执行它是为了找出不同类别数据组之间的关系。
在 ANOVA 下,我们有两个测量结果:
– F-testscore:显示组的变化平均值超过变化
– p-value:它显示了结果的重要性
这可以使用Python模块 scipy 方法名f_oneway()来执行
句法:
这些样本是每组的样本测量值。
作为结论,如果 ANOVA 检验给我们一个大的 F 检验值和一个小的 p 值,我们可以说其他变量和分类变量之间存在很强的相关性。
相关性和相关性计算
相关性是上下文中两个变量之间的简单关系,使得一个变量影响另一个变量。相关性不同于引起的行为。计算变量之间相关性的一种方法是找到 Pearson 相关性。在这里,我们找到两个参数,即皮尔逊系数和 p 值。当 Pearson 相关系数接近 1 或 -1 且 p 值小于 0.0001 时,我们可以说两个变量之间存在很强的相关性。
Scipy 模块还提供了一种执行 pearson 相关性分析的方法,语法:
这里的示例是您要比较的属性。
这是Python中EDA的简要概述,我们可以做更多!快乐挖掘!