- 探索性数据分析 (EDA) – 类型和工具
- 探索性数据分析 (EDA) – 类型和工具(1)
- Keras-深度学习(1)
- Keras-深度学习
- Keras中的深度学习-建立深度学习模型
- Keras中的深度学习-建立深度学习模型(1)
- Python中的探索性数据分析(1)
- Python中的探索性数据分析
- Python中的探索性数据分析
- Python中的探索性数据分析(1)
- 使用Keras进行深度学习-保存模型(1)
- 使用Keras进行深度学习-保存模型
- 什么是探索性数据分析?(1)
- 什么是探索性数据分析?
- 使用Keras进行深度学习-深度学习
- 使用Keras进行深度学习-深度学习(1)
- Python中的探索性数据分析 |设置 2(1)
- Python中的探索性数据分析 |设置 2
- Python中的探索性数据分析 |设置 1(1)
- Python中的探索性数据分析 |设置 1
- 使用Keras进行深度学习-编译模型
- 使用Keras进行深度学习-编译模型(1)
- R 编程中的探索性数据分析
- R 编程中的探索性数据分析(1)
- Keras深度学习教程
- Keras深度学习教程(1)
- ML – 在 Keras 中保存深度学习模型
- ML – 在 Keras 中保存深度学习模型(1)
- Keras-深度学习概述(1)
📅 最后修改于: 2020-08-21 04:55:11 🧑 作者: Mango
介绍
深度学习是当前人工智能(AI)和机器学习中最有趣和最有前途的领域之一。近年来,随着技术和算法的巨大进步,深度学习为AI应用的新时代打开了大门。
在许多此类应用中,深度学习算法的性能与人类专家相当,有时甚至超过了他们。
Python已经成为去到语言的机器学习和许多最流行的和强大的深度学习库和框架喜欢的TensorFlow,Keras和PyTorch都建在Python。
在本文中,我们将在数据预处理之前对数据集执行探索性数据分析(EDA),最后,在Keras中构建深度学习模型并对其进行评估。
为什么选择Keras?
Keras是构建在TensorFlow之上的深度学习API。TensorFlow是一个端到端的机器学习平台,允许开发人员创建和部署机器学习模型。TensorFlow由Google开发和使用;尽管它是在2015年根据开源许可证发布的。
Keras为TensorFlow提供了一个高级API。利用TensorFlow的基础架构和可扩展性的优势,构建不同类型的机器学习模型非常容易。
它使您可以使用简单的语法定义,编译,训练和评估深度学习模型,这将在本系列的后面部分中看到。
Keras非常强大。它是Kaggle举办的各种比赛中顶级Kaggle冠军使用最多的机器学习工具。
深度学习的房价预测
我们将建立回归深度学习模型,以根据房屋特征(例如房屋的年龄,房屋的楼层数,房屋的大小以及许多其他特征)来预测房屋价格。
在本系列的第一篇文章中,我们将导入包和数据并进行一些探索性数据分析(EDA),以熟悉我们正在使用的数据集。
导入所需的软件包
在此初步步骤中,我们将导入后续步骤所需的软件包:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns我们正在导入tensorflow其中包括Keras和其他一些有用的工具。为了简化代码,我们分别导入keras和,layers因此可以代替tf.keras.layers.Dense编写layers.Dense。
我们也正在导入pandas,numpy它们非常有用,并且广泛用于存储和处理数据以及对其进行操作。
为了可视化和探索数据,我们plt从matplotlib包和中导入seaborn。Matplotlib是用于可视化的基础库,而Seaborn使它的使用更加简单。
加载数据
在本教程中,我们将使用一个数据集,该数据集报告位于美国爱荷华州一个名为Ames的城市在2006年至2010年之间的住宅销售量。
对于每次销售,数据集都描述了住宅单元的许多特征,并列出了该单元的售价。该销售价格将是我们希望使用单位的不同特征进行预测的目标变量。
数据集实际上包含每个单元的大量特征数据,包括单元面积,单元建造年份,车库大小,厨房数量,浴室数量,卧室数量,屋顶样式,电气系统的类型,建筑物的类别等。
您可以在Kaggle的此页面上阅读有关数据集的更多信息。
要下载我们将在本教程中使用的确切数据集文件,请访问其Kaggle页面,然后单击下载按钮。这将下载包含数据的CSV文件。
我们将AmesHousing.csv使用Pandas的read_csv()函数将此文件重命名为并将其加载到程序中:
df = pd.read_csv('AmesHousing.csv')加载的数据集包含2,930行(条目)和82列(特征)。这是仅几行和几列的截断视图:
| Order | PID | MS SubClass | MS Zoning | Lot Frontage | Lot Area | Street | |
| 0 | 1 | 526301100 | 20 | RL | 141 | 31770 | Pave |
| 1 | 2 | 526350040 | 20 | RH | 80 | 11622 | Pave |
| 2 | 3 | 526351010 | 20 | RL | 81 | 14267 | Pave |
探索性数据分析(EDA)
探索性数据分析(EDA)帮助我们更好地理解数据并发现其中的模式。数据中最重要的变量是目标变量:SalePrice。
机器学习模型一样好,因为训练数据-你想,如果你想了解你的模型,以了解它。建立任何模型的第一步应该是良好的数据探索。
由于最终目标是在预测房屋价值,因此我们将重点关注SalePrice变量和与其具有高度相关性的变量。
销售价格分配
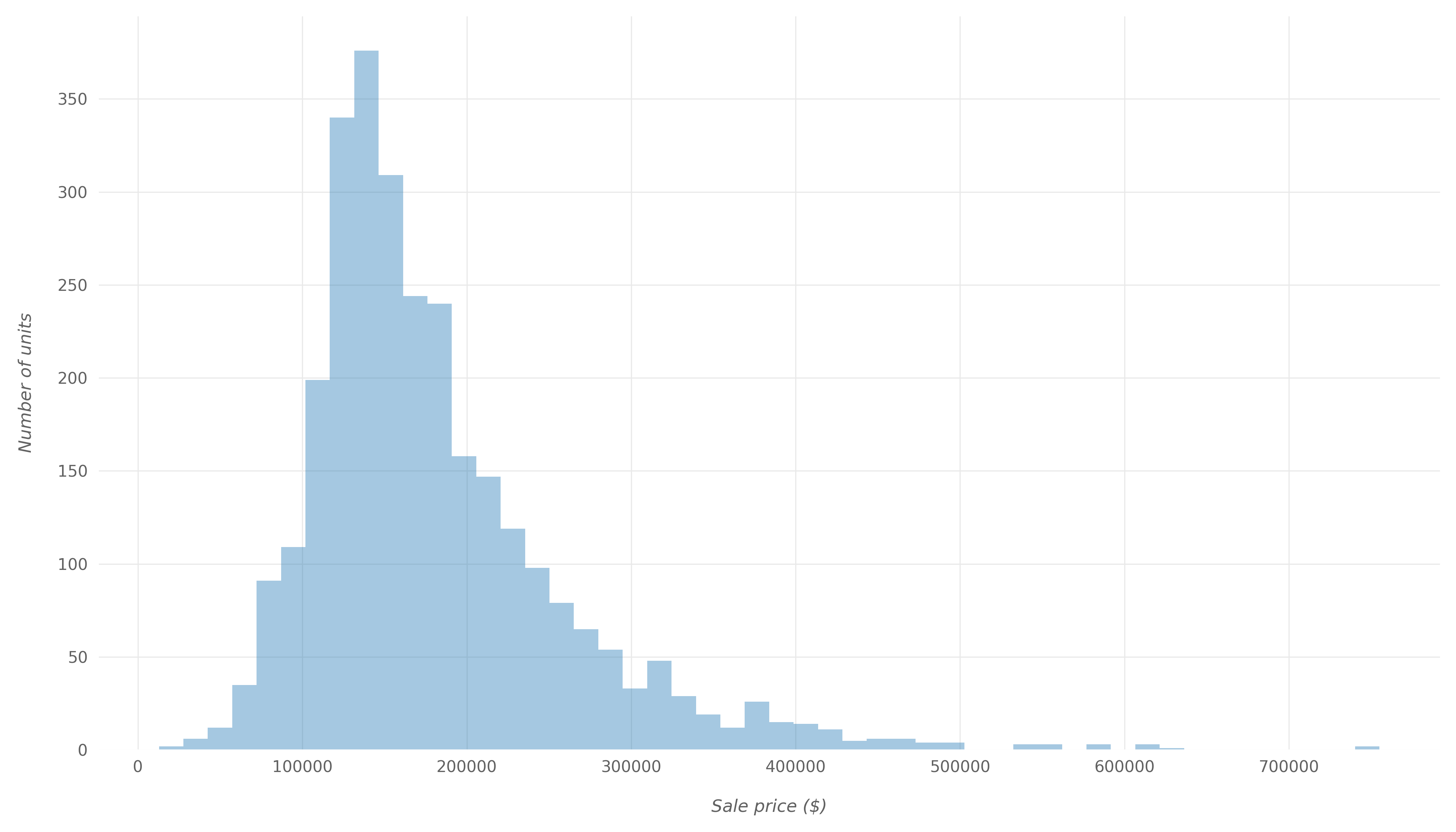
首先,让我们看一下的分布SalePrice。直方图是查看变量分布的一种好方法。让我们使用Matplotlib绘制显示的分布的直方图SalePrice:
fig, ax = plt.subplots(figsize=(14,8))
sns.distplot(df['SalePrice'], kde=False, ax=ax)下图显示了应用某种格式以增强外观后的结果直方图:
我们还可以SalePrice使用不同类型的图来查看分布。例如,让我们做一个群情节的SalePrice:
fig, ax = plt.subplots(figsize=(14,8))
sns.swarmplot(df['SalePrice'], color='#2f4b7c', alpha=0.8, ax=ax)这将导致:

通过查看上面的直方图和群图,我们可以看到大多数单位的销售价格在100,000美元到200,000美元之间。如果我们SalePrice使用Pandas describe()函数生成变量的描述:
print(df['SalePrice'].describe().apply(lambda x: '{:,.1f}'.format(x)))我们将收到:
count 2,930.0
mean 180,796.1
std 79,886.7
min 12,789.0
25% 129,500.0
50% 160,000.0
75% 213,500.0
max 755,000.0
Name: SalePrice, dtype: object从这里,我们知道:
- 平均售价为$ 180,796
- 最低销售价格为$ 12,789
- 最高销售价格为755,000美元
与售价的关系
现在,让我们看看数据中的预测变量如何与target 关联SalePrice。我们将使用Pearson方法计算这些相关值,然后使用热图可视化相关性:
fig, ax = plt.subplots(figsize=(10,14))
saleprice_corr = df.corr()[['SalePrice']].sort_values(
by='SalePrice', ascending=False)
sns.heatmap(saleprice_corr, annot=True, ax=ax) 这是热图,显示预测变量如何与关联SalePrice。
地图中的较浅颜色表示较高的正相关值,而较暗的颜色则表示较低的正相关值,有时还表示负相关值:
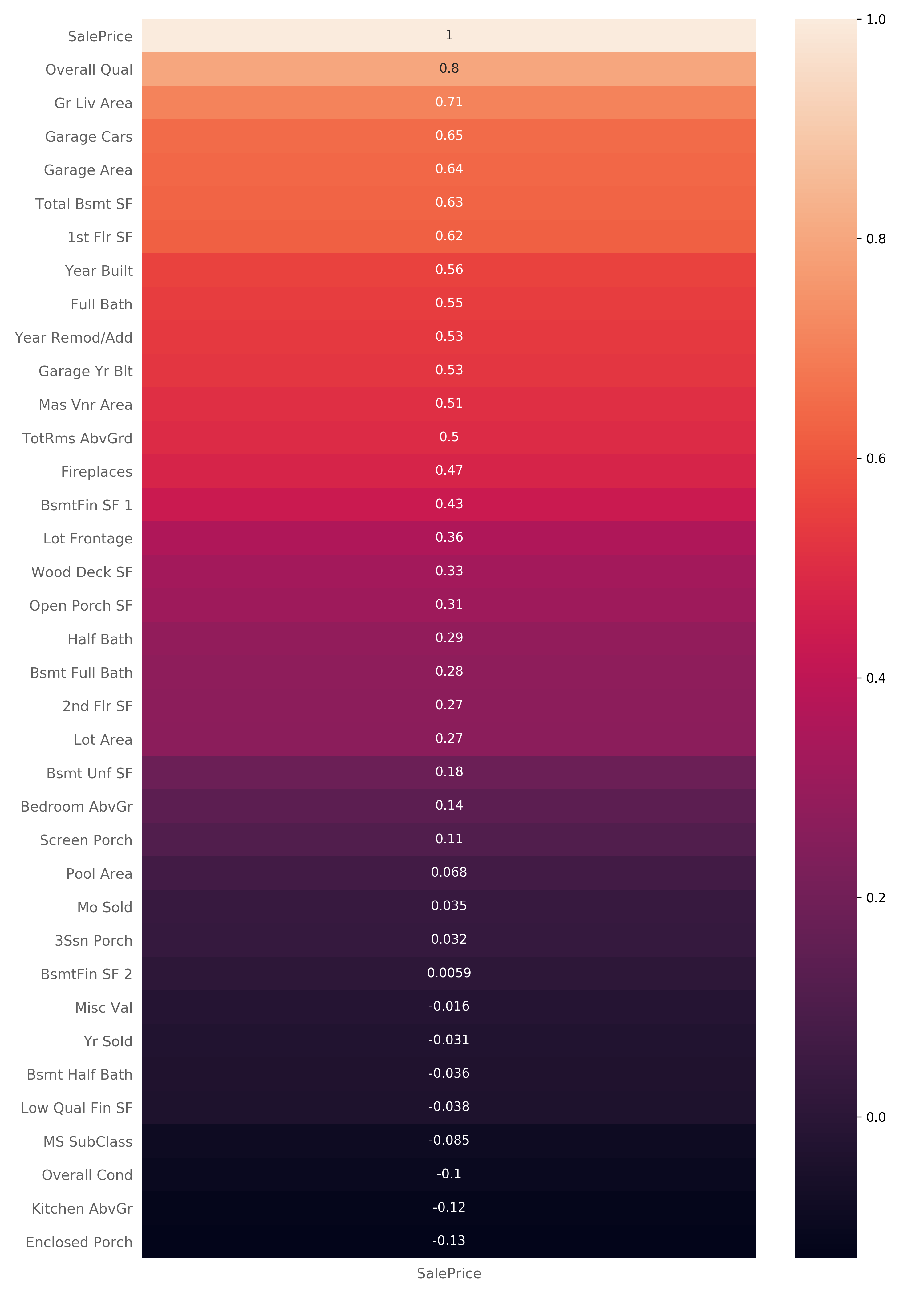
显然,SalePrice变量与自身具有1:1的相关性。不过,还有一些与高度相关的变量SalePrice,我们可以从中得出一些结论。
例如,我们可以看到它SalePrice与Overall Qual描述材料的整体质量和房屋装修的变量高度相关。我们还可以看到高度相关性,Gr Liv Area该相关性指定了单位的地面居住面积。
检查不同的相关度
现在,我们已经SalePrice牢记了一些高度相关的变量,让我们更深入地研究这些相关性。
有些变量与高度相关SalePrice,而有些则没有。通过检查这些,我们可以得出有关人们购买房屋时应优先考虑的事项的结论。
高相关
首先,让我们看一下两个具有高度正相关的变量SalePrice-即Overall Qual具有相关值的0.8和Gr Liv Area具有相关值的0.71。
Overall Qual代表房屋的整体质量和装修效果。让我们通过使用Matplotlib绘制散点图来进一步探讨它们的关系:
fig, ax = plt.subplots(figsize=(14,8))
ax.scatter(x=df['Overall Qual'], y=df['SalePrice'], color="#388e3c",
edgecolors="#000000", linewidths=0.1, alpha=0.7);
plt.show()这是生成的散点图:
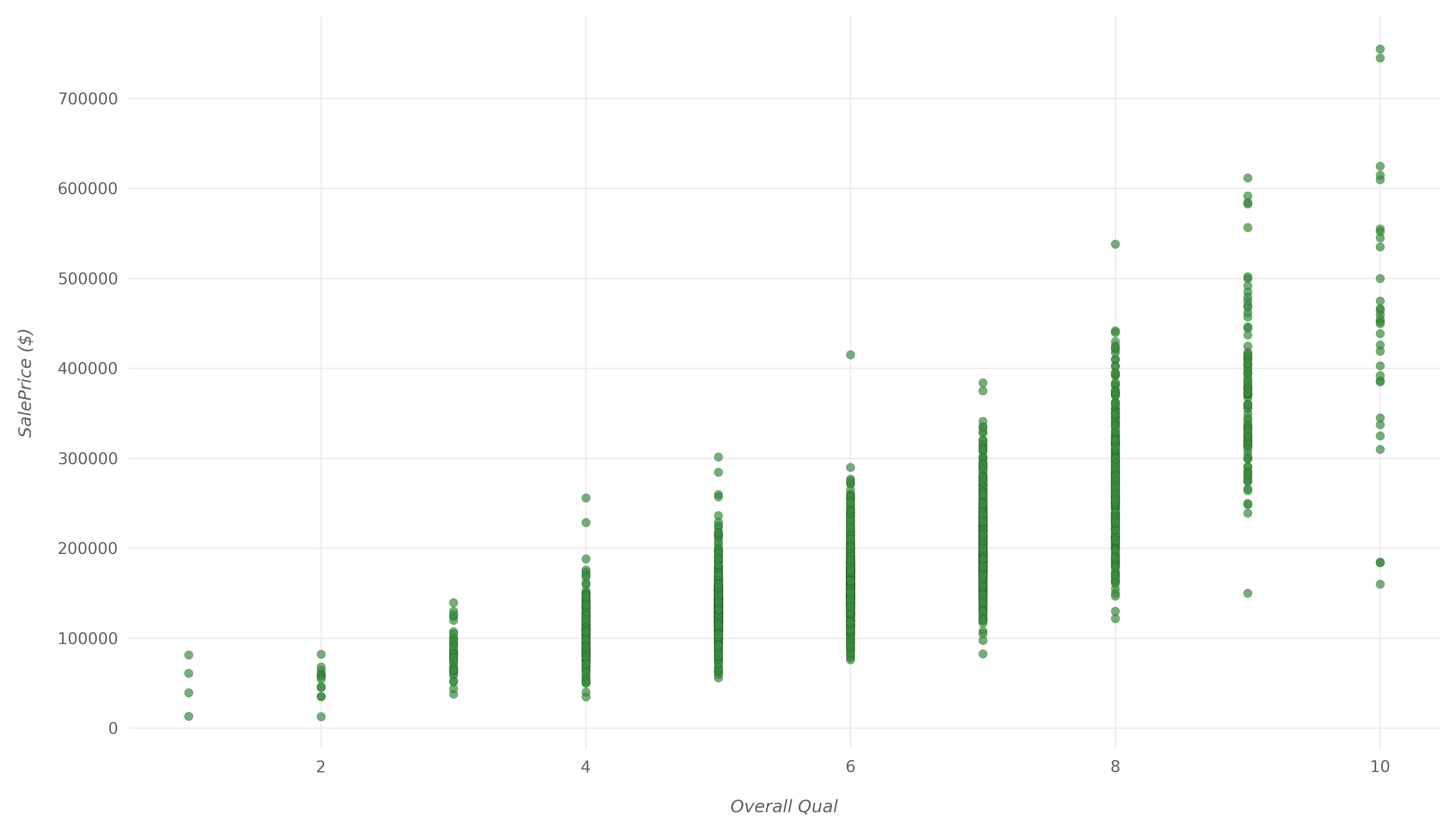
我们可以清楚地看到,随着整体质量的提高,房屋售价也趋于上涨。增长不是很线性,但是如果绘制一条趋势线,它将相对接近线性。
现在,让我们看看如何Gr Liv Area和SalePrice相互关联的另一个散点图:
fig, ax = plt.subplots(figsize=(14,8))
ax.scatter(x=df['Gr Liv Area'], y=df['SalePrice'], color="#388e3c",
edgecolors="#000000", linewidths=0.1, alpha=0.7);
plt.show()这是生成的散点图:
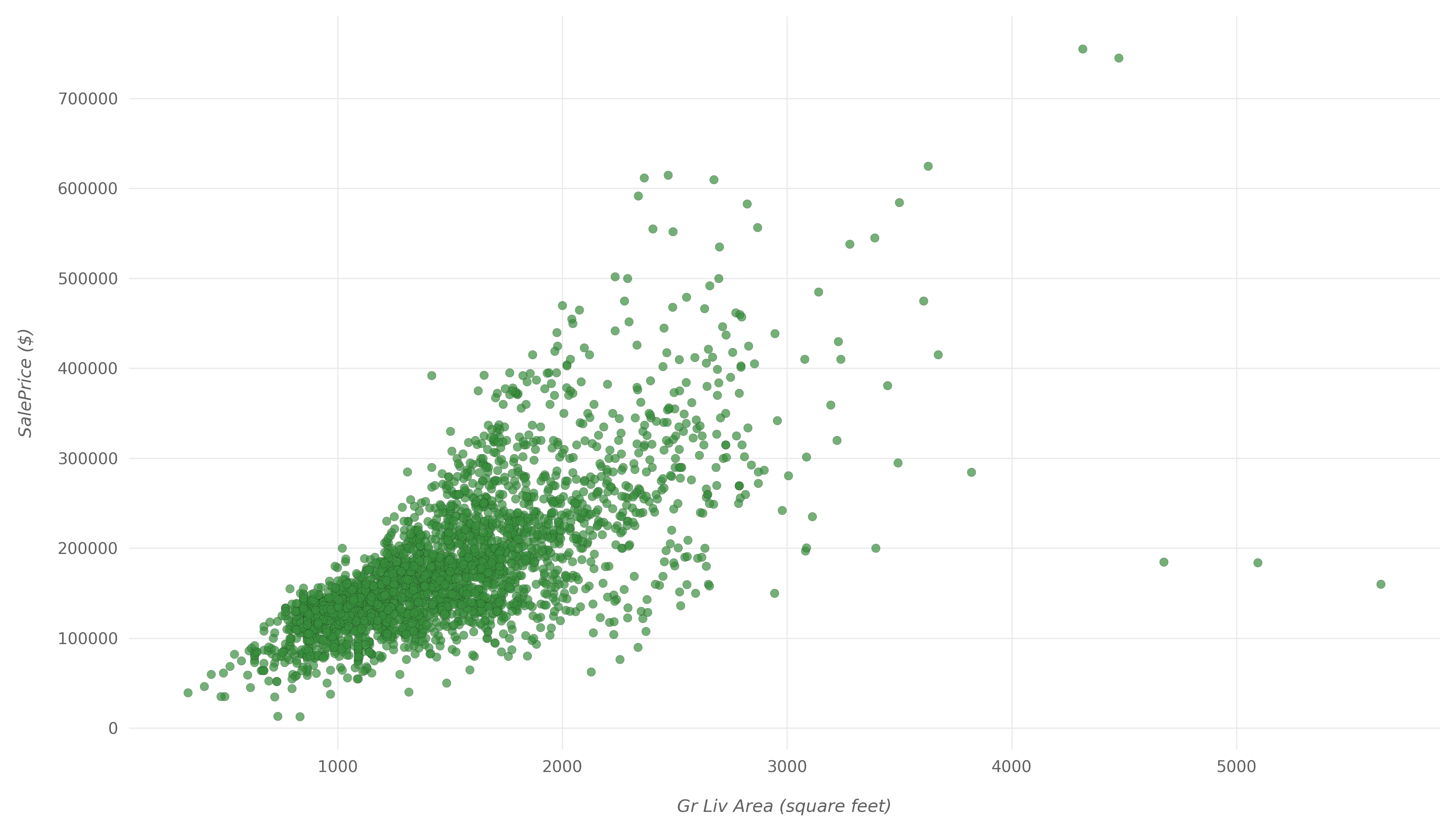
再次,我们可以清楚地看到此散点图之间Gr Liv Area和之间的高度正相关SalePrice。它们趋于彼此增加,并且具有一些异常值。
中度相关
接下来,让我们看一下与呈正相关的变量SalePrice。我们将查看Lot Frontage哪个具有相关值,0.36以及Full Bath哪个具有相关值0.55。
Lot Frontage代表整个房子的长度,一直到街上。并Full Bath表示地上完整卫生间的数量。
什么,我们有做过类似的Overall Qual和Gr Liv Area,我们将绘制两个分散图来可视化这些变量和之间的关系SalePrice。
让我们开始Lot Frontage:
fig, ax = plt.subplots(figsize=(14,8))
ax.scatter(x=df['Lot Frontage'], y=df['SalePrice'], color="orange",
edgecolors="#000000", linewidths=0.5, alpha=0.5);
plt.show()
在这里,您可以看到弱得多的相关性。即使物业前面有很多地段,价格也涨不了多少。两者之间存在正相关关系,但对买家而言,它似乎不像其他一些变量那么重要。
然后,让我们显示散点图Full Bath:
fig, ax = plt.subplots(figsize=(14,8))
ax.scatter(x=df['Full Bath'], y=df['SalePrice'], color="orange",
edgecolors="#000000", linewidths=0.5, alpha=0.5);
plt.show()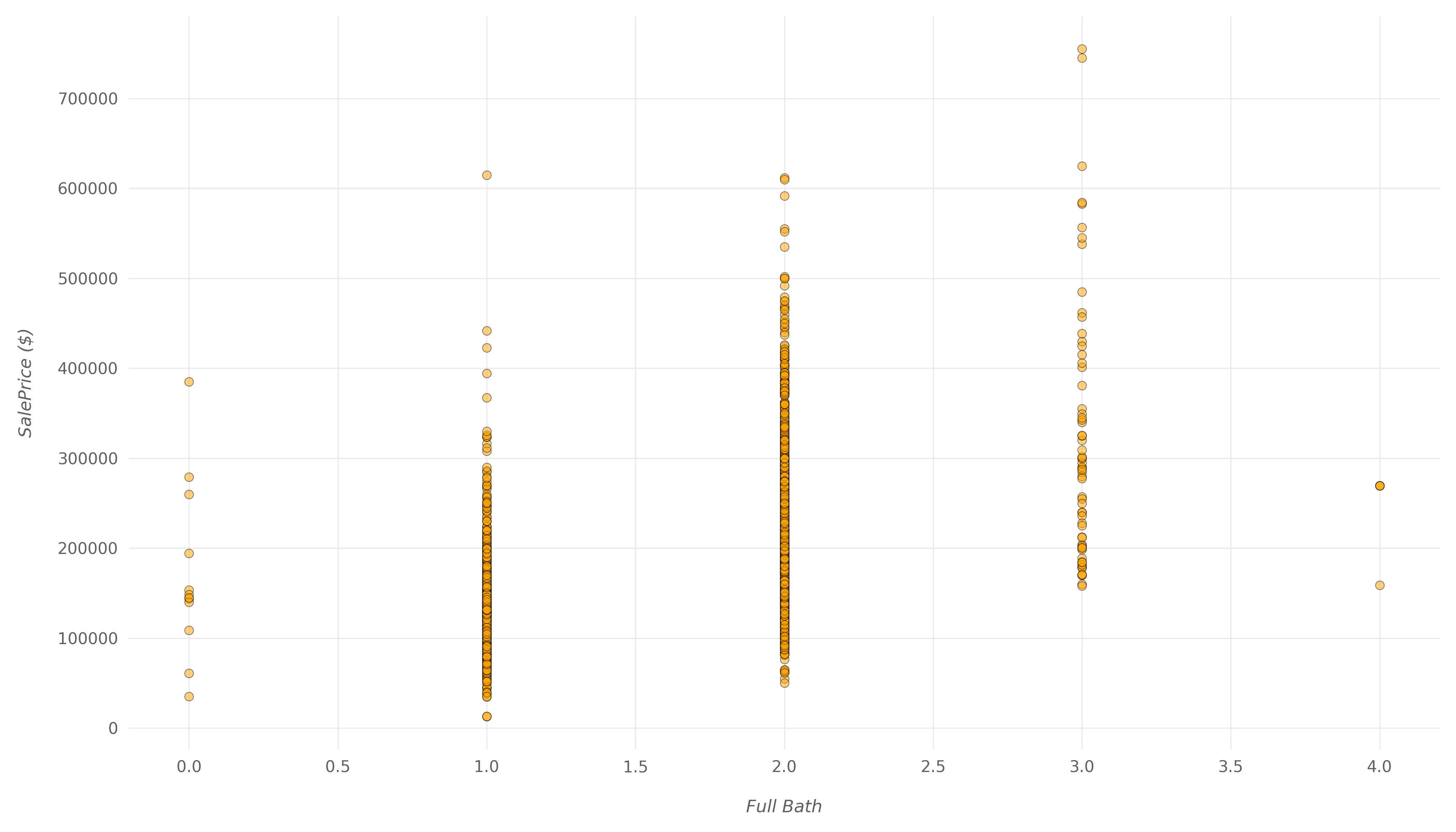
在这里,您还可以看到一个正相关关系,它不是那么弱,但是也不是太强。带有两个完整浴室的房屋中,很大一部分的价格与只有一个浴室的房屋的价格完全相同。浴室的数量确实会影响价格,但不会太大。
低相关
最后,让我们看看与的正相关性较低的变量,SalePrice并将其与到目前为止所看到的进行比较。我们将查看Yr Sold哪个具有相关值,-0.031以及Bsmt Unf SF哪个具有相关值0.18。
Yr Sold代表房屋出售的年份。并Bsmt Unf SF以平方英尺为单位表示未完成的地下室面积。
让我们开始Yr Sold:
fig, ax = plt.subplots(figsize=(14,8))
ax.scatter(x=df['Yr Sold'], y=df['SalePrice'], color="#b71c1c",
edgecolors="#000000", linewidths=0.1, alpha=0.5);
ax.xaxis.set_major_formatter(
ticker.FuncFormatter(func=lambda x,y: int(x)))
plt.show()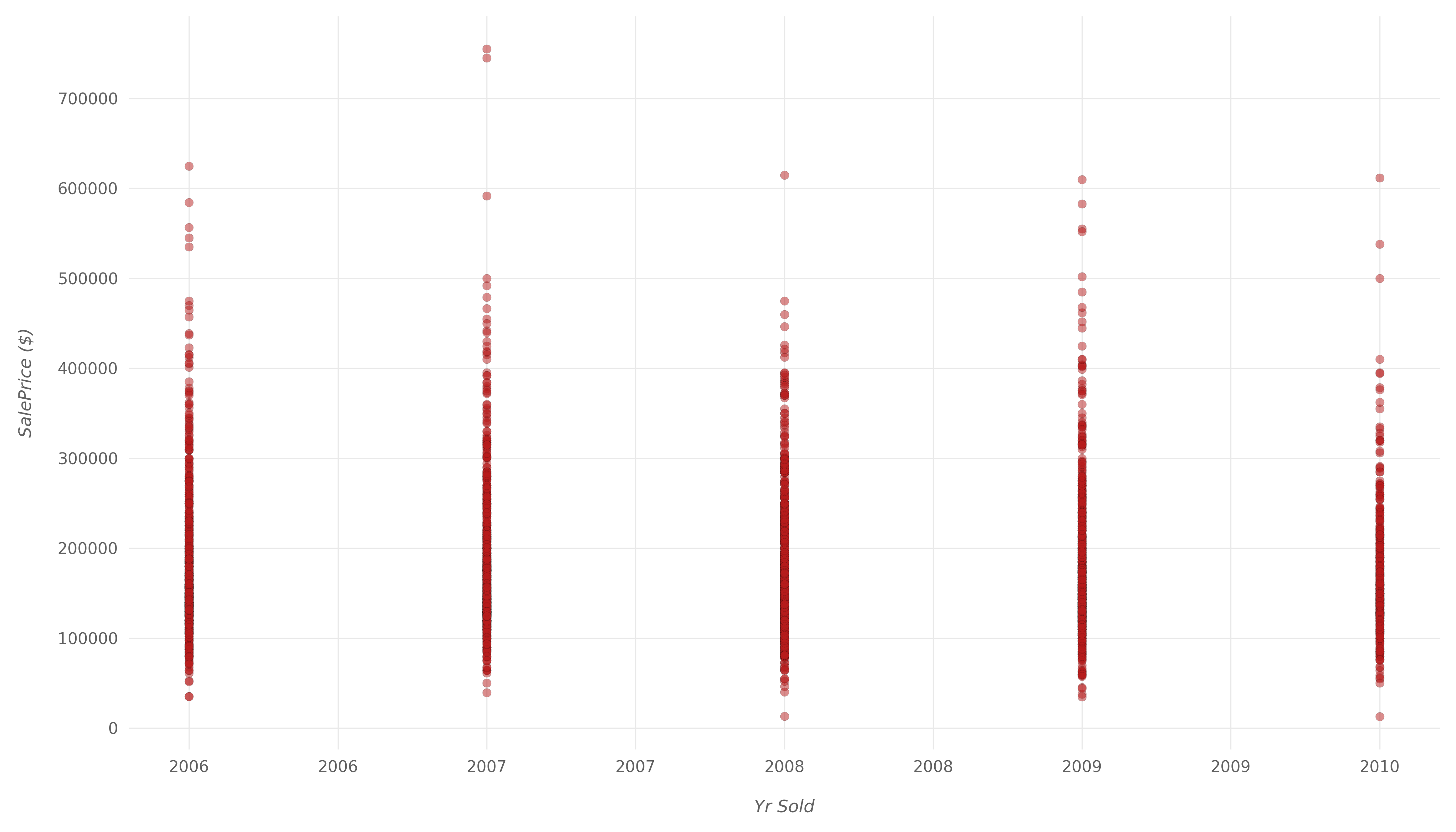
这里的相关性太弱了,因此可以很安全地假设这两个变量之间没有相关性。可以肯定地说,从2006年到2010年,房地产价格没有太大变化。
让我们为Bsmt Unf SF:
fig, ax = plt.subplots(figsize=(14,8))
ax.scatter(x=df['Bsmt Unf SF'], y=df['SalePrice'], color="#b71c1c",
edgecolors="#000000", linewidths=0.1, alpha=0.5);
plt.show()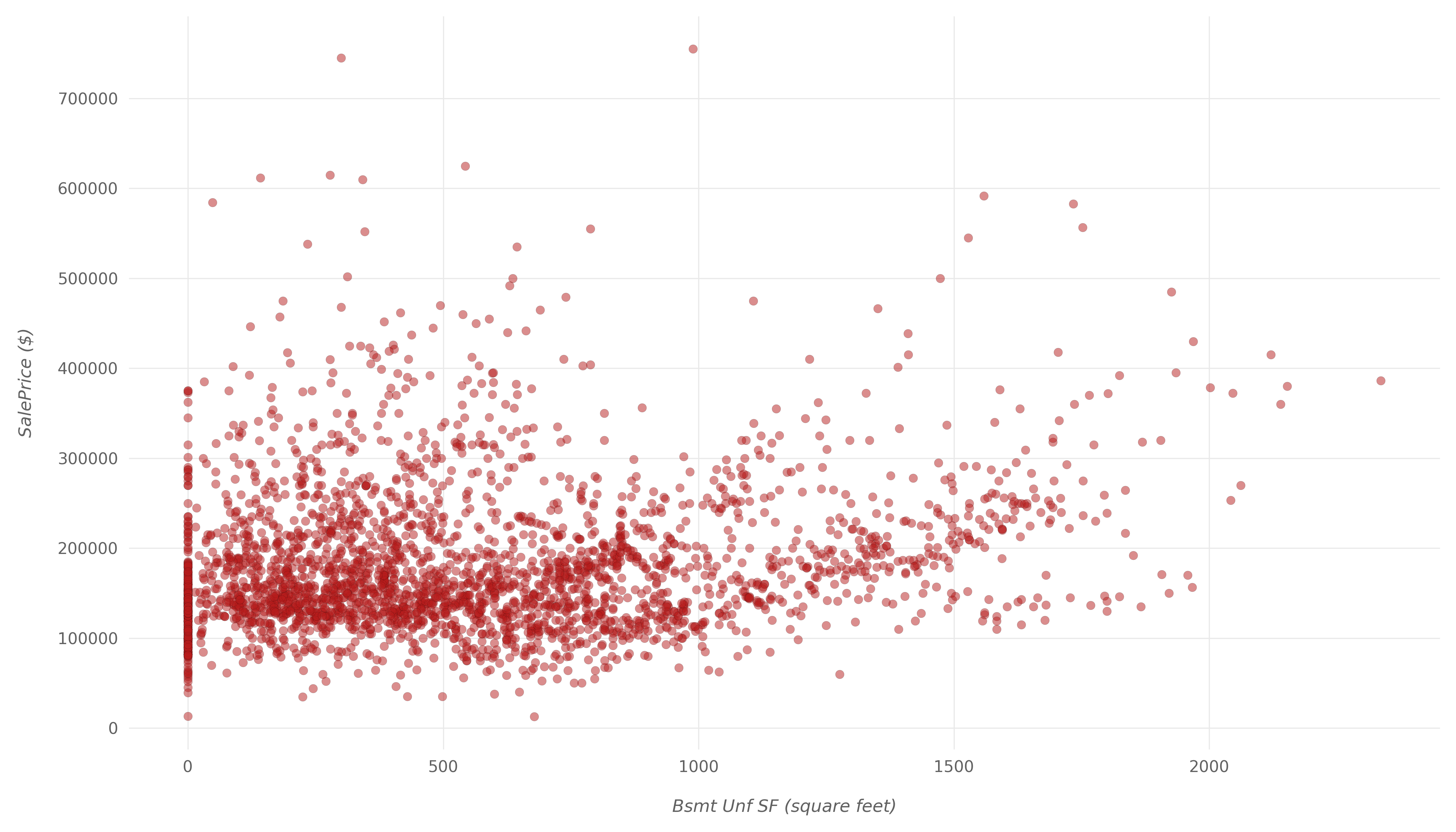
在这里,我们可以看到一些低价房产Bsmt Unf SF比高价房产被卖出。再说一次,这可能是由于纯粹的偶然性,两者之间没有明显的相关性。
可以Bsmt Unf SF肯定地认为与无关SalePrice。
结论
在本文中,我们已经在大多数机器学习项目中迈出了第一步。我们首先下载并加载了我们感兴趣的数据集。
然后,我们对数据进行了探索性数据分析,以更好地了解我们正在处理的内容。机器学习模型一样好,因为训练数据-你想,如果你想了解你的模型,以了解它。
最后,我们选择了一些变量,并检查了它们与我们关注的主要变量(变量)之间的相关性SalePrice。