使用Python抓取电视收视率
在本文中,我们将编写Python脚本从 BARC 中抓取 TRP(Television Rating Point)。 TRP 代表电视收视率,它代表在特定时期内有多少人观看了哪些频道。用于判断观看次数最多的电视节目。
需要的模块:
- bs4 : Beautiful Soup(bs4) 是一个Python库,用于从 HTML 和 XML 文件中提取数据。这个模块没有内置于Python中。要安装此类型,请在终端中输入以下命令。
pip install bs4
- requests: Request 允许您非常轻松地发送 HTTP/1.1 请求。这个模块也没有内置于Python中。要安装此类型,请在终端中输入以下命令。
pip install requests
我们来看看脚本的逐步执行
第一步:导入所有依赖
Python3
# import module
import requests
from bs4 import BeautifulSoupPython3
# user define function
# Scrape the data
def getdata(url):
r = requests.get(url)
return r.textPython3
htmldata = getdata("https://barcindia.co.in/data-insights")
soup = BeautifulSoup(htmldata, 'html.parser')
data = ''
for i in soup.find_all('tbody'):
data = data + (i.get_text())
dataPython3
data = ''.join((filter(lambda i: i not in ['\t'], data)))
print(data)第 2 步:创建 URL 获取函数
蟒蛇3
# user define function
# Scrape the data
def getdata(url):
r = requests.get(url)
return r.text
第 3 步:现在将 URL 传递到 getdata()函数并将该数据转换为 HTML 代码
蟒蛇3
htmldata = getdata("https://barcindia.co.in/data-insights")
soup = BeautifulSoup(htmldata, 'html.parser')
data = ''
for i in soup.find_all('tbody'):
data = data + (i.get_text())
data
输出:
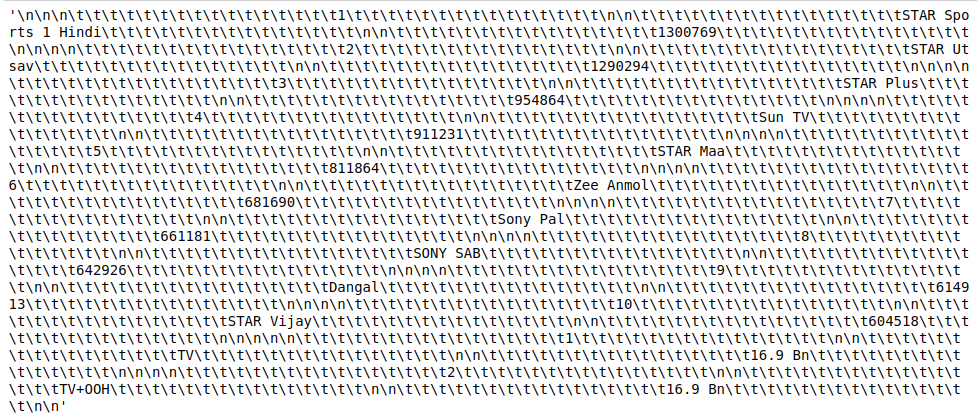
注意:这些脚本只会为您提供字符串格式的原始数据,您必须根据需要打印数据。
第 4 步:现在遍历数据。
蟒蛇3
data = ''.join((filter(lambda i: i not in ['\t'], data)))
print(data)
输出: