Pandas 中的分层抽样
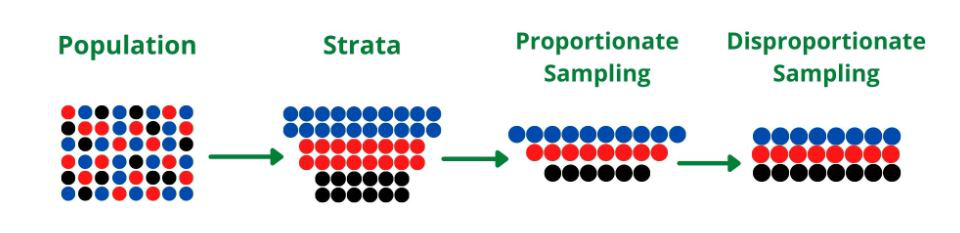
分层抽样是一种抽样技术,用于获取最能代表总体的样本。它通过将总体划分为称为层的同质子组,并从每个层(层的单一形式)随机抽样数据来减少选择样本时的偏差。
在统计学中,当每个层的平均值不同时,使用分层抽样。在机器学习中,分层抽样通常用于创建测试数据集来评估模型,尤其是当数据集非常大且不平衡时。
分层抽样涉及的步骤
- 将人口分成层:在这一步中,根据相似的特征将人口分成层,并且人口中的每个成员必须完全属于一个层(层的单数)。
- 确定样本大小:决定样本应该多小或多大。
- 对每个层进行随机抽样:使用不成比例抽样(其中每个层的样本大小与层的总体规模无关)或按比例抽样(其中每个层的样本大小与总体规模成比例)从每个层中选择随机样本地层。
示例 1:
在这个例子中,我们有一个包含 10 名学生的虚拟数据集,我们将根据他们的成绩抽取 6 名学生,使用不成比例和成比例的分层抽样。
第 1 步:使用 Pandas DataFrame 从Python字典创建虚拟数据集
Python3
import pandas as pd
# Create a dictionary of students
students = {
'Name': ['Lisa', 'Kate', 'Ben', 'Kim', 'Josh',
'Alex', 'Evan', 'Greg', 'Sam', 'Ella'],
'ID': ['001', '002', '003', '004', '005', '006',
'007', '008', '009', '010'],
'Grade': ['A', 'A', 'C', 'B', 'B', 'B', 'C',
'A', 'A', 'A'],
'Category': [2, 3, 1, 3, 2, 3, 3, 1, 2, 1]
}
# Create dataframe from students dictionary
df = pd.DataFrame(students)
# view the dataframe
dfPython3
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(2))Python3
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(frac=0.6))Python3
import pandas as pd
# read the dataset as csv file
data = pd.read_csv('Titanic.csv')
# drop the name column as it is of no importance here
data.drop('Name', axis=1, inplace=True)
# view the first 5 rows of the titanic dataset
data.head()Python3
(data['Survived'].value_counts()) / len(data) * 100Python3
# Disproportionate sampling:
# randomly select 4 samples from each stratum
data.groupby('Survived', group_keys=False).apply(lambda x: x.sample(4))Python3
data.groupby('Survived', group_keys=False).
apply(lambda x: x.sample(frac=0.01))输出:

请注意, A 级学生占 50% , B 级学生占 30% , C 级学生占 20% 。
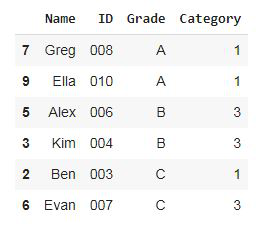
步骤 2:不成比例地创建 6 名学生的样本(每个年级的学生人数相等)
不成比例的抽样:使用pandas groupby,根据学生的成绩将学生分成组,即A、B、C,并使用sample函数从每个年级组中随机抽取2名学生
蟒蛇3
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(2))
输出:
第 3 步:按比例抽取 60% 的学生(根据每个阶层在总体中的比例从每个阶层中创建比例样本)
比例抽样:使用pandas groupby,根据学生的成绩将学生分成组,即A、B、C,并根据人口比例从每个组中随机抽取样本。总样本量为总体的 60%(0.6)
蟒蛇3
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(frac=0.6))
输出:
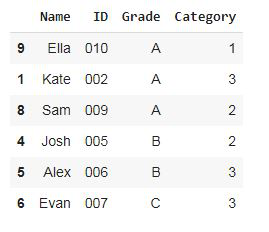
请注意,即使在样本中,也有50% 的 A 级学生、 30% 的 B 级学生和20% 的 C 级学生。
示例 2:
在这个例子中,我们将从训练数据集创建样本数据。泰坦尼克号是一名英国乘客,在撞上冰山后沉入北大西洋。该数据集包含有关登上泰坦尼克号的所有乘客的信息,其中一名乘客在坠机事故中死亡或幸存,因此我们将使用 Survived 列作为我们的分层列。
步骤 1:从 CSV 文件中读入数据集
蟒蛇3
import pandas as pd
# read the dataset as csv file
data = pd.read_csv('Titanic.csv')
# drop the name column as it is of no importance here
data.drop('Name', axis=1, inplace=True)
# view the first 5 rows of the titanic dataset
data.head()
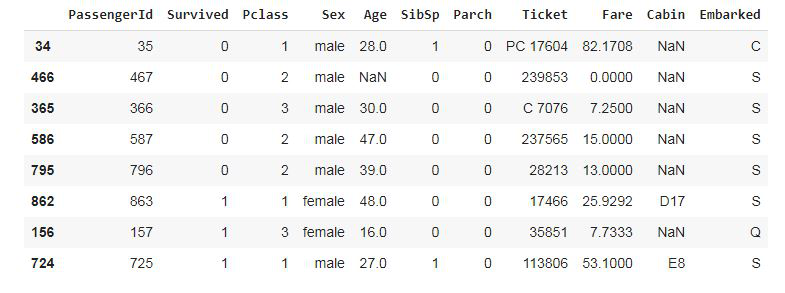
输出:
第 2 步:检查死亡/幸存乘客的百分比
检查死亡或幸存乘客的比例/百分比这是给出的死亡或活着的乘客数量/乘客总数* 100
蟒蛇3
(data['Survived'].value_counts()) / len(data) * 100
输出:
0 61.616162
1 38.383838其中0代表死亡的乘客 (61.6%) 和1代表幸存的乘客 (38.4%)
第 3 步:不成比例地抽取 8 名乘客(4 人死亡,4 人幸存)
蟒蛇3
# Disproportionate sampling:
# randomly select 4 samples from each stratum
data.groupby('Survived', group_keys=False).apply(lambda x: x.sample(4))
输出:

第 4 步:按比例抽取 1% (0.01) 名乘客(0.6% 死亡,0.4% 幸存)
蟒蛇3
data.groupby('Survived', group_keys=False).
apply(lambda x: x.sample(frac=0.01))
输出: