Python中的 Pandas 简介
Pandas 是一个开源库,主要用于轻松直观地处理关系或标记数据。它提供了用于操作数值数据和时间序列的各种数据结构和操作。该库建立在 NumPy 库之上。 Pandas 速度快,为用户提供高性能和高生产力。
Table of Content :
- History
- Advantages
- Getting Started
- Series
- DataFrame
- Why Pandas is used for Data Science
历史
Pandas 最初是由 Wes McKinney 于 2008 年在 AQR Capital Management 工作时开发的。他说服 AQR 允许他开源 Pandas。 AQR 的另一位员工 Chang She 于 2012 年作为第二个主要贡献者加入该库。随着时间的推移,已经发布了许多版本的 pandas。大熊猫的最新版本是 1.4.1
好处
- 快速高效地处理和分析数据。
- 可以加载来自不同文件对象的数据。
- 轻松处理浮点和非浮点数据中的缺失数据(表示为 NaN)
- 大小可变性:可以从 DataFrame 和更高维对象中插入和删除列
- 数据集合并和加入。
- 灵活地重塑和旋转数据集
- 提供时间序列功能。
- 强大的分组功能,用于对数据集执行拆分-应用-组合操作。
入门
pandas 安装到系统后,需要导入库。该模块通常导入为:
import pandas as pd在这里,pd 被称为 Pandas 的别名。但是,没有必要使用别名导入库,它只是有助于在每次调用方法或属性时编写更少的代码。
Pandas 一般提供两种数据结构来操作数据,它们是:
- 系列
- 数据框
系列:
Pandas Series 是一个一维标记数组,能够保存任何类型的数据(整数、字符串、浮点数、 Python对象等)。轴标签统称为索引。 Pandas 系列只不过是 Excel 工作表中的一列。标签不必是唯一的,但必须是可散列的类型。该对象支持整数和基于标签的索引,并提供了许多方法来执行涉及索引的操作。

注意:更多信息请参考Python |熊猫系列
创建系列
在现实世界中,将通过从现有存储中加载数据集来创建 Pandas 系列,存储可以是 SQL 数据库、CSV 文件、Excel 文件。 Pandas 系列可以从列表、字典和标量值等创建。
例子:
Python3
import pandas as pd
import numpy as np
# Creating empty series
ser = pd.Series()
print(ser)
# simple array
data = np.array(['g', 'e', 'e', 'k', 's'])
ser = pd.Series(data)
print(ser)Python3
import pandas as pd
# Calling DataFrame constructor
df = pd.DataFrame()
print(df)
# list of strings
lst = ['Geeks', 'For', 'Geeks', 'is',
'portal', 'for', 'Geeks']
# Calling DataFrame constructor on list
df = pd.DataFrame(lst)
print(df)输出:
Series([], dtype: float64)
0 g
1 e
2 e
3 k
4 s
dtype: object注意:有关详细信息,请参阅创建 Pandas 系列
数据框
Pandas DataFrame 是一种二维大小可变的、潜在异构的表格数据结构,带有标记的轴(行和列)。数据框是一种二维数据结构,即数据以表格的方式在行和列中对齐。 Pandas DataFrame 由三个主要组件组成,即数据、行和列。
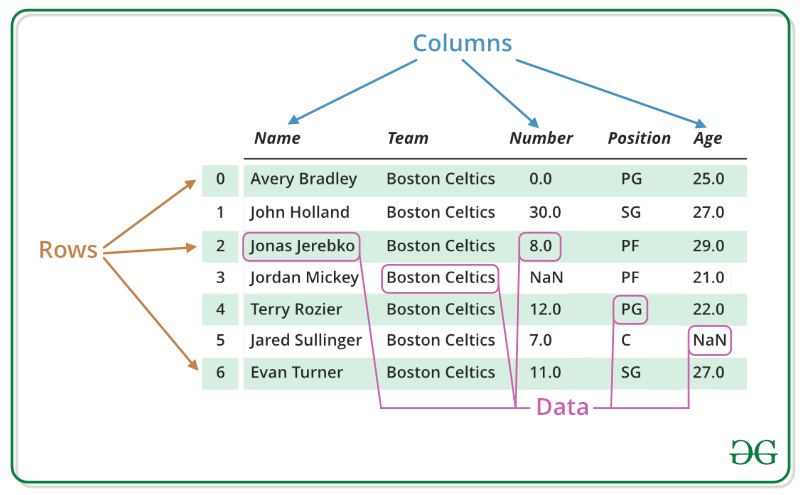
注意:更多信息请参考Python |熊猫数据框
创建一个数据框:
在现实世界中,将通过从现有存储中加载数据集来创建 Pandas DataFrame,存储可以是 SQL 数据库、CSV 文件、Excel 文件。 Pandas DataFrame 可以从列表、字典和字典列表等中创建。
例子:
Python3
import pandas as pd
# Calling DataFrame constructor
df = pd.DataFrame()
print(df)
# list of strings
lst = ['Geeks', 'For', 'Geeks', 'is',
'portal', 'for', 'Geeks']
# Calling DataFrame constructor on list
df = pd.DataFrame(lst)
print(df)
输出:
Empty DataFrame
Columns: []
Index: []
0
0 Geeks
1 For
2 Geeks
3 is
4 portal
5 for
6 Geeks注意:有关详细信息,请参阅创建 Pandas DataFrame
为什么 Pandas 用于数据科学
Pandas 通常用于数据科学,但您想知道为什么吗?这是因为 pandas 与其他用于数据科学的库结合使用。它建立在NumPy库之上,这意味着在 Pandas 中使用或复制了 NumPy 的许多结构。 Pandas 生成的数据通常用作Matplotlib的绘图函数、 SciPy中的统计分析、 Scikit-learn中的机器学习算法的输入。
Pandas 程序可以从任何文本编辑器运行,但建议使用 Jupyter Notebook,因为 Jupyter 能够在特定单元格中执行代码而不是执行整个文件。 Jupyter 还提供了一种简单的方法来可视化 pandas 数据框和绘图。
注意:有关 Jupyter Notebook 的更多信息,请参阅如何使用 Jupyter Notebook - 终极指南