在 Pandas DataFrame 中计算 NaN 或缺失值
在本文中,我们将了解如何使用 DataFrame 的isnull()和sum()方法计算 Pandas DataFrame 中的 NaN 或缺失值。
Dataframe.isnull() 方法
Pandas isnull()函数检测给定对象中的缺失值。它返回一个布尔值相同大小的对象,指示值是否为 NA。缺失值映射为 True,非缺失值映射为 False。
Syntax: DataFrame.isnull()
Parameters: None
Return Type: Dataframe of Boolean values which are True for NaN values otherwise False.
dataframe.sum() 方法
Pandas sum()函数返回请求轴的值的总和。如果输入是索引轴,则它将列中的所有值相加,并对所有列重复相同的操作,并返回一个包含每列中所有值之和的序列。它还支持在计算时跳过缺失值。
Syntax: DataFrame.sum(axis=None, skipna=None, level=None, numeric_only=None, min_count=0, **kwargs)
Parameters :
- axis : {index (0), columns (1)}
- skipna : Exclude NA/null values when computing the result.
- level : If the axis is a MultiIndex (hierarchical), count along a particular level, collapsing into a Series
- numeric_only : Include only float, int, boolean columns. If None, will attempt to use everything, then use only numeric data. Not implemented for Series.
- min_count : The required number of valid values to perform the operation. If fewer than min_count non-NA values are present the result will be NA.
Returns : sum of Series or DataFrame (if level specified).
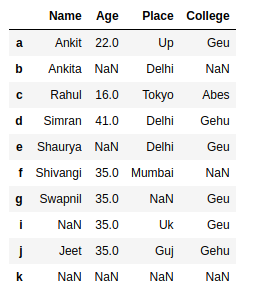
让我们创建一个熊猫数据框。
# import numpy library as np
import numpy as np
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', np.NaN, 'Delhi', np.NaN),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', np.NaN, 'Delhi', 'Geu'),
('Shivangi', 35, 'Mumbai', np.NaN ),
('Swapnil', 35, np.NaN, 'Geu'),
(np.NaN, 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
(np.NaN, np.NaN, np.NaN, np.NaN)
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =['a', 'b', 'c', 'd', 'e',
'f', 'g', 'i', 'j', 'k'])
details
输出:
示例 1:计算 DataFrame 中每一列的总 NaN。
# import numpy library as np
import numpy as np
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', np.NaN, 'Delhi', np.NaN),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', np.NaN, 'Delhi', 'Geu'),
('Shivangi', 35, 'Mumbai', np.NaN ),
('Swapnil', 35, np.NaN, 'Geu'),
(np.NaN, 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
(np.NaN, np.NaN, np.NaN, np.NaN)
]
# Create a DataFrame object from list of tuples
# with columns and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =['a', 'b', 'c', 'd', 'e',
'f', 'g', 'i', 'j', 'k'])
# show the boolean dataframe
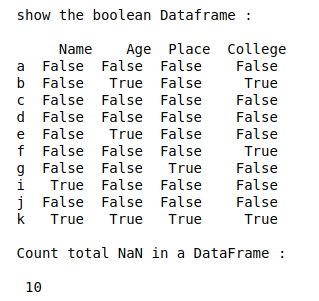
print(" \nshow the boolean Dataframe : \n\n", details.isnull())
# Count total NaN at each column in a DataFrame
print(" \nCount total NaN at each column in a DataFrame : \n\n",
details.isnull().sum())
输出:
示例 2:计算 DataFrame 中每一行的总 NaN。
# import numpy library as np
import numpy as np
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', np.NaN, 'Delhi', np.NaN),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', np.NaN, 'Delhi', 'Geu'),
('Shivangi', 35, 'Mumbai', np.NaN ),
('Swapnil', 35, np.NaN, 'Geu'),
(np.NaN, 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
(np.NaN, np.NaN, np.NaN, np.NaN)
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =['a', 'b', 'c', 'd', 'e',
'f', 'g', 'i', 'j', 'k'])
# show the boolean dataframe
print(" \nshow the boolean Dataframe : \n\n", details.isnull())
# index attribute of a dataframe
# gives index list
# Count total NaN at each row in a DataFrame
for i in range(len(details.index)) :
print(" Total NaN in row", i + 1, ":",
details.iloc[i].isnull().sum())
输出:

示例 3:计算 DataFrame 中的总 NaN。
# import numpy library as np
import numpy as np
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', np.NaN, 'Delhi', np.NaN),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', np.NaN, 'Delhi', 'Geu'),
('Shivangi', 35, 'Mumbai', np.NaN ),
('Swapnil', 35, np.NaN, 'Geu'),
(np.NaN, 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
(np.NaN, np.NaN, np.NaN, np.NaN)
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =['a', 'b', 'c', 'd', 'e',
'f', 'g', 'i', 'j', 'k'])
# show the boolean dataframe
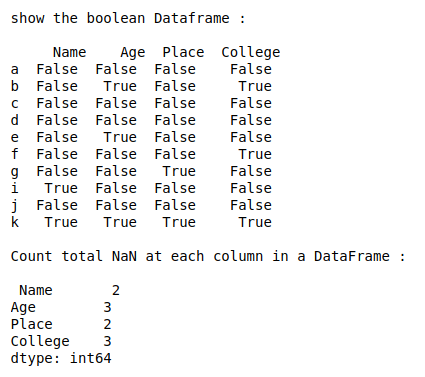
print(" \nshow the boolean Dataframe : \n\n", details.isnull())
# Count total NaN in a DataFrame
print(" \nCount total NaN in a DataFrame : \n\n",
details.isnull().sum().sum())
输出: