缓存不经意的kd-Tree
缓存忽略 kd-tree 数据结构是执行多维正交范围搜索的出色实用程序。 kd 树的显着术语之一是二元空间划分,它通过使用超平面作为分裂周期性地将空间细分为两个凸集。
本文重点详细讨论以下主题-
- 缓存不经意的 kd 树。
- Van Emde Boas 布局。
- Cache Oblivious kd 树上的操作。
- Cache Oblivious kd-tree 的优点。
- Cache Oblivious kd-tree 的限制。
Cache-Oblivious kd-tree
- 缓存不经意的 kd 树在特定的内存传输中回答查询和更新。
- 该结构可以扩大以支持具有相同更新界限的 d 维范围查询。
- 为了推进结构,使用了一些缓存遗忘结构,如 van Emde Boas 布局和指数搜索树。
- Jon Louis Bentley 提出的 kd-tree 是一棵高度为 O(log 2 N) 的二叉树,其中 N 个点存放在树的叶子中。内部节点(也是子树)通过将点集分成大小相等的两个子集的轴正交线来显示平面的周期性分解。
- 在树的偶数层上,分界线是水平的,而在奇数层上,它们是垂直的。这样,一个矩形区域 A v自发地与每个节点 v 相关,并且树的任何不同级别上的节点将平面划分为不相交的区域。有一些聚合器来决定哪个值将进入平面的 x 轴和 y 轴,如果选择特定的基本原理 x 轴,所有小于 x 的点都将进入左子树并且所有点都大于比 x 将转到正确的子树。
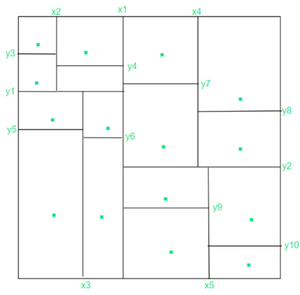
飞机分区
Van Emde Boas 布局
- Van Emde Boas 布局是在内存中建立平衡树的最佳方式,这样可以在不经意缓存的模型中有效地遍历根叶路径。
- VEB 具有访问关联数组功能的属性。像 Insert、Delete、Lookup、FindNext、FindPrevious 一样,它们随后用于在内存中布局键值对。
- Van Emde Boas 观察到,如果将键调节到集合 {1, 2, 3, ..., n} 中,那么所有操作都可以在时间 O(log log n) 和空间 O(n) 内完成。
Cache Oblivious kd-tree 上的操作
本节重点讨论Cache Oblivious kd-tree上的三个操作——
- 插入
- 查询
- 删除
让我们详细讨论这些操作中的每一个 -
1.插入:
在 Van Emde Boas 布局的帮助下,阐明了指数布局。在此布局中,具有 N 个叶子的平衡二叉树 T 递归地分解为一组组件,每个组件都使用 Van Emde Boas 布局的INSERT属性进行布局。
让我们假设为了分析结构,N 的形式为 22 ^ C,这里的 C 是一个非负整数。
- 内存格式:布局平衡二叉树的分级方式是 Van Emde Boas 的布局。这种布局中的根叶路径可以在缓存不经意模型中系统地遍历。
高度为O(log 2 N)且具有N个叶子的二叉树T可以布置在O(N)个相邻的内存位置中,这样任何根叶路径都可以在O(logN)内存传输中不经意地遍历缓存。
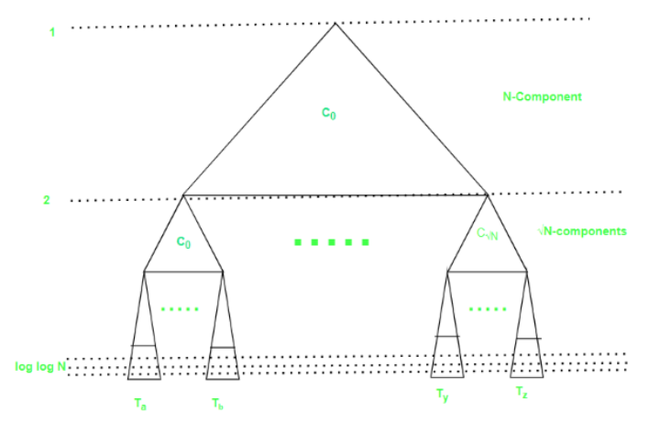
- 在这种布局中,具有N个叶子的平衡二叉树T递归地分解为一组组件,每个组件都使用 Van Emde Boas 布局进行布局。我们将组件C 0定义为由T的前1/2 log 2 N个级别组成。 C 0包含Θ(√N)个节点并被称为N分量,因为它的根是具有N个叶子的树(T)的根。
- 目标是使用 Van Emde Boas 布局获得T的指数布局。
- 首先,股票C 0使用 van Emde Boas 布局,伴随着√N 个子树的递归布局, T 1 ,T 2 ,...,T √N ,大小为√N ,位于T中的C 0之下,指示从左到右。当子树有 2 个叶子时递归停止;这样的 2-component 布局在 3 个连续的内存位置中。
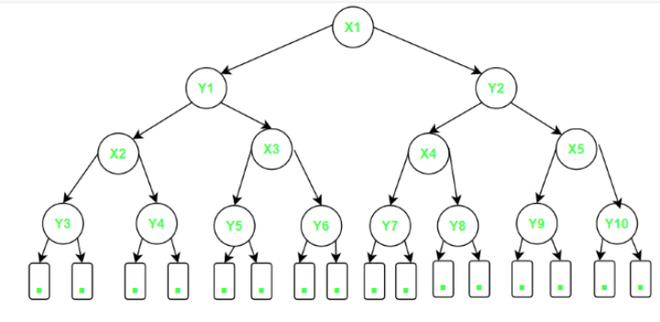
- 指数布局的含义自然定义了将T分解为log 2 log 2 N +2层,其中第i层由许多N 1/2^i-1 个分量组成。一个X分量的大小为Θ(√X) ,它的√X/2叶连接到√X分量。因此, X分量的根是包含 X 个点的 kd-tree 的根。
2.查询:
- 考虑具有 W 个叶子的平衡二叉树 F 的指数布局,并设 e 是 F 拥有 W 个叶子的子树 F e中的根。 F e的任何遍历都可以在 O(1) 内存传输中执行。
- 节点 e 存储在 F ≤ X ≤ F 2的 X 组件内。 X 分量的大小为 O(F),因此存储在 O(1) 块中。此外,不包含在 X 分量中的 F e部分以 O(1) 块的形式连续存储在内存中。因此,最佳分页策略可以确保在 O(1) 内存传输中执行 T 的任何遍历,只需加载 O(1) 相关块。
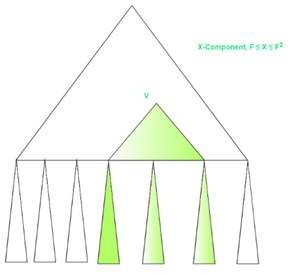
查询是如何进行的?
- 我们周期性地响应从根开始的缓存忽略 kd-tree Q 上的范围查询 C:在节点e处,如果 C 与与 e c 关联的区域 Re c相交,我们将沿着查询移动到 e 的子e c 。
- 在响应查询 C 时,限定 Q 中访问的节点数量的分级方法,或类似的,R e与 C 相交的节点 e 的数量,是首先限定 R e与垂直线j相交的节点 e 的数量.
- 与根 r 相关联的区域 R r显然与 j 相交,但由于与其两个子级相关联的区域表示 R r用一条垂直线的细分,因此只有与这些子级 r c之一相关联的区域Rrc相交.因为区域Rrc被一条水平线细分,所以与rc的两个孩子相关的区域相交。
- 由于这些孩子中的每一个都包含N/4个点,因此与 j 相交的区域数量的递归是-
C(N)=2+2C(N/4) = O(√N).
- 因此,我们可以说被一条水平线相交的区域数是O(√N) 。这意味着与 C 的边界相交的区域数为O(√N) 。回答 C 时访问的其他节点的数量以 O(Q) 为界,因为它们的相应区域完全包含在 C 中。因此,总共访问了O(√N + Q)个节点。
- 它支持O(log 2 N/B · log M/B N) = O(log 2 B N)传输中的更新。这里的“B”是一块内存。
3.删除:
- 当我们尝试从使用宽松指数布局布局的 kd 树中删除一个点时,有两个不变量。我们必须找到相关的叶子 W并删除它及其父节点。
- 第一个不变量:删除 W 可能导致沿从 T 的根到 W 的路径上的每个 O(log log N) 分量都与此不变量相矛盾。
- 令 C 为违反不变量 1 的最顶层组件。
- 设 V 为 C 的根,设 T V为以 V 为根的子树。
- 如果 T V是 X 分量,则它包含 X/2 - 1 个点。
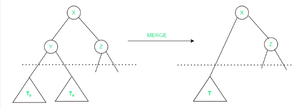
- 为了恢复不变量,我们首先收集 T V中的 X/2 − 1 个点以及子树T V`中的 X/2 ≤ X` ≤ 2X 个点,以 V 的兄弟 V` 为根,并销毁 T V 、 T V`和它们的父 Y。
- 然后我们在收集到的 K 个点上构建一个 kd-tree T`。如果 X − 1 ≤ K ≤ 2X,我们使用指数布局将 T` 布局在之前由 T v和T v`占用的空间中,并将 v 的祖父母连接到 T` 的根。
- 实际上,我们将 T v和T v`合并到 T` 中。由于 T` 在第一种情况下包含 X - 1 到 2X 个点,而在第二种情况下 T U和T U`分别包含在 X 和 5X/4 个点之间,我们可以在上述两种情况下将构造的树布局为它们的根是 X 分量的根。因此,不变量 1 被恢复。
- 搜索叶 W 需要 O(log B N) 内存传输。
- 恢复第一个不变量的总摊销成本是-
∑ i=0 log log N O( 1/B logM/B N1/2i) = O( 1/B logB N) = O(logB N) memory transfers.
- 第二不变量:删除 w 可能导致在从 T 的根到 l 的路径上的节点中违反此不变量。
- 令 v 为违反不变量 2 的最顶层节点,令 K 为以 v 为根的子树T v中的点数。
- 如果 v 在 X 分量中,则在包含 v 的 X 分量之下的T v的 O(√X) 子树T 1 , … T O(√X )使用超过 4K 的相邻存储单元。
- 不变量 2 可以通过压缩所有子树来恢复。
- 首先,压缩一个包含|T i |的子树T i遍历T i并修改|T i |中的节点相邻的存储单元。 T i的压缩布局在内存中立即伴随着T i +1的压缩布局——有效地将每个子树中的所有未使用空间推到最后一个子树的末尾——现在子树使用少于 2K 的相邻存储单元和不变量2恢复。

Cache Oblivious kd-tree 的优点:
- 在kd树构建过程中,在RAM模型中,可以在O(N log 2 N)时间内周期性地建立N个点上的kd树;使用 O(N) 时间中值算法找到根分割线,在 O(N) 时间内将这些点分配到该线所声称的两组中,并定期构建两个子树。
- 施工速度很快。
Cache Oblivious kd-tree 的局限性:
- 缓存忽略的多维范围搜索数据结构,许多具有挑战性的问题,例如改进 kd-tree 更新边界,改进范围树的空间边界,从范围树中删除块大小假设。
- 它非常快。但是,维护起来可能有点贵。
参考
- 范埃德博阿斯树
- 用于正交范围搜索的缓存忽略数据结构
- 无缓存数据结构