SpanBert 的直觉
先决条件: BERT模型
SpanBERT 与 BERT
SpanBERT 是对 BERT 模型的改进,提供了对文本跨度的改进预测。与 BERT 不同,我们在这里执行以下步骤 i) 屏蔽随机连续的跨度,而不是随机的单个令牌。
ii)基于跨度边界(称为跨度边界目标)的开始和结束处的标记训练模型以预测整个标记跨度。
它与 BERT 模型的不同之处在于其屏蔽方案,因为BERT用于随机屏蔽序列中的标记,但在SpanBERT 中,我们屏蔽了随机连续的文本跨度。
另一个区别是训练目标的不同。 BERT接受了两个目标(2 个损失函数)的训练:
- 掩码语言建模 (MLM) —预测输出中的掩码标记
- Next Sequence Prediction (NSP) —预测 2 个文本序列是否相互跟随。
但是在SpanBERT 中,模型训练的唯一对象是 Span Boundary Objective,它后来对损失函数做出了贡献。
SpanBERT:实现
为了实现 SpanBERT,我们构建了 BERT 模型的副本,但对其进行了某些更改,使其性能优于原始 BERT 模型。据观察,BERT 模型仅在单独使用“掩码语言建模”而不是“下一个序列预测”进行训练时表现要好得多。因此,我们在构建 BERT 模型的副本时忽略了 NSP 并在单序列基线上调整模型,从而提高其预测精度。
SpanBERT:直觉

图 1:训练 SpanBERT
图 1 显示了 SpanBERT 模型的训练。在给定的句子中,“足球锦标赛”这个词的跨度被掩盖了。跨度边界目标由以蓝色突出显示的x 4和x 9定义。这用于预测掩码跨度中的每个标记。
在图 1 中,创建了一个词序列“ a Football Championship Competition ”,整个序列通过编码器块,并获得对掩码标记的预测作为输出。 (x 5到 x 8 )
例如,如果我们要预测令牌 x 6 (即足球),下面是我们将得到的等效损失(如Eqn(1) 所示)。
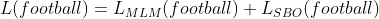
方程-(1)
这个损失是由传销和 SBO 损失给出的损失的总和。
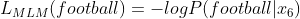
方程-(2)
现在,MLM 损失与“-ve log of possible”相同,或者更简单地说,x 6是足球的几率是多少。
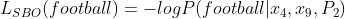
方程-(3)
Then, the SBO loss is depends on three parameters.
x4 - the start of the span boundary
x6 - the end of the span boundary
P2 - the position of x6 (football) from the starting point (x4)
So given these three parameters, we see how good the model is at predicting the token 'football'.
使用以上两个损失函数对BERT模型进行微调,称为SpanBERT。
跨边界目标:
在这里,我们将输出作为对表示为 ( x 1 , ....., x n ) 的序列中的标记进行编码的向量。标记的屏蔽范围由 ( x s , ...., x e ) 表示,其中x s表示开始, x e表示标记的屏蔽范围的结束。 SBO函数表示为:

方程-(4)
where P1, P2, ... are relative positions w.r.t the left boundary token xs-1.
SBO函数“ f”是一个带有GeLU激活的 2 层前馈网络。这个 2 层网络表示为:

方程-(5)
where,
h0 = first hidden representation
xs-1 = starting boundary word
xe+1 = ending boundary word
Pi-s+1 = positional embedding of the word
我们通过h 0 到第一个隐藏层 重量为 W 1 。

方程-(6)
where,
GeLU (Gaussian Error Linear Units) = non-linear activation function
h1 = second hidden representation
W1 = weight of first hidden layer
LayerNorm = a normalization technique used to prevent interactions within the batches
现在,我们通过另一个权重为 W 2 的层来获得输出 y i 。

方程-(7)
where,
yi = vector representation for all the toxens xi
W2 = wight of second hidden layer
概括地说,单词跨度中特定标记的 SpanBERT 等效损失计算如下:

方程-(8)
where,
Xi = final representation of tokens
xi = original sequence of tokens
yi = output obtained by passing xi through 2-layer feed forward network.
这是对 SpanBERT 模型的基本直觉和理解,以及它如何预测单词跨度而不是单个标记,使其比 BERT 模型更强大。如有任何疑问/疑问,请在下方评论。