虚拟回归器
Dummy Regressor 是一种基于简单策略进行预测而无需关注输入数据的 Regressor。与虚拟分类器类似,sklearn 库还提供虚拟回归器,用于设置比较其他现有回归器的基线,即泊松回归器、线性回归、岭回归等。但是,在本文中,主要重点是对虚拟回归和线性回归进行比较。
- 第1步 - 导入必要的模块。 sklearn 的 dummy 模块提供了一个内置的DummyRegressor模型,将在这种情况下使用。除了导入其他模块之外,均方误差和中值绝对误差值得特别一提,这样做的目的将在稍后解释。
Python3
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score, median_absolute_error
from sklearn.dummy import DummyRegressorPython3
boston=datasets.load_boston()
X=boston.data[:, None, 6]
y= boston.targetPython3
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lm = LinearRegression().fit(X_train, y_train)
lm_dummy_mean = DummyRegressor(strategy = 'mean').fit(X_train, y_train)
lm_dummy_median = DummyRegressor(strategy = 'median').fit(X_train, y_train)
y_predict = lm.predict(X_test)
y_predict_dummy_mean = lm_dummy_mean.predict(X_test)
y_predict_dummy_median = lm_dummy_median.predict(X_test)Python3
print('Linear model, coefficients: ', lm.coef_)
print("Mean squared error (dummy): {:.2f}".format(mean_squared_error(y_test,
y_predict_dummy_mean)))
print("Mean squared error (linear model): {:.2f}".format(mean_squared_error(y_test, y_predict)))
print("Median absolute error (dummy): {:.2f}".format(median_absolute_error(y_test,
y_predict_dummy_median)))
print("Median absolute error (linear model): {:.2f}".format(median_absolute_error(y_test, y_predict)))
print("r2_score (dummy mean): {:.2f}".format(r2_score(y_test, y_predict_dummy_mean)))
print("r2_score (dummy median): {:.2f}".format(r2_score(y_test, y_predict_dummy_median)))
print("r2_score (linear model): {:.2f}".format(r2_score(y_test, y_predict)))Python3
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, y_predict, color='green', linewidth=2)
plt.plot(X_test, y_predict_dummy_median, color='blue', linestyle = 'dashed',
linewidth=2, label = 'dummy')
plt.plot(X_test, y_predict_dummy_mean, color='red', linestyle = 'dashed',
linewidth=2, label = 'dummy')- 第2 步 -加载数据集。此处波士顿数据集已用于 sklearn 数据集模块中可用的目的。因为,这是一个回归问题,所以只有一个特征,即“数据”被认为是输入特征,并标记为 X 和“目标”作为目标标签的 y。为了匹配 X 和 y 维度,通过以下代码将 X 在每行中减少为 1 个元素。
Python3
boston=datasets.load_boston()
X=boston.data[:, None, 6]
y= boston.target
- 第3 步- 训练和测试虚拟模型和线性模型。下面的代码显示训练虚拟模型类似于训练任何常规回归模型,除了策略。策略的主要作用是在不受训练数据影响的情况下预测目标值。虚拟回归器使用四种类型的策略:-
- 均值:这是虚拟回归器使用的默认策略。它总是预测训练目标值的平均值。
- 中位数:用于预测训练目标值的中位数。
- 分位数:它用于预测训练目标值的特定分位数,前提是分位数参数与它一起使用。
- 常量:这通常用于预测提供的特定自定义值,并且必须提及常量参数。
Python3
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lm = LinearRegression().fit(X_train, y_train)
lm_dummy_mean = DummyRegressor(strategy = 'mean').fit(X_train, y_train)
lm_dummy_median = DummyRegressor(strategy = 'median').fit(X_train, y_train)
y_predict = lm.predict(X_test)
y_predict_dummy_mean = lm_dummy_mean.predict(X_test)
y_predict_dummy_median = lm_dummy_median.predict(X_test)
然而,在这种情况下,“均值”和“中位数”已被用于策略。但是其他两个可以根据需要使用。
在训练两个模型之后,他们在测试集上使用y_predict进行评估,线性模型使用y_predict_dummy_mean和y_predict_dummy_median分别预测虚拟平均值和中值。
- 第 4 步 -错误分析。为了了解这两个模型如何更好地执行评估指标,例如均方误差、中值绝对误差和 r2_ 分数,我们计算了线性模型和虚拟模型。均方误差和中值绝对误差与 r2_ 分数一起评估,主要是为了展示 DummyRegressor 的“均值”、“中值”策略的影响。
Python3
print('Linear model, coefficients: ', lm.coef_)
print("Mean squared error (dummy): {:.2f}".format(mean_squared_error(y_test,
y_predict_dummy_mean)))
print("Mean squared error (linear model): {:.2f}".format(mean_squared_error(y_test, y_predict)))
print("Median absolute error (dummy): {:.2f}".format(median_absolute_error(y_test,
y_predict_dummy_median)))
print("Median absolute error (linear model): {:.2f}".format(median_absolute_error(y_test, y_predict)))
print("r2_score (dummy mean): {:.2f}".format(r2_score(y_test, y_predict_dummy_mean)))
print("r2_score (dummy median): {:.2f}".format(r2_score(y_test, y_predict_dummy_median)))
print("r2_score (linear model): {:.2f}".format(r2_score(y_test, y_predict)))
输出-
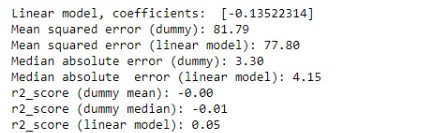
错误分析
观察:从上面的结果可以看出。预期的虚拟回归器总是将平均值和中位数的 r2_ 分数预测为 0,因为它总是在预测一个常数而不了解输出。 (通常,最佳 r2_score 为 1,Constant r2_score 为 0)。在“均方误差”、“中值绝对误差”和“r2_score”方面,线性回归模型似乎比虚拟回归模型更适合一些。
- 第5步 - 为了可视化虚拟回归器和线性回归器的性能,两个模型都绘制在测试数据上。
Python3
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, y_predict, color='green', linewidth=2)
plt.plot(X_test, y_predict_dummy_median, color='blue', linestyle = 'dashed',
linewidth=2, label = 'dummy')
plt.plot(X_test, y_predict_dummy_mean, color='red', linestyle = 'dashed',
linewidth=2, label = 'dummy')
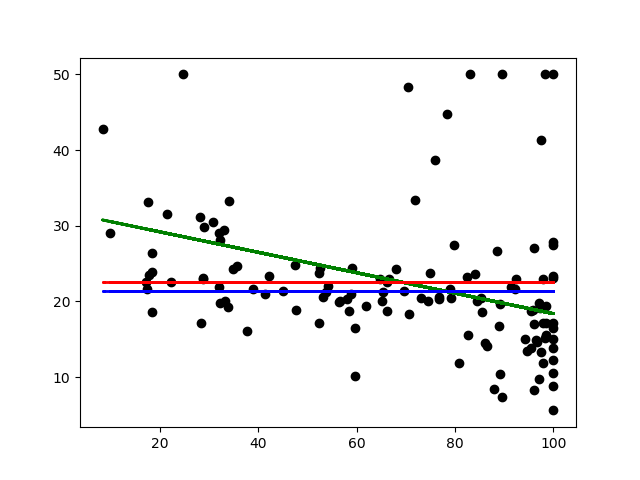
数据与目标图
结论- 上图中的散点图是测试集的实例,其趋势在右下角略微累积。绿线是适合训练点的线性回归模型。红线表示虚拟均值,始终使用预测训练集均值的策略,同样蓝线显示虚拟中值,用于预测训练集中值的相同目的。事实上,看到线性模型不太适合测试数据。
因此,现在可以最终得出结论,虚拟回归器可用于检查常规回归模型与特定数据集的拟合程度,但不能用于任何实际问题。
有关详细信息,请参阅 scikit learn 文档(“https://scikit-learn.org/stable/modules/generated/sklearn.dummy.DummyRegressor.html”)。