R 编程中的岭回归
岭回归是一种分类算法,部分原因是它不需要无偏估计量。岭回归最小化给定模型中预测变量的残差平方和。岭回归包括将系数的估计缩小到零。
R中的岭回归
岭回归是一种正则化回归算法,它执行 L2 正则化,增加了 L2 惩罚,它等于系数大小的平方。所有系数都缩小了相同的因子,即没有一个被消除。 L2 正则化不会导致稀疏模型。岭回归增加了偏差,使估计值可靠地近似于真实的总体值。岭回归通过向相关矩阵的对角元素添加一个小值k来进行,即岭回归之所以得名,是因为相关矩阵中的对角线被认为是一个岭。
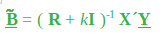
这里, k是小于 1(通常小于 0.3)的正数。估计量中的偏差量由下式给出:
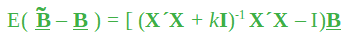
协方差矩阵由下式给出:
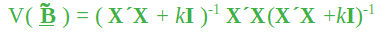
存在一个k值,其中岭估计量的均方误差(MSE,即方差加上偏差平方)小于最小二乘估计量。 k 的适当值取决于真实的回归系数(正在估计)和岭解的最优性。
- 当lambda = 0 时,岭回归等于最小二乘回归。
- 当lambda = 无穷大时,所有系数都缩小到零。
此外,理想的惩罚介于 0 和无穷大之间。让我们在 R 编程中实现岭回归。
R中的岭回归实现
数据集
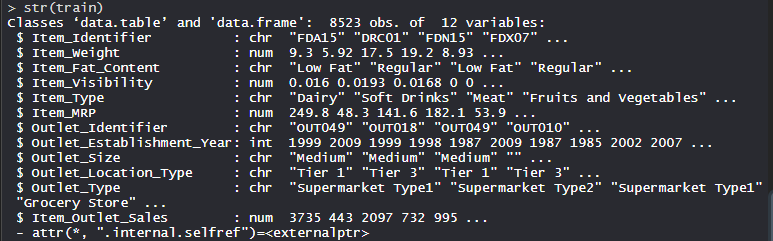
Big Mart数据集包含不同城市 10 家商店的 1559 种产品。每个产品和商店的某些属性已被定义。它由 12 个特征组成,即 Item_Identifier(是分配给每个不同项目的唯一产品 ID)、Item_Weight(包括产品的重量)、Item_Fat_Content(描述产品是否低脂)、Item_Visibility(提到产品的百分比)分配给特定产品的商店中所有产品的总展示面积),Item_Type(描述该项目所属的食品类别),Item_MRP(产品的最高零售价格(标价)),Outlet_Identifier(分配的唯一商店ID。它由一个长度为 6 的字母数字字符串组成,Outlet_Establishment_Year(提及商店成立的年份),Outlet_Size(根据所覆盖的地面面积告诉商店的大小),Outlet_Location_Type(讲述所在城市的大小)商店所在的位置)、Outlet_Type(说明该商店是杂货店还是某种超市)和 Item_Outlet_Sales(特定商店中产品的销售额)。
R
# Loading data
train = fread("Train_UWu5bXk.csv")
test = fread("Test_u94Q5KV.csv")
# Structure
str(train)R
# Installing Packages
install.packages("data.table")
install.packages("dplyr")
install.packages("glmnet")
install.packages("ggplot2")
install.packages("caret")
install.packages("xgboost")
install.packages("e1071")
install.packages("cowplot")
# load packages
library(data.table) # used for reading and manipulation of data
library(dplyr) # used for data manipulation and joining
library(glmnet) # used for regression
library(ggplot2) # used for ploting
library(caret) # used for modeling
library(xgboost) # used for building XGBoost model
library(e1071) # used for skewness
library(cowplot) # used for combining multiple plots
# Loading datasets
train = fread("Train_UWu5bXk.csv")
test = fread("Test_u94Q5KV.csv")
# Setting test dataset
# Combining datasets
# add Item_Outlet_Sales to test data
test[, Item_Outlet_Sales := NA]
combi = rbind(train, test)
# Missing Value Treatment
missing_index = which(is.na(combi$Item_Weight))
for(i in missing_index)
{
item = combi$Item_Identifier[i]
combi$Item_Weight[i] =
mean(combi$Item_Weight[combi$Item_Identifier == item],
na.rm = T)
}
# Replacing 0 in Item_Visibility with mean
zero_index = which(combi$Item_Visibility == 0)
for(i in zero_index)
{
item = combi$Item_Identifier[i]
combi$Item_Visibility[i] =
mean(combi$Item_Visibility[combi$Item_Identifier == item],
na.rm = T)
}
# Label Encoding
# To convert categorical in numerical
combi[, Outlet_Size_num := ifelse(Outlet_Size == "Small", 0,
ifelse(Outlet_Size == "Medium", 1, 2))]
combi[, Outlet_Location_Type_num :=
ifelse(Outlet_Location_Type == "Tier 3", 0,
ifelse(Outlet_Location_Type == "Tier 2", 1, 2))]
combi[, c("Outlet_Size", "Outlet_Location_Type") := NULL]
# One Hot Encoding
# To convert categorical in numerical
ohe_1 = dummyVars("~.", data = combi[, -c("Item_Identifier",
"Outlet_Establishment_Year",
"Item_Type")], fullRank = T)
ohe_df = data.table(predict(ohe_1, combi[, -c("Item_Identifier",
"Outlet_Establishment_Year",
"Item_Type")]))
combi = cbind(combi[, "Item_Identifier"], ohe_df)
# Remove skewness
skewness(combi$Item_Visibility)
skewness(combi$price_per_unit_wt)
# log + 1 to avoid division by zero
combi[, Item_Visibility := log(Item_Visibility + 1)]
# Scaling and Centering data
num_vars = which(sapply(combi, is.numeric)) # index of numeric features
num_vars_names = names(num_vars)
combi_numeric = combi[, setdiff(num_vars_names, "Item_Outlet_Sales"),
with = F]
prep_num = preProcess(combi_numeric, method=c("center", "scale"))
combi_numeric_norm = predict(prep_num, combi_numeric)
# removing numeric independent variables
combi[, setdiff(num_vars_names, "Item_Outlet_Sales") := NULL]
combi = cbind(combi, combi_numeric_norm)
# splitting data back to train and test
train = combi[1:nrow(train)]
test = combi[(nrow(train) + 1):nrow(combi)]
# Removing Item_Outlet_Sales
test[, Item_Outlet_Sales := NULL]
# Model Building :Lasso Regression
set.seed(123)
control = trainControl(method ="cv", number = 5)
Grid_la_reg = expand.grid(alpha = 1, lambda = seq(0.001,
0.1, by = 0.0002))
# Model Building : Ridge Regression
set.seed(123)
control = trainControl(method ="cv", number = 5)
Grid_ri_reg = expand.grid(alpha = 0, lambda = seq(0.001, 0.1,
by = 0.0002))
# Training Ridge Regression model
Ridge_model = train(x = train[, -c("Item_Identifier",
"Item_Outlet_Sales")],
y = train$Item_Outlet_Sales,
method = "glmnet",
trControl = control,
tuneGrid = Grid_reg
)
Ridge_model
# mean validation score
mean(Ridge_model$resample$RMSE)
# Plot
plot(Ridge_model, main="Ridge Regression")输出:
对数据集执行岭回归
在数据集上使用 Ridge 回归算法,该数据集包括 12 个特征和 1559 种产品,分布在不同城市的 10 家商店。
R
# Installing Packages
install.packages("data.table")
install.packages("dplyr")
install.packages("glmnet")
install.packages("ggplot2")
install.packages("caret")
install.packages("xgboost")
install.packages("e1071")
install.packages("cowplot")
# load packages
library(data.table) # used for reading and manipulation of data
library(dplyr) # used for data manipulation and joining
library(glmnet) # used for regression
library(ggplot2) # used for ploting
library(caret) # used for modeling
library(xgboost) # used for building XGBoost model
library(e1071) # used for skewness
library(cowplot) # used for combining multiple plots
# Loading datasets
train = fread("Train_UWu5bXk.csv")
test = fread("Test_u94Q5KV.csv")
# Setting test dataset
# Combining datasets
# add Item_Outlet_Sales to test data
test[, Item_Outlet_Sales := NA]
combi = rbind(train, test)
# Missing Value Treatment
missing_index = which(is.na(combi$Item_Weight))
for(i in missing_index)
{
item = combi$Item_Identifier[i]
combi$Item_Weight[i] =
mean(combi$Item_Weight[combi$Item_Identifier == item],
na.rm = T)
}
# Replacing 0 in Item_Visibility with mean
zero_index = which(combi$Item_Visibility == 0)
for(i in zero_index)
{
item = combi$Item_Identifier[i]
combi$Item_Visibility[i] =
mean(combi$Item_Visibility[combi$Item_Identifier == item],
na.rm = T)
}
# Label Encoding
# To convert categorical in numerical
combi[, Outlet_Size_num := ifelse(Outlet_Size == "Small", 0,
ifelse(Outlet_Size == "Medium", 1, 2))]
combi[, Outlet_Location_Type_num :=
ifelse(Outlet_Location_Type == "Tier 3", 0,
ifelse(Outlet_Location_Type == "Tier 2", 1, 2))]
combi[, c("Outlet_Size", "Outlet_Location_Type") := NULL]
# One Hot Encoding
# To convert categorical in numerical
ohe_1 = dummyVars("~.", data = combi[, -c("Item_Identifier",
"Outlet_Establishment_Year",
"Item_Type")], fullRank = T)
ohe_df = data.table(predict(ohe_1, combi[, -c("Item_Identifier",
"Outlet_Establishment_Year",
"Item_Type")]))
combi = cbind(combi[, "Item_Identifier"], ohe_df)
# Remove skewness
skewness(combi$Item_Visibility)
skewness(combi$price_per_unit_wt)
# log + 1 to avoid division by zero
combi[, Item_Visibility := log(Item_Visibility + 1)]
# Scaling and Centering data
num_vars = which(sapply(combi, is.numeric)) # index of numeric features
num_vars_names = names(num_vars)
combi_numeric = combi[, setdiff(num_vars_names, "Item_Outlet_Sales"),
with = F]
prep_num = preProcess(combi_numeric, method=c("center", "scale"))
combi_numeric_norm = predict(prep_num, combi_numeric)
# removing numeric independent variables
combi[, setdiff(num_vars_names, "Item_Outlet_Sales") := NULL]
combi = cbind(combi, combi_numeric_norm)
# splitting data back to train and test
train = combi[1:nrow(train)]
test = combi[(nrow(train) + 1):nrow(combi)]
# Removing Item_Outlet_Sales
test[, Item_Outlet_Sales := NULL]
# Model Building :Lasso Regression
set.seed(123)
control = trainControl(method ="cv", number = 5)
Grid_la_reg = expand.grid(alpha = 1, lambda = seq(0.001,
0.1, by = 0.0002))
# Model Building : Ridge Regression
set.seed(123)
control = trainControl(method ="cv", number = 5)
Grid_ri_reg = expand.grid(alpha = 0, lambda = seq(0.001, 0.1,
by = 0.0002))
# Training Ridge Regression model
Ridge_model = train(x = train[, -c("Item_Identifier",
"Item_Outlet_Sales")],
y = train$Item_Outlet_Sales,
method = "glmnet",
trControl = control,
tuneGrid = Grid_reg
)
Ridge_model
# mean validation score
mean(Ridge_model$resample$RMSE)
# Plot
plot(Ridge_model, main="Ridge Regression")
输出:
- 模型 Ridge_model:
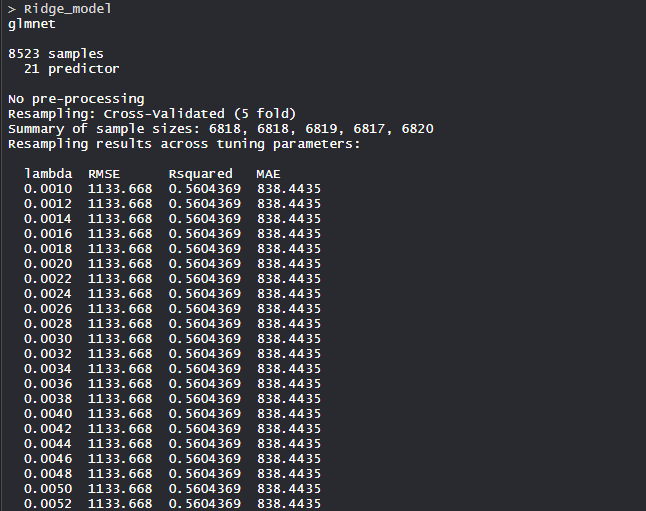
Ridge 回归模型使用 alpha 值作为 0 和 lambda 值作为 0.1。 RMSE用于使用最小值选择最佳模型。
- 平均验证分数:

平均验证分数
该模型的平均验证分数为 1133.668。
- 阴谋:
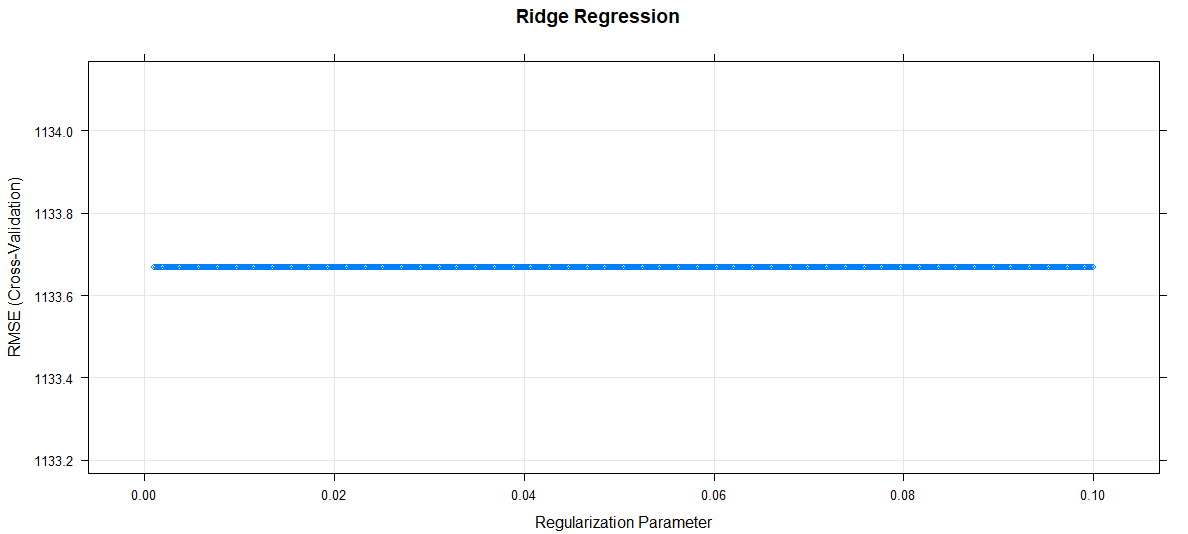
正则化参数增加,RMSE 保持不变。