R 编程中的 Apriori 算法
Apriori 算法用于在数据集中查找频繁项集以进行关联规则挖掘。它被称为 Apriori,因为它使用了频繁项集属性的先验知识。我们应用迭代方法或逐级搜索,其中使用 k 频项集来查找 k+1 项集。为了提高频繁项集逐级生成的效率,使用了一个称为 Apriori 属性的重要属性,它有助于减少搜索空间。使用 R 编程语言很容易实现这个算法。
Apriori Property: All non-empty subsets of a frequent itemset must be frequent. Apriori assumes that all subsets of a frequent itemset must be frequent (Apriori property). If an itemset is infrequent, all its supersets will be infrequent.
本质上,Apriori 算法采用较大数据集的每个部分,并以某种有序的方式将其与其他集进行对比。所得分数用于生成归类为较大数据库中频繁出现的集合,以进行聚合数据收集。在实际意义上,人们可以通过查看诸如帮助确定在购物篮中一起购买哪些项目的购物篮工具或帮助显示各种不同的财务分析工具等应用程序来更好地了解该算法。个股走势一起。 Apriori 算法可以与其他算法结合使用,以有效地对数据进行排序和对比,以更好地展示复杂系统如何反映模式和趋势。
重要的 术语
- 支持度:支持度表示项目集在数据集中出现的频率。它是包含项目“x”的记录数除以数据库中的记录总数。
- 置信度:置信度是对时间的度量,如果购买了商品“x”,则商品“y”也一起购买。它是 (x U y) 的支持计数除以“x”的支持计数。
- Lift: Lift 是观察到的支持与“x”和“y”独立时预期支持的比率。它是 (x U y) 的支持计数除以“x”和“y”的单个支持计数的乘积。
算法
- 读取事务中的每个项目。
- 计算每个项目的支持度。
- 如果支持度小于最小支持度,则丢弃该项目。否则,将其插入频繁项集中。
- 计算每个非空子集的置信度。
- 如果置信度小于最小置信度,则丢弃该子集。否则,它变成了强大的规则。
R 中的 Apriori 算法实现
RStudio 为 R 统计计算环境提供流行的开源和企业级专业软件。 R 是一种为支持统计计算和图形计算/可视化而开发的语言。它有一个名为arules的内置库函数,它实现了用于市场篮子分析的 Apriori 算法,并通过关联规则挖掘计算强规则,一旦我们根据需要指定最小支持度和最小置信度。下面给出了 Apriori 算法所需的代码和相应的输出。 Groceries数据集已用于相同的用途,该数据集在 R 的默认数据库中可用。它包含 9,835 笔交易/记录,每个记录包含从杂货店一起购买的“n”件商品。
例子:
第 1 步:加载所需的库
' arules ' 包提供了用于表示、操作和分析事务数据和模式的基础结构。
library(arules)' arulesviz ' 包用于可视化关联规则和频繁项集。它使用各种关联规则和项集的可视化技术扩展了包“arules”。该软件包还包括几个用于规则探索的交互式可视化。
library(arulesViz)' RColorBrewer ' 是一个 ColorBrewer 调色板,它为地图和其他图形提供配色方案。
library(RColorBrewer)第 2 步:导入数据集
' Groceries ' 数据集是在 R 包中预定义的。它是一组 9835 条记录/交易,每条记录/交易都有“n”个商品,这些商品是从杂货店一起购买的。
data("Groceries")第 3 步:应用 apriori()函数
' apriori() '函数内置在 R 中,使用 Apriori 算法挖掘频繁项集和关联规则。此处,“杂货”是交易数据。 “参数”是一个命名列表,它指定了查找关联规则的最小支持度和置信度。默认行为是挖掘最小支持度为 0.1 和 0.8 作为最小置信度的规则。在这里,我们将最小支持度指定为 0.01,将最小置信度指定为 0.2。
rules <- apriori(Groceries, parameter = list(supp = 0.01, conf = 0.2))第 4 步:应用 inspect()函数
inspect()函数打印 R 对象的内部表示或表达式的结果。在这里,它显示前 10 个强关联规则。
inspect(rules[1:10])第 5 步:应用 itemFrequencyPlot()函数
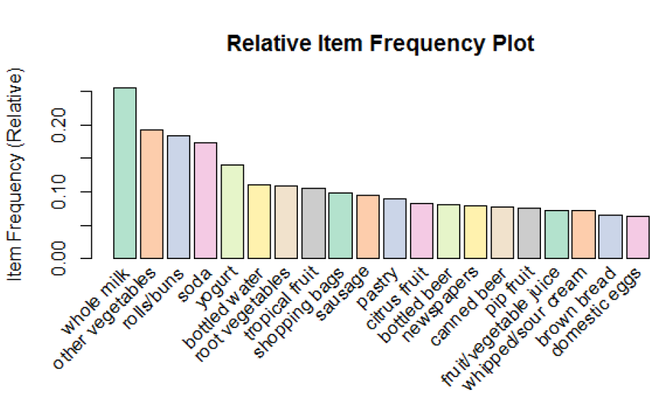
itemFrequencyPlot() 创建项目频率/支持的条形图。它创建了一个项目频率条形图,用于根据交易检查对象的分布。这些项目按降序排列。此处,“topN=20”表示将绘制具有最高项目频率/提升的 20 个项目。
arules::itemFrequencyPlot(Groceries, topN = 20,
col = brewer.pal(8, 'Pastel2'),
main = 'Relative Item Frequency Plot',
type = "relative",
ylab = "Item Frequency (Relative)")下面给出了完整的 R 代码。
R
# Loading Libraries
library(arules)
library(arulesViz)
library(RColorBrewer)
# import dataset
data("Groceries")
# using apriori() function
rules <- apriori(Groceries,
parameter = list(supp = 0.01, conf = 0.2))
# using inspect() function
inspect(rules[1:10])
# using itemFrequencyPlot() function
arules::itemFrequencyPlot(Groceries, topN = 20,
col = brewer.pal(8, 'Pastel2'),
main = 'Relative Item Frequency Plot',
type = "relative",
ylab = "Item Frequency (Relative)")输出:
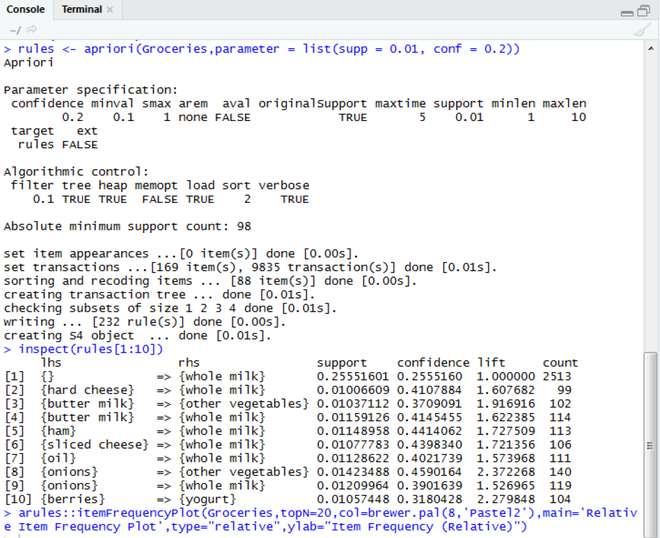
强规则:
应用Apriori算法后得到的强规则如下

为 Apriori 算法运行上述代码后,我们可以看到以下输出,指定前 10 个最强关联规则,基于支持度(最小支持度为 0.01)、置信度(最小置信度为 0.2)和提升度,并提及产品在交易中一起出现的次数。
可视化:
使用 Lift 作为参数的具有最高项目频率(相对)的前 20 个项目的箱线图
结论
我们使用了“杂货”数据集,该数据集包含大约 9835 笔交易,其中包括从商店一起购买的“n”件商品。在最小支持值为 0.01 和最小置信度为 0.2 的数据集上运行 Apriori 算法时,我们过滤掉了事务中的强关联规则。我们列出了上面的前 10 个交易,以及具有最高相对项目频率的前 20 个项目的箱线图。我们可以从这个程序中得出的一些关联规则是:
- 如果买硬奶酪,那么也买全脂牛奶。
- 如果买的是酪乳,那么全脂牛奶也要一起买。
- 如果买酪乳,那么其他蔬菜也一起买。
- 此外,全脂牛奶具有很高的支持度和置信度。
因此,将“全脂牛奶”放在可见且可触及的架子上将是有利可图的,因为它是最常购买的商品之一。此外,在放置“酪乳”的架子附近,应该有“全脂牛奶”和“其他蔬菜”的架子,因为它们的置信度很高。因此,将它们与酪乳一起购买的可能性更高。因此,通过类似的操作,我们可以通过分析用户的购物模式来提高杂货店的销售额和利润。