- R 编程中的 Apriori 算法(1)
- R 编程中的 Apriori 算法
- 机器学习算法(1)
- 机器学习算法
- 在Python中实现 Apriori 算法(1)
- 在Python中实现 Apriori 算法
- 安装 apriori 包 python (1)
- 安装 apriori 包 python 代码示例
- 机器学习中的 P 值
- 机器学习 (1)
- C++中的机器学习
- C++中的机器学习(1)
- 机器学习中的 P 值(1)
- 机器学习-分类算法
- 机器学习-分类算法(1)
- 机器学习-Scikit学习算法(1)
- 机器学习-Scikit学习算法
- 机器学习 python (1)
- 机器学习 python 代码示例
- 机器学习 - 任何代码示例
- 在机器学习中什么是“i” (1)
- 机器学习-什么是P值
- 机器学习-什么是P值(1)
- 什么是机器学习?(1)
- 什么是机器学习?
- 学习 python 机器学习 - 任何代码示例
- 机器学习-什么是机器学习? -指导点(1)
- 机器学习-什么是机器学习? -指导点
- 使用Python机器学习-方法
📅 最后修改于: 2020-09-29 01:30:52 🧑 作者: Mango
机器学习中的Apriori算法
Apriori算法使用频繁的项目集来生成关联规则,并且设计为在包含事务的数据库上工作。借助这些关联规则,它可以确定两个对象之间的连接强度。该算法使用广度优先搜索和哈希树来有效地计算项目集关联。这是从大型数据集中查找频繁项集的迭代过程。
该算法由R. Agrawal和Srikant在1994年提出。它主要用于市场购物篮分析,有助于找到可以一起购买的产品。它也可以用于医疗保健领域,以查找患者的药物反应。
什么是频繁项集?
频繁项目集是那些支持量大于阈值或用户指定的最小支持量的项目。这意味着,如果A和B一起是频繁项目集,那么单独的A和B也应该是频繁项目集。
假设有两个事务:A = {1,2,3,4,5}和B = {2,3,7},在这两个事务中,2和3是频繁项集。
注意:为了更好地理解先验算法以及相关术语(例如支持和置信度),建议您了解关联规则学习。
Apriori算法的步骤
以下是先验算法的步骤:
步骤1:确定事务数据库中项目集的支持,然后选择最小支持和置信度。
步骤2:以高于最小或选定支持值的支持值获取交易中的所有支持。
步骤3:找到这些子集的所有规则,这些规则的置信度值高于阈值或最小置信度。
步骤4:按升序的降序对规则进行排序。
Apriori算法工作
我们将通过一个示例和数学计算来理解apriori算法:
示例:假设我们具有以下包含各种事务的数据集,并且需要从该数据集中查找频繁项集并使用Apriori算法生成关联规则:

解:
步骤1:计算C1和L1:
- 在第一步中,我们将创建一个表,其中包含给定数据集中每个项目集的支持计数(数据集中每个项目集的频率)。该表称为候选集或C1。

- 现在,我们将取出支持数量比最小支持(2)大的所有项目集。它将为我们提供常用项目集L1的表。
由于除E之外,所有项目集都具有比最小支持更大或相等的支持计数,因此将删除E项目集。

步骤2:候选代C2和L2:
- 在此步骤中,我们将借助L1生成C2。在C2中,我们将以子集的形式创建L1的一对项集。
- 创建子集后,我们将再次从数据集的主事务表中找到支持计数,即,这些对在给定数据集中一起出现了多少次。因此,我们将获得C2的下表:
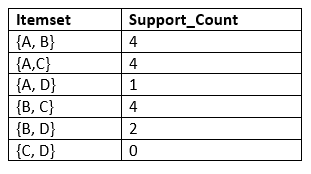
- 同样,我们需要将C2支持计数与最小支持计数进行比较,比较之后,将从表C2中删除具有较少支持计数的项目集。它将为我们提供L2的下表

步骤3:候选世代C3和L3:
- 对于C3,我们将重复相同的两个过程,但是现在,我们将组成三个项目集的子集的C3表,并从数据集中计算支持计数。它将给出下表:
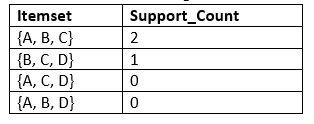
- 现在我们将创建L3表。从上面的C3表中可以看到,只有一组支持项等于最小支持项的项集。因此,L3将只有一个组合,即{A,B,C}。
步骤4:找到子集的关联规则:
要生成关联规则,首先,我们将使用出现的组合{A,BC}中的可能规则创建一个新表。对于所有规则,我们将使用公式sup(A ^ B)/ A计算置信度。在计算完所有规则的置信度值后,我们将排除置信度小于最小阈值(50%)的规则。
请看下表:
| Rules | Support | Confidence |
|---|---|---|
| A ^B → C | 2 | Sup{(A ^B) ^C}/sup(A ^B)= 2/4=0.5=50% |
| B^C → A | 2 | Sup{(B^C) ^A}/sup(B ^C)= 2/4=0.5=50% |
| A^C → B | 2 | Sup{(A ^C) ^B}/sup(A ^C)= 2/4=0.5=50% |
| C→ A ^B | 2 | Sup{(C^( A ^B)}/sup(C)= 2/5=0.4=40% |
| A→ B^C | 2 | Sup{(A^( B ^C)}/sup(A)= 2/6=0.33=33.33% |
| B→ B^C | 2 | Sup{(B^( B ^C)}/sup(B)= 2/7=0.28=28% |
由于给定的阈值或最小置信度为50%,因此前三个规则A ^ B→C,B ^ C→A和A ^ C→B可以视为给定问题的强关联规则。
Apriori算法的优点
- 这是易于理解的算法
- 该算法的加入和修剪步骤可以在大型数据集上轻松实现。
Apriori算法的缺点
- 与其他算法相比,先验算法工作缓慢。
- 由于它多次扫描数据库,因此可能会降低整体性能。
- 先验算法的时间复杂度和空间复杂度为O(2 D ),非常高。 D代表数据库中存在的水平宽度。
Apriori算法的Python实现
现在我们将看到Apriori算法的实际实现。为了实现这一点,我们遇到了一个零售商的问题,该零售商希望找到商店产品之间的关联,以便他可以向其顾客提供“购买并获取”的报价。
零售商具有数据集信息,该数据集信息包含其客户进行的交易的列表。在数据集中,每一行显示客户购买的产品或客户进行的交易。为了解决这个问题,我们将执行以下步骤:
- 数据预处理
- 在数据集上训练Apriori模型
- 可视化结果
1.数据预处理步骤:
第一步是数据预处理步骤。在此之下,首先,我们将执行库的导入。下面给出了此代码:
- 导入库:
在导入库之前,我们将使用以下代码行安装apyori软件包以进一步使用,因为Spyder IDE不包含它:
pip install apyroi
以下是实现将用于模型的不同任务的库的代码:
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
- 导入数据集:
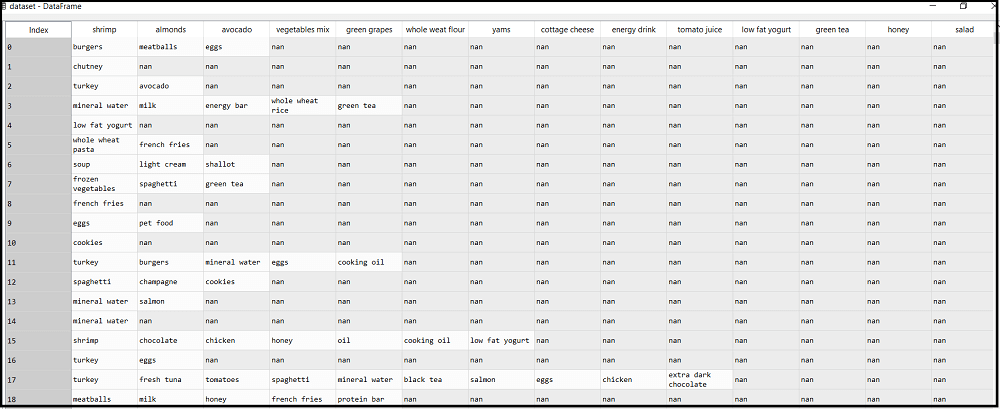
现在,我们将导入先验模型的数据集。要导入数据集,此处将进行一些更改。数据集的所有行都显示客户进行的不同交易。第一行是第一位客户完成的交易,这意味着每一列都没有特定的名称,并且具有各自的值或产品详细信息(请参见下面的代码后的数据集)。因此,我们需要在代码中提到没有指定标头。代码如下:
#Importing the dataset
dataset = pd.read_csv('Market_Basket_data1.csv')
transactions=[]
for i in range(0, 7501):
transactions.append([str(dataset.values[i,j]) for j in range(0,20)])
在上面的代码中,第一行显示将数据集导入为pandas格式。使用代码的第二行,因为我们将用于训练模型的apriori()以事务列表的格式获取数据集。因此,我们创建了一个空的交易清单。该列表将包含从0到7500的所有项目集。在这里,我们采用了7501,因为在Python,不考虑最后一个索引。
数据集如下图所示:
2.在数据集上训练Apriori模型
为了训练模型,我们将使用将从apyroi包中导入的apriori 函数 。此函数将返回规则以在数据集上训练模型。考虑下面的代码:
from apyori import apriori
rules= apriori(transactions= transactions, min_support=0.003, min_confidence = 0.2, min_lift=3, min_length=2, max_length=2)
在上面的代码中,第一行是导入apriori 函数。在第二行中,apriori 函数将输出作为规则返回。它采用以下参数:
- Transactions :交易清单。
- min_support =设置最小支持浮动值。在这里,我们使用0.003,这是通过每周每位客户进行3笔交易到交易总数中得出的。
- min_confidence :设置最小置信度值。这里我们取0.2。可以根据业务问题进行更改。
- min_lift =设置最小升程值。
- min_length =关联需要最少的产品数量。
- max_length =关联使用最大产品数。
3.可视化结果
现在,我们将可视化我们先验模型的输出。在这里,我们将按照以下步骤进行操作:
- 显示先验函数产生的规则结果
results= list(rules)
results
通过执行以上代码行,我们将获得9条规则。考虑以下输出:
输出:
[RelationRecord(items=frozenset({'chicken', 'light cream'}), support=0.004533333333333334, ordered_statistics=[OrderedStatistic(items_base=frozenset({'light cream'}), items_add=frozenset({'chicken'}), confidence=0.2905982905982906, lift=4.843304843304844)]),
RelationRecord(items=frozenset({'escalope', 'mushroom cream sauce'}), support=0.005733333333333333, ordered_statistics=[OrderedStatistic(items_base=frozenset({'mushroom cream sauce'}), items_add=frozenset({'escalope'}), confidence=0.30069930069930073, lift=3.7903273197390845)]),
RelationRecord(items=frozenset({'escalope', 'pasta'}), support=0.005866666666666667, ordered_statistics=[OrderedStatistic(items_base=frozenset({'pasta'}), items_add=frozenset({'escalope'}), confidence=0.37288135593220345, lift=4.700185158809287)]),
RelationRecord(items=frozenset({'fromage blanc', 'honey'}), support=0.0033333333333333335, ordered_statistics=[OrderedStatistic(items_base=frozenset({'fromage blanc'}), items_add=frozenset({'honey'}), confidence=0.2450980392156863, lift=5.178127589063795)]),
RelationRecord(items=frozenset({'ground beef', 'herb & pepper'}), support=0.016, ordered_statistics=[OrderedStatistic(items_base=frozenset({'herb & pepper'}), items_add=frozenset({'ground beef'}), confidence=0.3234501347708895, lift=3.2915549671393096)]),
RelationRecord(items=frozenset({'tomato sauce', 'ground beef'}), support=0.005333333333333333, ordered_statistics=[OrderedStatistic(items_base=frozenset({'tomato sauce'}), items_add=frozenset({'ground beef'}), confidence=0.37735849056603776, lift=3.840147461662528)]),
RelationRecord(items=frozenset({'olive oil', 'light cream'}), support=0.0032, ordered_statistics=[OrderedStatistic(items_base=frozenset({'light cream'}), items_add=frozenset({'olive oil'}), confidence=0.20512820512820515, lift=3.120611639881417)]),
RelationRecord(items=frozenset({'olive oil', 'whole wheat pasta'}), support=0.008, ordered_statistics=[OrderedStatistic(items_base=frozenset({'whole wheat pasta'}), items_add=frozenset({'olive oil'}), confidence=0.2714932126696833, lift=4.130221288078346)]),
RelationRecord(items=frozenset({'pasta', 'shrimp'}), support=0.005066666666666666, ordered_statistics=[OrderedStatistic(items_base=frozenset({'pasta'}), items_add=frozenset({'shrimp'}), confidence=0.3220338983050848, lift=4.514493901473151)])]
如我们所见,以上输出的格式不容易理解。因此,我们将以合适的格式打印所有规则。
- 以更清晰的方式可视化规则,支持,信心和提升:
for item in results:
pair = item[0]
items = [x for x in pair]
print("Rule: " + items[0] + " -> " + items[1])
print("Support: " + str(item[1]))
print("Confidence: " + str(item[2][0][2]))
print("Lift: " + str(item[2][0][3]))
print("=====================================")
输出:
通过执行以上代码行,我们将获得以下输出:
Rule: chicken -> light cream
Support: 0.004533333333333334
Confidence: 0.2905982905982906
Lift: 4.843304843304844
=====================================
Rule: escalope -> mushroom cream sauce
Support: 0.005733333333333333
Confidence: 0.30069930069930073
Lift: 3.7903273197390845
=====================================
Rule: escalope -> pasta
Support: 0.005866666666666667
Confidence: 0.37288135593220345
Lift: 4.700185158809287
=====================================
Rule: fromage blanc -> honey
Support: 0.0033333333333333335
Confidence: 0.2450980392156863
Lift: 5.178127589063795
=====================================
Rule: ground beef -> herb & pepper
Support: 0.016
Confidence: 0.3234501347708895
Lift: 3.2915549671393096
=====================================
Rule: tomato sauce -> ground beef
Support: 0.005333333333333333
Confidence: 0.37735849056603776
Lift: 3.840147461662528
=====================================
Rule: olive oil -> light cream
Support: 0.0032
Confidence: 0.20512820512820515
Lift: 3.120611639881417
=====================================
Rule: olive oil -> whole wheat pasta
Support: 0.008
Confidence: 0.2714932126696833
Lift: 4.130221288078346
=====================================
Rule: pasta -> shrimp
Support: 0.005066666666666666
Confidence: 0.3220338983050848
Lift: 4.514493901473151
=====================================
从上面的输出中,我们可以分析每个规则。第一条规则是“轻奶油→鸡肉”,规定大多数顾客经常购买轻奶油和鸡肉。该规则的支持度是0.0045,置信度是29%。因此,如果客户购买了淡奶油,那么他也购买鸡肉的可能性为29%,并且是交易中出现的.0045倍。我们也可以检查其他规则中的所有这些内容。