在Python中实现 Apriori 算法
先决条件:先验算法
Apriori 算法是一种机器学习算法,用于深入了解所涉及的不同项目之间的结构化关系。该算法最突出的实际应用是根据用户购物车中已经存在的产品推荐产品。沃尔玛尤其在向其用户推荐产品时充分利用了该算法。
数据集:杂货数据
Python中算法的实现:
第 1 步:导入所需的库
Python3
import numpy as np
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rulesPython3
# Changing the working location to the location of the file
cd C:\Users\Dev\Desktop\Kaggle\Apriori Algorithm
# Loading the Data
data = pd.read_excel('Online_Retail.xlsx')
data.head()Python3
# Exploring the columns of the data
data.columnsPython3
# Exploring the different regions of transactions
data.Country.unique()Python3
# Stripping extra spaces in the description
data['Description'] = data['Description'].str.strip()
# Dropping the rows without any invoice number
data.dropna(axis = 0, subset =['InvoiceNo'], inplace = True)
data['InvoiceNo'] = data['InvoiceNo'].astype('str')
# Dropping all transactions which were done on credit
data = data[~data['InvoiceNo'].str.contains('C')]Python3
# Transactions done in France
basket_France = (data[data['Country'] =="France"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
# Transactions done in the United Kingdom
basket_UK = (data[data['Country'] =="United Kingdom"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
# Transactions done in Portugal
basket_Por = (data[data['Country'] =="Portugal"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
basket_Sweden = (data[data['Country'] =="Sweden"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))Python3
# Defining the hot encoding function to make the data suitable
# for the concerned libraries
def hot_encode(x):
if(x<= 0):
return 0
if(x>= 1):
return 1
# Encoding the datasets
basket_encoded = basket_France.applymap(hot_encode)
basket_France = basket_encoded
basket_encoded = basket_UK.applymap(hot_encode)
basket_UK = basket_encoded
basket_encoded = basket_Por.applymap(hot_encode)
basket_Por = basket_encoded
basket_encoded = basket_Sweden.applymap(hot_encode)
basket_Sweden = basket_encodedPython3
# Building the model
frq_items = apriori(basket_France, min_support = 0.05, use_colnames = True)
# Collecting the inferred rules in a dataframe
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())Python3
frq_items = apriori(basket_UK, min_support = 0.01, use_colnames = True)
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())Python3
frq_items = apriori(basket_Por, min_support = 0.05, use_colnames = True)
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())Python3
frq_items = apriori(basket_Sweden, min_support = 0.05, use_colnames = True)
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())第 2 步:加载和探索数据
Python3
# Changing the working location to the location of the file
cd C:\Users\Dev\Desktop\Kaggle\Apriori Algorithm
# Loading the Data
data = pd.read_excel('Online_Retail.xlsx')
data.head()

Python3
# Exploring the columns of the data
data.columns

Python3
# Exploring the different regions of transactions
data.Country.unique()

第 3 步:清理数据
Python3
# Stripping extra spaces in the description
data['Description'] = data['Description'].str.strip()
# Dropping the rows without any invoice number
data.dropna(axis = 0, subset =['InvoiceNo'], inplace = True)
data['InvoiceNo'] = data['InvoiceNo'].astype('str')
# Dropping all transactions which were done on credit
data = data[~data['InvoiceNo'].str.contains('C')]
第四步:根据交易区域拆分数据
Python3
# Transactions done in France
basket_France = (data[data['Country'] =="France"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
# Transactions done in the United Kingdom
basket_UK = (data[data['Country'] =="United Kingdom"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
# Transactions done in Portugal
basket_Por = (data[data['Country'] =="Portugal"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
basket_Sweden = (data[data['Country'] =="Sweden"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
第 5 步:对数据进行热编码
Python3
# Defining the hot encoding function to make the data suitable
# for the concerned libraries
def hot_encode(x):
if(x<= 0):
return 0
if(x>= 1):
return 1
# Encoding the datasets
basket_encoded = basket_France.applymap(hot_encode)
basket_France = basket_encoded
basket_encoded = basket_UK.applymap(hot_encode)
basket_UK = basket_encoded
basket_encoded = basket_Por.applymap(hot_encode)
basket_Por = basket_encoded
basket_encoded = basket_Sweden.applymap(hot_encode)
basket_Sweden = basket_encoded
第 6 步:构建模型并分析结果
a)法国:
Python3
# Building the model
frq_items = apriori(basket_France, min_support = 0.05, use_colnames = True)
# Collecting the inferred rules in a dataframe
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())
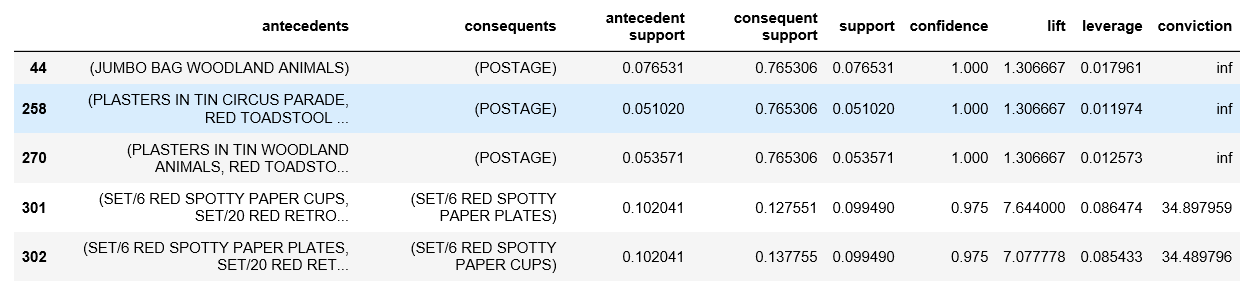
从上面的输出可以看出,纸杯和纸盘是在法国一起买的。这是因为法国人有一种文化,即每周至少与朋友和家人聚会一次。此外,由于法国政府已禁止在该国使用塑料,人们不得不购买纸质替代品。
b)英国:
Python3
frq_items = apriori(basket_UK, min_support = 0.01, use_colnames = True)
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())

如果再深入分析一下英国的交易规则,就会发现英国人一起购买不同颜色的茶盘。这背后的一个原因可能是因为英国人通常非常喜欢喝茶,并且经常为不同的场合收集不同颜色的茶盘。
c)葡萄牙:
Python3
frq_items = apriori(basket_Por, min_support = 0.05, use_colnames = True)
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())
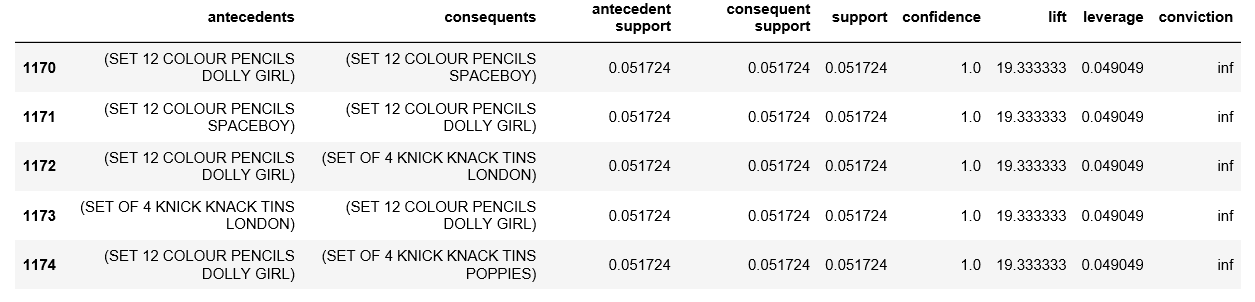
在分析葡萄牙交易的关联规则时,观察到 Tiffin 集 (Knick Knack Tins) 和彩色铅笔。这两种产品通常属于小学生。这两种产品是学校的孩子们分别用来携带午餐和进行创造性工作的必需品,因此在逻辑上将它们配对在一起是有意义的。
d)瑞典:
Python3
frq_items = apriori(basket_Sweden, min_support = 0.05, use_colnames = True)
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())

分析上述规则,发现男孩和女孩的餐具是搭配在一起的。这具有实际意义,因为当父母为他/她的孩子购买餐具时,他/她会希望根据孩子的意愿对产品进行一些定制。