使用 BeautifulSoup 解析表格和 XML
Perquisites:使用 Beautiful Soup 进行网页抓取、XML 解析
抓取是每个人都应该学习的一项非常重要的技能,它可以帮助我们从网站或文件中抓取数据,以便程序员以另一种漂亮的方式使用。在本文中,我们将学习如何从网站中提取表格以及如何从文件中提取 XML。
在这里,我们将使用 Beautiful Soup Python模块废弃数据。
所需模块:
- bs4: Beautiful Soup 是一个Python库,用于从 HTML 和 XML 文件中提取数据。可以使用以下命令安装它:
pip install bs4- lxml:它是一个Python库,允许我们处理 XML 和 HTML 文件。可以使用以下命令安装它:
pip install lxml- request: Requests 允许您非常轻松地发送 HTTP/1.1 请求。可以使用以下命令安装它:
pip install request解析表的分步方法:
步骤1:首先,我们需要导入模块,然后分配URL。
Python3
# import required modules
import bs4 as bs
import requests
# assign URL
URL = 'https://www.geeksforgeeks.org/python-list/'Python3
# parsing
url_link = requests.get(URL)
file = bs.BeautifulSoup(url_link.text, "lxml")Python3
# find all tables
find_table = file.find('table', class_='numpy-table')
rows = find_table.find_all('tr')Python3
# display tables
for i in rows:
table_data = i.find_all('td')
data = [j.text for j in table_data]
print(data)Python3
# import required modules
import bs4 as bs
import requests
# assign URL
URL = 'https://www.geeksforgeeks.org/python-list/'
# parsing
url_link = requests.get(URL)
file = bs.BeautifulSoup(url_link.text, "lxml")
# find all tables
find_table = file.find('table', class_='numpy-table')
rows = find_table.find_all('tr')
# display tables
for i in rows:
table_data = i.find_all('td')
data = [j.text for j in table_data]
print(data)Python3
# import required modules
from bs4 import BeautifulSoupPython3
# reading content
file = open("test1.xml", "r")
contents = file.read()Python3
# parsing
soup = BeautifulSoup(contents, 'xml')
titles = soup.find_all('title')Python3
# parsing
soup = BeautifulSoup(contents, 'xml')
titles = soup.find_all('title')Python3
# import required modules
from bs4 import BeautifulSoup
# reading content
file = open("test1.xml", "r")
contents = file.read()
# parsing
soup = BeautifulSoup(contents, 'xml')
titles = soup.find_all('title')
# display content
for data in titles:
print(data.get_text())第 2 步:创建一个BeautifulSoap对象进行解析。
蟒蛇3
# parsing
url_link = requests.get(URL)
file = bs.BeautifulSoup(url_link.text, "lxml")
第 3 步:然后找到表及其行。
蟒蛇3
# find all tables
find_table = file.find('table', class_='numpy-table')
rows = find_table.find_all('tr')
第 4 步:现在创建一个循环来查找表中的所有td标签,然后打印所有表数据标签。
蟒蛇3
# display tables
for i in rows:
table_data = i.find_all('td')
data = [j.text for j in table_data]
print(data)
以下是基于上述方法的完整程序:
蟒蛇3
# import required modules
import bs4 as bs
import requests
# assign URL
URL = 'https://www.geeksforgeeks.org/python-list/'
# parsing
url_link = requests.get(URL)
file = bs.BeautifulSoup(url_link.text, "lxml")
# find all tables
find_table = file.find('table', class_='numpy-table')
rows = find_table.find_all('tr')
# display tables
for i in rows:
table_data = i.find_all('td')
data = [j.text for j in table_data]
print(data)
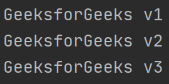
输出:

解析 XML 文件的分步方法:
第 1 步:在继续之前,您可以创建自己的“xml 文件”,也可以复制并粘贴以下代码,并将其命名为系统上的test1.xml文件。
Introduction of Geeksforgeeks V1
Gfg
6.99
Introduction of Geeksforgeeks V2
Gfg
8.99
Introduction of Geeksforgeeks V2
Gfg
9.35
第 2 步:创建一个Python文件并导入模块。
蟒蛇3
# import required modules
from bs4 import BeautifulSoup
第 3 步:读取 XML 的内容。
蟒蛇3
# reading content
file = open("test1.xml", "r")
contents = file.read()
第 4 步:解析 XML 的内容。
蟒蛇3
# parsing
soup = BeautifulSoup(contents, 'xml')
titles = soup.find_all('title')
步骤 5:显示 XML 文件的内容。
蟒蛇3
# parsing
soup = BeautifulSoup(contents, 'xml')
titles = soup.find_all('title')
以下是基于上述方法的完整程序:
蟒蛇3
# import required modules
from bs4 import BeautifulSoup
# reading content
file = open("test1.xml", "r")
contents = file.read()
# parsing
soup = BeautifulSoup(contents, 'xml')
titles = soup.find_all('title')
# display content
for data in titles:
print(data.get_text())
输出: