使用 BeautifulSoup 将 XML 结构转换为 DataFrame – Python
在这里,我们将使用Python的 BeautifulSoup 包将 XML 结构转换为 DataFrame。它是一个用于抓取网页的Python库。要安装这个库,命令是
pip install beautifulsoup4我们将使用此库从 XML 文件中提取数据,然后将提取的数据转换为 Dataframe。为了转换为数据帧,我们需要安装熊猫的库。
Pandas 库:它是一个用于数据操作和分析的Python库。要安装这个库,命令是
pip install pandas注意:如果它要求您安装解析器库,请使用命令
pip install et_xmlfile分步实施:
第 1 步:导入库。
Python3
from bs4 import BeautifulSoup
import pandas as pdPython3
file = open("gfg.xml",'r')
contents = file.read()Python3
soup = BeautifulSoup(contents,'xml')Python3
authors = soup.find_all('author')
titles = soup.find_all('title')
prices = soup.find_all('price')
pubdate = soup.find_all('publish_date')
genres = soup.find_all('genre')
des = soup.find_all('description')Python3
data = []
for i in range(0,len(authors)):
rows = [authors[i].get_text(),titles[i].get_text(),
genres[i].get_text(),prices[i].get_text(),
pubdate[i].get_text(),des[i].get_text()]
data.append(rows)Python3
df = pd.DataFrame(data,columns = ['Author','Book Title',
'Genre','Price','Publish Date',
'Description'], dtype = float)
display(df)Python3
# Python program to convert xml
# structure into dataframes using beautifulsoup
# Import libraries
from bs4 import BeautifulSoup
import pandas as pd
# Open XML file
file = open("gfg.xml", 'r')
# Read the contents of that file
contents = file.read()
soup = BeautifulSoup(contents, 'xml')
# Extracting the data
authors = soup.find_all('author')
titles = soup.find_all('title')
prices = soup.find_all('price')
pubdate = soup.find_all('publish_date')
genres = soup.find_all('genre')
des = soup.find_all('description')
data = []
# Loop to store the data in a list named 'data'
for i in range(0, len(authors)):
rows = [authors[i].get_text(), titles[i].get_text(), genres[i].get_text(
), prices[i].get_text(), pubdate[i].get_text(), des[i].get_text()]
data.append(rows)
# Converting the list into dataframe
df = pd.DataFrame(data, columns=['Author',
'Book Title', 'Genre',
'Price', 'Publish Date',
'Description'], dtype = float)
display(df)首先,我们需要导入将在我们的程序中使用的库。在这里,我们从 bs4 模块导入了 BeautifulSoup 库,还导入了 Pandas 库并将其别名创建为“pd”。
第二步:读取xml文件。
蟒蛇3
file = open("gfg.xml",'r')
contents = file.read()
在这里,我们在读取模式 'r' 下使用 open(“filename”, “mode”)函数打开名为 'gfg.xml' 的 xml 文件,并将其存储在变量 'file' 中。然后我们使用 read()函数读取存储在文件中的实际内容。
第 3 步:
蟒蛇3
soup = BeautifulSoup(contents,'xml')
在这里,我们将存储在 'contents' 变量中的要抓取的文件数据提供给 BeautifulSoup函数,并传递 XML 文件类型。
第 4 步:搜索数据。
在这里,我们正在提取数据。我们正在使用 find_all()函数,该函数返回在此函数传递的标记中存在的提取数据。
蟒蛇3
authors = soup.find_all('author')
titles = soup.find_all('title')
prices = soup.find_all('price')
pubdate = soup.find_all('publish_date')
genres = soup.find_all('genre')
des = soup.find_all('description')
例子:
authors = soup.find_all('author')我们将提取的数据存储到作者变量中。这个 find_all('author')函数将提取 xml 文件中 author 标签内的所有数据。数据将存储为列表,即authors 是从该xml 文件中的所有author 标签中提取的数据的列表。与其他声明相同。
第五步:从xml中获取文本数据。
蟒蛇3
data = []
for i in range(0,len(authors)):
rows = [authors[i].get_text(),titles[i].get_text(),
genres[i].get_text(),prices[i].get_text(),
pubdate[i].get_text(),des[i].get_text()]
data.append(rows)
现在,我们根据标签从各种列表中的 xml 文件中提取了所有数据。现在我们需要组合与来自不同列表的一本书相关的所有数据。因此,我们运行一个 for 循环,其中来自不同列表的特定书籍的所有数据都存储在一个名为“rows”的列表中,然后将每个这样的行附加到另一个名为“data”的列表中。
第 6 步:打印数据框。
最后,我们为每本书都有一个单独的组合数据。现在我们需要将此列表数据转换为 DataFrame。
蟒蛇3
df = pd.DataFrame(data,columns = ['Author','Book Title',
'Genre','Price','Publish Date',
'Description'], dtype = float)
display(df)
输出:
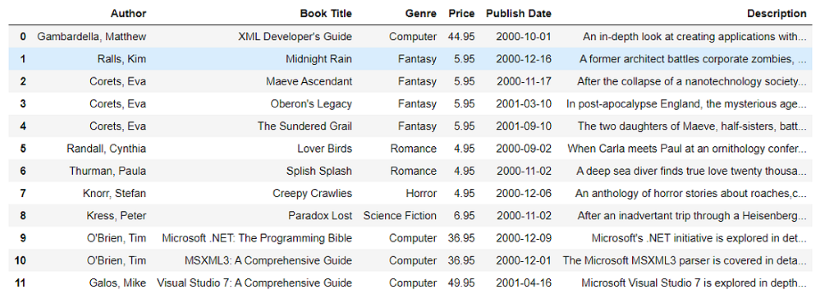
数据框
在这里,我们使用 pd.DataFrame() 命令将该数据列表转换为 Dataframe。在这个命令中,我们传递了列表 'data' 并传递了我们想要的列的名称。我们还提到了数据类型(dtype)作为浮点数,这将使所有数值浮点。
现在我们已经使用 BeautifulSoup 将 XML 文件中的数据提取到 DataFrame 中,并将其存储为“df”。要查看 DataFrame,我们使用 print 语句来打印它。
使用的 XML 文件 – GFG.xml
下面是完整的实现:
蟒蛇3
# Python program to convert xml
# structure into dataframes using beautifulsoup
# Import libraries
from bs4 import BeautifulSoup
import pandas as pd
# Open XML file
file = open("gfg.xml", 'r')
# Read the contents of that file
contents = file.read()
soup = BeautifulSoup(contents, 'xml')
# Extracting the data
authors = soup.find_all('author')
titles = soup.find_all('title')
prices = soup.find_all('price')
pubdate = soup.find_all('publish_date')
genres = soup.find_all('genre')
des = soup.find_all('description')
data = []
# Loop to store the data in a list named 'data'
for i in range(0, len(authors)):
rows = [authors[i].get_text(), titles[i].get_text(), genres[i].get_text(
), prices[i].get_text(), pubdate[i].get_text(), des[i].get_text()]
data.append(rows)
# Converting the list into dataframe
df = pd.DataFrame(data, columns=['Author',
'Book Title', 'Genre',
'Price', 'Publish Date',
'Description'], dtype = float)
display(df)
输出:
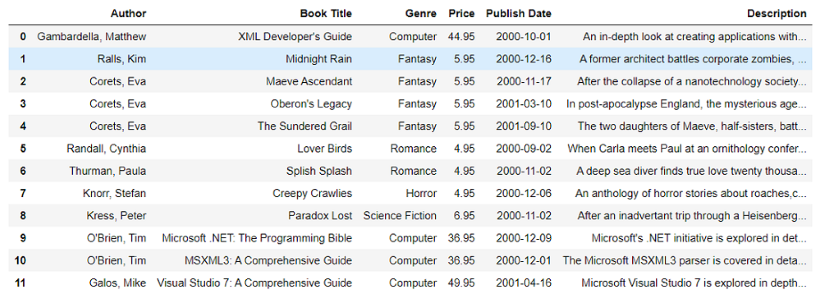
数据框