根据所有或选定的列在数据框中查找重复行
在本文中,我们将讨论如何根据所有列或列列表在 Dataframe 中查找重复行。为此,我们将使用 Pandas 的Dataframe.duplicated()方法。
Syntax : DataFrame.duplicated(subset = None, keep = ‘first’)
Parameters:
subset: This Takes a column or list of column label. It’s default value is None. After passing columns, it will consider them only for duplicates.
keep: This Controls how to consider duplicate value. It has only three distinct value and default is ‘first’.
- If ‘first’, This considers first value as unique and rest of the same values as duplicate.
- If ‘last’, This considers last value as unique and rest of the same values as duplicate.
- If ‘False’, This considers all of the same values as duplicates.
Returns: Boolean Series denoting duplicate rows.
让我们用一个列表字典创建一个简单的数据框,比如列名是:'Name'、'Age'和'City'。
Python3
# Import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Print the Dataframe
dfPython3
# Import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows except first
# occurrence based on all columns
duplicate = df[df.duplicated()]
print("Duplicate Rows :")
# Print the resultant Dataframe
duplicatePython3
# Import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows except last
# occurrence based on all columns.
duplicate = df[df.duplicated(keep = 'last')]
print("Duplicate Rows :")
# Print the resultant Dataframe
duplicatePython3
# import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows based
# on 'City' column
duplicate = df[df.duplicated('City')]
print("Duplicate Rows based on City :")
# Print the resultant Dataframe
duplicatePython3
# import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows based
# on list of column names
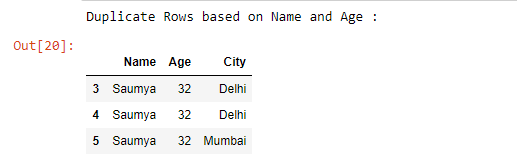
duplicate = df[df.duplicated(['Name', 'Age'])]
print("Duplicate Rows based on Name and Age :")
# Print the resultant Dataframe
duplicate输出 :

示例 1:根据所有列选择重复行。
在这里,我们不传递任何参数,因此,它采用两个参数的默认值,即子集 = None 和 keep = 'first'。
Python3
# Import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows except first
# occurrence based on all columns
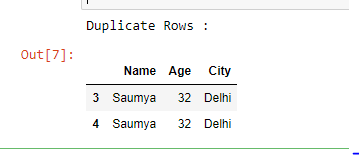
duplicate = df[df.duplicated()]
print("Duplicate Rows :")
# Print the resultant Dataframe
duplicate
输出 :
示例 2:根据所有列选择重复行。
如果您想考虑除最后一个之外的所有重复项,则将 keep = 'last' 作为参数传递。
Python3
# Import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows except last
# occurrence based on all columns.
duplicate = df[df.duplicated(keep = 'last')]
print("Duplicate Rows :")
# Print the resultant Dataframe
duplicate
输出 :

示例 3:如果您只想根据某些选定的列选择重复行,则将子集中的列名列表作为参数传递。
Python3
# import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows based
# on 'City' column
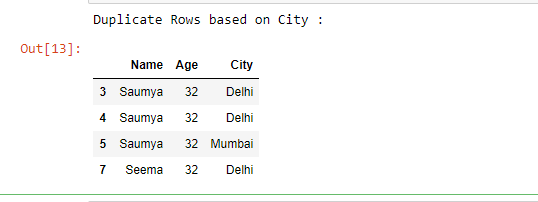
duplicate = df[df.duplicated('City')]
print("Duplicate Rows based on City :")
# Print the resultant Dataframe
duplicate
输出 :
示例 4:根据多个列名选择重复行。
Python3
# import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows based
# on list of column names
duplicate = df[df.duplicated(['Name', 'Age'])]
print("Duplicate Rows based on Name and Age :")
# Print the resultant Dataframe
duplicate
输出 :