使用 Pywedge 包的交互式图表
在机器学习和数据科学中,最艰巨的工作之一是理解原始数据并使其适合应用不同的模型来进行预测。出于理解目的,我们使用了不同的过程,例如检查统计数据,例如均值、中位数、众数,查找特征之间的关系,查看某些特征的分布等。这些通常都归入探索性数据分析术语中(EDA) 。根据经验丰富的 ML 和 DS 从业者的说法,EDA 是最有价值的任务之一,在分析数据集时其重要性不容忽视。它帮助从业者选择合适的数据预处理技术。
检查统计数字很好,但有什么比以图形方式可视化这些统计数据更好的,人们经常说图片是一种更强大的理解工具,而不仅仅是数字数字。我们可以通过制作不同的图表,在视觉上更清晰地理解数据。在机器学习和数据科学中,我们使用不同类型的图表/绘图来可视化特征中的不同模式,其中一些特征是:直方图、条形图、箱形图、配对图、饼图、小提琴图等。但是写作为所有这些图/图形手动编写代码似乎是一个累人的过程,而且我们更容易在代码中出现不准确和错误/错误。所以,这是我们的救星,一个Python包,它可以轻松有效地完成绘制这些图形的任务,而代码中没有任何此类错误。
在本文中,我们将阅读有关使用 pywedge Python包制作交互式绘图/图表的信息。 Pywedge 是一个开源Python包,可用于自动化大部分机器学习问题解决任务。它还为我们提供了使用几行代码绘制交互式图形的功能。
Pywedge 库有一个make_charts方法,它为我们提供了 8 种不同类型的图表,它们的名称如下:
- 散点图
- 饼形图
- 条形图
- 小提琴情节
- 箱形图
- 分布图
- 直方图
- 相关图
让我们看一个如何使用 pywedge 库绘制交互式绘图的示例:
导入库并加载数据集:
Python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("https://www.shortto.com/WineDataset",sep=";")Python
df.head()Python
print("Shape of our dataframe is: ",df.shape)Python
df.describe()Python
df.rename(columns={'ficxed acidity':'fixed_acidity','citric acid':'citric_acid',
'volatile acidity':'volatile_acidity','residual sugar':'residual_sugar',
'free sulphur dioxide':'free_sulphur_dioxide',
'total sulphur dioxide': 'total_sulphur_dioxide'},inplace=True)
# Splitting data into features and labels set
X = df.iloc[:,:11]
y = df.iloc[:,-1]Python
import pywedge as pw
charts = pw.Pywedge_Charts(df, c=None, y = 'quality')
# Calling the make_charts method
plots = charts.make_charts()加载数据集后,我们将查看数据集的外观,这可以使用 head 方法打印数据集中的前 5 行:
Python
df.head()

Python
print("Shape of our dataframe is: ",df.shape)
Shape of our dataframe is: (1599, 12)因此,我们可以注意到,数据集中共有 1599 行和 11 个特征以及一个名为“质量”的目标特征。
查看一些关于我们数据集的统计数据总是更好,我们可以使用 describe() 方法来做到这一点:
Python
df.describe()
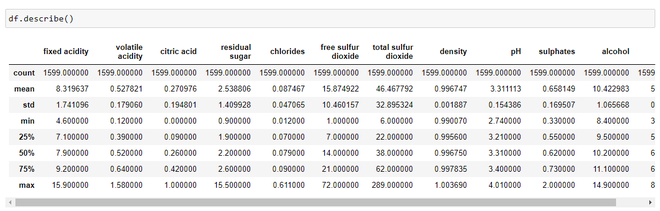
数据集统计
通过查看统计数据,我们可以推断
- 平均值大于每列中的中值,例如pH平均值为3.311113,而中值为3.310000。同样,酒精的平均值为 10.422,而中位数为 10.20。
- 我们可以注意到预测变量“残糖”、“游离二氧化硫”、“总二氧化硫”的第 75 个百分位值和最大值之间存在很大差异。这表明这 3 个变量的某些值与值的一般范围(最多 75% 平铺)相差甚远。因此,我们可以得出结论,我们的数据集中存在极端值,即异常值。
重命名列和拆分数据集:
Python
df.rename(columns={'ficxed acidity':'fixed_acidity','citric acid':'citric_acid',
'volatile acidity':'volatile_acidity','residual sugar':'residual_sugar',
'free sulphur dioxide':'free_sulphur_dioxide',
'total sulphur dioxide': 'total_sulphur_dioxide'},inplace=True)
# Splitting data into features and labels set
X = df.iloc[:,:11]
y = df.iloc[:,-1]
使用 Pywedge 库制作图表:
Python
import pywedge as pw
charts = pw.Pywedge_Charts(df, c=None, y = 'quality')
# Calling the make_charts method
plots = charts.make_charts()
'make_charts' 执行方法会产生一个窗口,为我们提供 8 种不同类型的图表选项,我们可以选择所需的特征来绘制图形并可视化结果。
制作散点图:
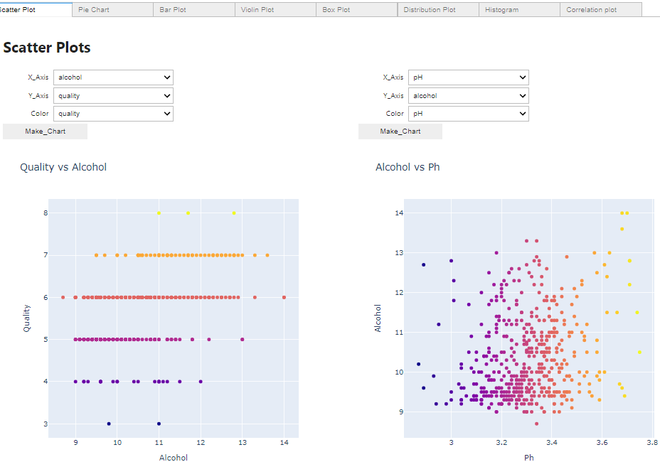
散点图
制作小提琴情节:
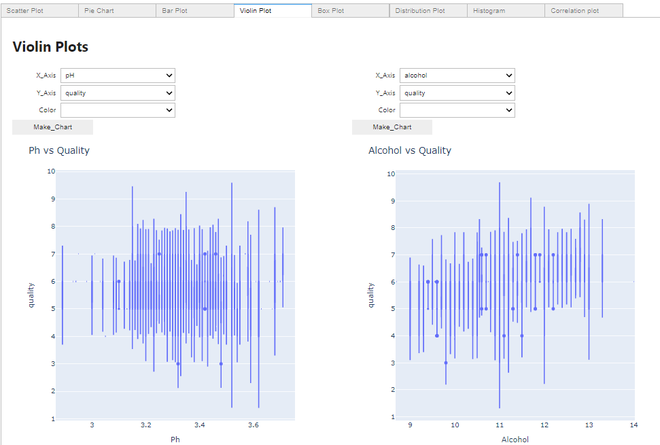
小提琴情节
制作分布图:
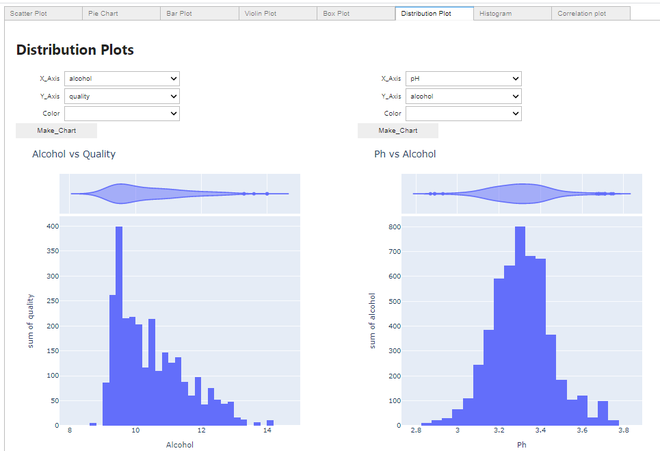
分布图
制作直方图:
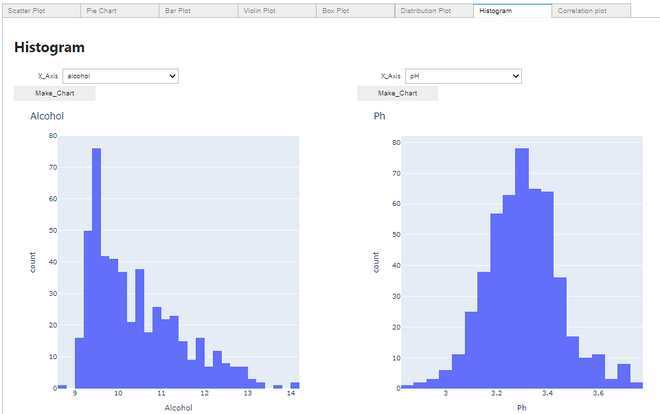
直方图
制作相关图:

相关图
因此,我们可以看到我们可以使用 pywedge 包仅使用几行代码来绘制这几个图的效率,而无需为所有这些图显式编写代码。