使用 Pandas 模块连接 CSV 文件
使用 pandas 我们可以对 CSV 文件执行各种操作,例如追加、更新、连接等。在本文中,我们将使用pandas模块连接两个 CSV 文件。
假设我们有一个名为Employee.csv的 .csv 文件,其中包含一些记录,如下所示:

员工.csv
还有另一个名为Updated.csv的 .csv 文件,其中包含新记录以及来自Employee.csv文件但具有更新信息的少数记录。该文件如下:
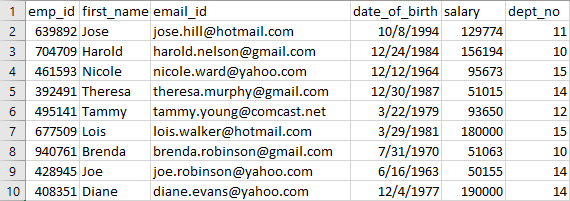
更新.csv
我们可以看到Updated.csv中的前 5 条记录是新的,其余的都有更新的信息。例如, Louis和Diane的工资改变了, Joe的email_id不同等等。
本文的目的是添加新记录并将现有记录的信息从Updated.csv文件更新到Employee.csv 。
注意:没有两个员工可以有相同的emp_id 。
方法:每当使用Python操作数据时,我们都会使用Dataframes 。已使用以下方法。
- 读取Employee.csv并创建一个数据框,例如, employee_df..
- 同样,读取 Updated.csv 并从数据帧中读取,例如updated_df 。
- 将updated_df连接到employee_df并使用emp_id作为主键删除重复项。
- 创建一个名为Updated_Employees.csv的新 .csv 文件,其中包含所有旧记录、新记录和更新记录。
示例 1:
Python3
#import pandas
import pandas as pd
# read Employee file
employee_df = pd.read_csv('Employee.csv')
# print employee records
print(employee_df)
# read Updated file
updated_df = pd.read_csv('Updated.csv')
# print updated records
print(updated_df)
# form new dataframe by combining both employee_df and updated_df
# concat method appends records of updated_df to employee_df
# drop_duplicates method drop rows having same emp_id keeping
# only the latest insertions
# resets the index to 0
final_dataframe = pd.concat([employee_df, updated_df]).drop_duplicates(
subset='emp_id', keep='last').reset_index(drop=True)
# print old,new and updates records
print(final_dataframe)
# export all records to a new csv file
final_dataframe.to_csv(
'Updated_Employees.csv', index=False)Python3
#import pandas
import pandas as pd
# read Employee file
df1 = pd.read_csv('gfg1.csv')
# print employee records
print('\ngfg1.csv:\n', df1)
# read Updated file
df2 = pd.read_csv('gfg2.csv')
# print updated records
print('\ngfg2.csv:\n', df2)
# form new dataframe by combining both employee_df
# and updated_df concat method appends records of
# updated_df to employee_df drop_duplicates method
# drop rows having same emp_id keeping only the
# latest insertions resets the index to 0
final_df = pd.concat([df1, df2]).drop_duplicates(
subset='ORGANIZATION').reset_index(drop=True)
# print old,new and updates records
print('\ngfg3.csv:\n', final_df)
# export all records to a new csv file
final_df.to_csv(
'gfg3.csv', index=False)输出:
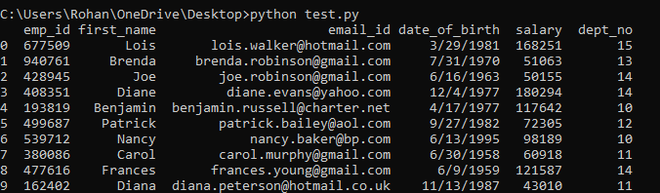
员工_df
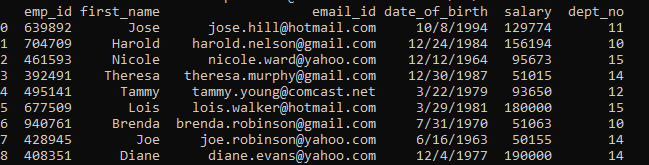
更新_df
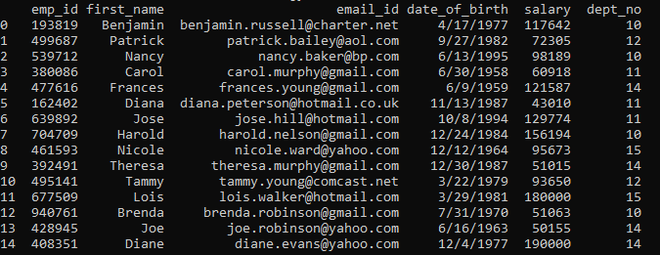
final_dataframe
下面是提供了Updated_Employee.csv的图像。
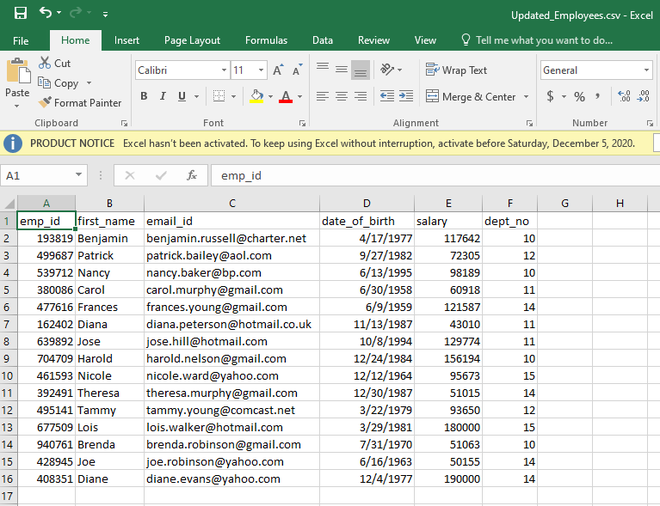
已更新_Employees.csv
例子:
以下是将要连接的两个 CSV 文件:
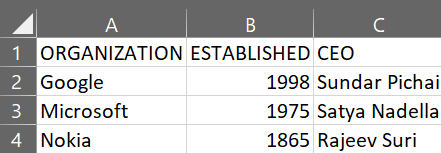
gfg3.csv
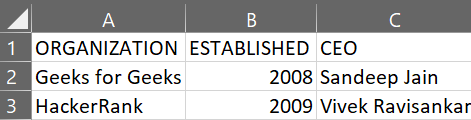
gfg2.csv
现在执行下面的程序来连接上面的 CSV 文件。
蟒蛇3
#import pandas
import pandas as pd
# read Employee file
df1 = pd.read_csv('gfg1.csv')
# print employee records
print('\ngfg1.csv:\n', df1)
# read Updated file
df2 = pd.read_csv('gfg2.csv')
# print updated records
print('\ngfg2.csv:\n', df2)
# form new dataframe by combining both employee_df
# and updated_df concat method appends records of
# updated_df to employee_df drop_duplicates method
# drop rows having same emp_id keeping only the
# latest insertions resets the index to 0
final_df = pd.concat([df1, df2]).drop_duplicates(
subset='ORGANIZATION').reset_index(drop=True)
# print old,new and updates records
print('\ngfg3.csv:\n', final_df)
# export all records to a new csv file
final_df.to_csv(
'gfg3.csv', index=False)
输出:
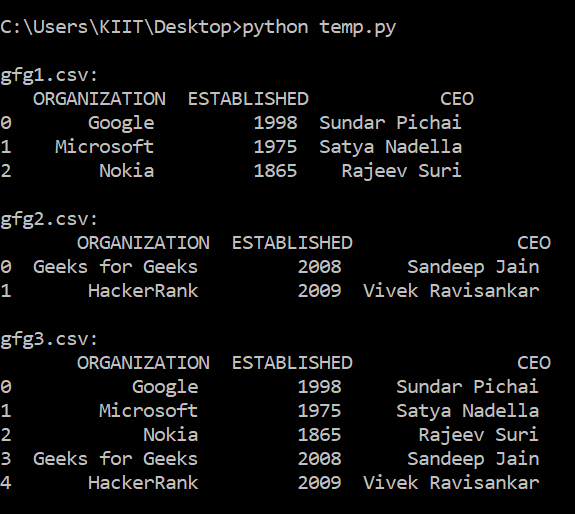
下面是gfg3.csv 的图像:
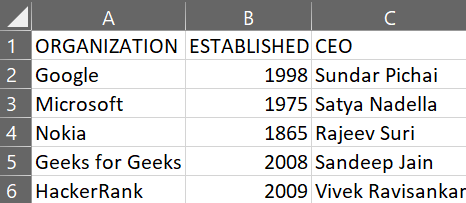
gfg3.csv