自然语言处理 |使用语料库阅读器进行分块
什么是块?
这些是由词组成的,词的种类是使用词性标签定义的。人们甚至可以定义不能成为chuck 一部分的模式或单词,这些单词被称为chinks。 ChunkRule 类指定要在块中包含和排除的单词或模式。
这个怎么运作 :
- ChunkedCorpusReader类的工作方式与 TaggedCorpusReader 类似,用于获取标记的令牌,此外它还提供了三种获取块的新方法。
- nltk.tree.Tree的一个实例代表每个块。
- 名词短语树看起来像 Tree('NP', [...]),而句子级别的树看起来像 Tree('S', [...])。
- 在 n chunked_sents() 中获得句子树列表,每个名词短语作为句子的子树
- 在 chunked_words() 中获得了名词短语树列表以及不在块中的单词的标记标记。
列出主要方法的图表:
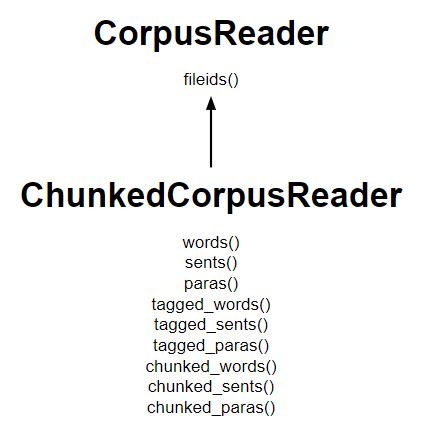
代码#1:为单词创建一个 ChunkedCorpusReader
Python3
# Using ChunkedCorpusReader
from nltk.corpus.reader import ChunkedCorpusReader
# initializing
x = ChunkedCorpusReader('.', r'.*\.chunk')
words = x.chunked_words()
print ("Words : \n", words)Python3
Chunked Sentence = x.chunked_sents()
print ("Chunked Sentence : \n", tagged_sent)Python3
para = x.chunked_paras()()
print ("para : \n", para)输出 :
Words :
[Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'),
('moves', 'NNS')]), ('have', 'VBP'), ...]代码#2:对于句子
Python3
Chunked Sentence = x.chunked_sents()
print ("Chunked Sentence : \n", tagged_sent)
输出 :
Chunked Sentence :
[Tree('S', [Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'),
('moves', 'NNS')]), ('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'),
Tree('NP', [('300', 'CD'), ('jobs', 'NNS')]), (', ', ', '),
Tree('NP', [('the', 'DT'), ('spokesman', 'NN')]), ('said', 'VBD'), ('.', '.')])]代码#3:对于段落
Python3
para = x.chunked_paras()()
print ("para : \n", para)
输出 :
[[Tree('S', [Tree('NP', [('Earlier', 'JJR'), ('staff-reduction',
'NN'), ('moves', 'NNS')]), ('have', 'VBP'), ('trimmed', 'VBN'),
('about', 'IN'),
Tree('NP', [('300', 'CD'), ('jobs', 'NNS')]), (', ', ', '),
Tree('NP', [('the', 'DT'), ('spokesman', 'NN')]), ('said', 'VBD'), ('.', '.')])]]