PySpark 数据框中的完全外连接
在本文中,我们将了解如何在Python中的 PySpark DataFrames 中执行完全外连接。
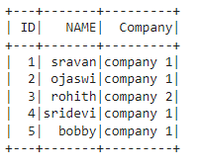
创建第一个数据框:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
dataframe.show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
dataframe1.show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# join two dataframes based on
# ID column using full keyword
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"full").show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# join two dataframes based on ID
# column using full outer keyword
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"fullouter").show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# join two dataframes based on
# ID column using outer keyword
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"outer").show()输出:
创建第二个数据框:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
dataframe1.show()
输出:

方法一:使用完整关键字
这用于使用 full 关键字将两个 PySpark 数据帧与所有行和列连接起来
Syntax: dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”full”).show()
where
- dataframe1 is the first PySpark dataframe
- dataframe2 is the second PySpark dataframe
- column_name is the column with respect to dataframe
示例:基于 ID 列连接两个数据框的Python程序。
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# join two dataframes based on
# ID column using full keyword
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"full").show()
输出:

方法2:使用fullouter关键字
这用于使用 fullouter 关键字将两个 PySpark 数据帧与所有行和列连接起来
Syntax: dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”fullouter”).show()
where
- dataframe1 is the first PySpark dataframe
- dataframe2 is the second PySpark dataframe
- column_name is the column with respect to dataframe
示例:基于 ID 列连接两个数据框的Python程序。
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# join two dataframes based on ID
# column using full outer keyword
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"fullouter").show()
输出:

方法3:使用outer关键字
这用于使用外部关键字将两个 PySpark 数据帧与所有行和列连接起来。
Syntax: dataframe1.join(dataframe2,dataframe1.column_name == dataframe2.column_name,”outer”).show()
where,
- dataframe1 is the first PySpark dataframe
- dataframe2 is the second PySpark dataframe
- column_name is the column with respect to dataframe
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# list of employee data
data1 = [["1", "45000", "IT"],
["2", "145000", "Manager"],
["6", "45000", "HR"],
["5", "34000", "Sales"]]
# specify column names
columns = ['ID', 'salary', 'department']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data1, columns)
# join two dataframes based on
# ID column using outer keyword
dataframe.join(dataframe1,
dataframe.ID == dataframe1.ID,
"outer").show()
输出:
