在 PySpark DataFrame 中将单列拆分为多列
pyspark.sql.functions提供了一个函数split() ,用于将 DataFrame字符串Column 拆分为多列。
Syntax: pyspark.sql.functions.split(str, pattern, limit=- 1)
Parameters:
- str: str is a Column or str to split.
- pattern: It is a str parameter, a string that represents a regular expression. This should be a Java regular expression.
- limit: It is an int parameter. Optional an integer value when specified controls the number of times the pattern is applied.
- limit > 0: The resulting array length must not be more than limit specified.
- limit <= 0: The pattern must be applied as many times as possible or till the limit.
首先让我们创建一个DataFrame。
Python3
# installing pyspark
!pip install pyspark
# importing pyspark
import pyspark
# importing SparkSession
from pyspark.sql import SparkSession
# importing all from pyspark.sql.function
from pyspark.sql.functions import *
# creating SparkSession object
spark=SparkSession.builder.appName("sparkdf").getOrCreate()
# creating the row data for dataframe
data = [('Jaya', 'Sinha', 'F', '1991-04-01'),
('Milan', 'Sharma', '', '2000-05-19'),
('Rohit', 'Verma', 'M', '1978-09-05'),
('Maria', 'Anne', 'F', '1967-12-01'),
('Jay', 'Mehta', 'M', '1980-02-17')
]
# giving the column names for the dataframe
columns = ['First Name', 'Last Name', 'Gender', 'DOB']
# creating the dataframe df
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()Python3
# split() function defining parameters
split_cols = pyspark.sql.functions.split(df['DOB'], '-')
# Now applying split() using withColumn()
df1 = df.withColumn('Year', split_cols.getItem(0)) \
.withColumn('Month', split_cols.getItem(1)) \
.withColumn('Day', split_cols.getItem(2))
# show df
df1.show()Python3
# defining split() along with withColumn()
df2 = df.withColumn('Year', split(df['DOB'], '-').getItem(0)) \
.withColumn('Month', split(df['DOB'], '-').getItem(1)) \
.withColumn('Day', split(df['DOB'], '-').getItem(2))
# show df2
df2.show()Python3
# creating the row data for dataframe
data = [('Jaya', 'Sinha', 'F', '1991-04-01'),
('Milan', 'Sharma', '', '2000-05-19'),
('Rohit', 'Verma', 'M', '1978-09-05'),
('Maria', 'Anne', 'F', '1967-12-01'),
('Jay', 'Mehta', 'M', '1980-02-17')
]
# giving the column names for the dataframe
columns = ['First Name', 'Last Name', 'DOB']
# creating the dataframe df
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()
# defining split ()
split_cols = pyspark.sql.functions.split(df['DOB'], '-')
# applying split() using select()
df3 = df.select('First Name', 'Last Name', 'Gender', 'DOB',
split_cols.getItem(0).alias('year'),
split_cols.getItem(1).alias('month'),
split_cols.getItem(2).alias('day'))
# show df3
df3.show()Python3
# creating the row data for dataframe
data = [('Jaya', 'Sinha'), ('Milan', 'Soni'),
('Rohit', 'Verma'), ('Maria', 'Anne'),
('Jay', 'Mehta')]
# giving the column names for the dataframe
columns = ['First Name', 'Last Name']
# creating the dataframe df
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()
# defining split()
split_cols = pyspark.sql.functions.split(df['Last Name'], '')
# applying split() using .withColumn()
df = df.withColumn('1', split_cols.getItem(0)) \
.withColumn('2', split_cols.getItem(1)) \
.withColumn('3', split_cols.getItem(2)) \
.withColumn('4', split_cols.getItem(3)) \
.withColumn('5', split_cols.getItem(4))
# show df
df.show()输出:

数据框已创建
示例 1:使用 withColumn() 拆分列
在此示例中,我们创建了一个简单的数据框,其中包含 yyyy-mm-dd字符串格式的出生日期列“DOB”。使用 split 和withColumn()将列拆分为年、月和日期列。
蟒蛇3
# split() function defining parameters
split_cols = pyspark.sql.functions.split(df['DOB'], '-')
# Now applying split() using withColumn()
df1 = df.withColumn('Year', split_cols.getItem(0)) \
.withColumn('Month', split_cols.getItem(1)) \
.withColumn('Day', split_cols.getItem(2))
# show df
df1.show()
输出:
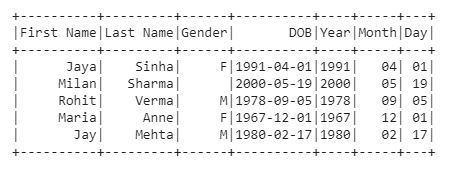
拆分列后的数据框
或者,我们也可以这样写,它会给出相同的输出:
蟒蛇3
# defining split() along with withColumn()
df2 = df.withColumn('Year', split(df['DOB'], '-').getItem(0)) \
.withColumn('Month', split(df['DOB'], '-').getItem(1)) \
.withColumn('Day', split(df['DOB'], '-').getItem(2))
# show df2
df2.show()
输出:

在上面的示例中,我们使用了 split() 的 2 个参数,即包含列名的“str”,“pattern”包含该列中存在的数据的模式类型,并从该位置拆分数据。
示例 2:使用 select() 拆分列
在此示例中,我们将使用相同的 DataFrame df 并使用 .select() 拆分其“DOB”列:
蟒蛇3
# creating the row data for dataframe
data = [('Jaya', 'Sinha', 'F', '1991-04-01'),
('Milan', 'Sharma', '', '2000-05-19'),
('Rohit', 'Verma', 'M', '1978-09-05'),
('Maria', 'Anne', 'F', '1967-12-01'),
('Jay', 'Mehta', 'M', '1980-02-17')
]
# giving the column names for the dataframe
columns = ['First Name', 'Last Name', 'DOB']
# creating the dataframe df
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()
# defining split ()
split_cols = pyspark.sql.functions.split(df['DOB'], '-')
# applying split() using select()
df3 = df.select('First Name', 'Last Name', 'Gender', 'DOB',
split_cols.getItem(0).alias('year'),
split_cols.getItem(1).alias('month'),
split_cols.getItem(2).alias('day'))
# show df3
df3.show()
输出:


在上面的例子中,我们没有在 select() 中选择 'Gender' 列,所以它在结果 df3 中不可见。
示例 3:拆分另一个字符串列
蟒蛇3
# creating the row data for dataframe
data = [('Jaya', 'Sinha'), ('Milan', 'Soni'),
('Rohit', 'Verma'), ('Maria', 'Anne'),
('Jay', 'Mehta')]
# giving the column names for the dataframe
columns = ['First Name', 'Last Name']
# creating the dataframe df
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()
# defining split()
split_cols = pyspark.sql.functions.split(df['Last Name'], '')
# applying split() using .withColumn()
df = df.withColumn('1', split_cols.getItem(0)) \
.withColumn('2', split_cols.getItem(1)) \
.withColumn('3', split_cols.getItem(2)) \
.withColumn('4', split_cols.getItem(3)) \
.withColumn('5', split_cols.getItem(4))
# show df
df.show()
输出:


在上面的示例中,我们只采用了 First Name 和 Last Name 两列,并将 Last Name 列值拆分为多个列中的单个字符。