使用 SQLite 在 SQLAlchemy 中返回不同的行
在本文中,我们将了解如何在 SQLAlchemy 中使用 SQLite 在Python中返回不同的行。
安装
SQLAlchemy 可通过 pip install 包获得。
pip install sqlalchemy但是,如果您使用的是烧瓶,您可以使用它自己的 SQLAlchemy 实现。它可以安装使用 -
pip install flask-sqlalchemy使用 SQLite 创建数据库和表
我们将使用 sqlite3 数据库。您可以从此链接下载数据库。将下载的文件解压缩到一个目录。之后,创建一个要处理的数据库。按照以下过程创建一个名为users的数据库:
- 打开命令提示符并指向sqlite.exe文件所在的目录。
- 使用命令sqlite3 users.db创建一个名为 users 的数据库
- 使用命令.databases检查创建的数据库
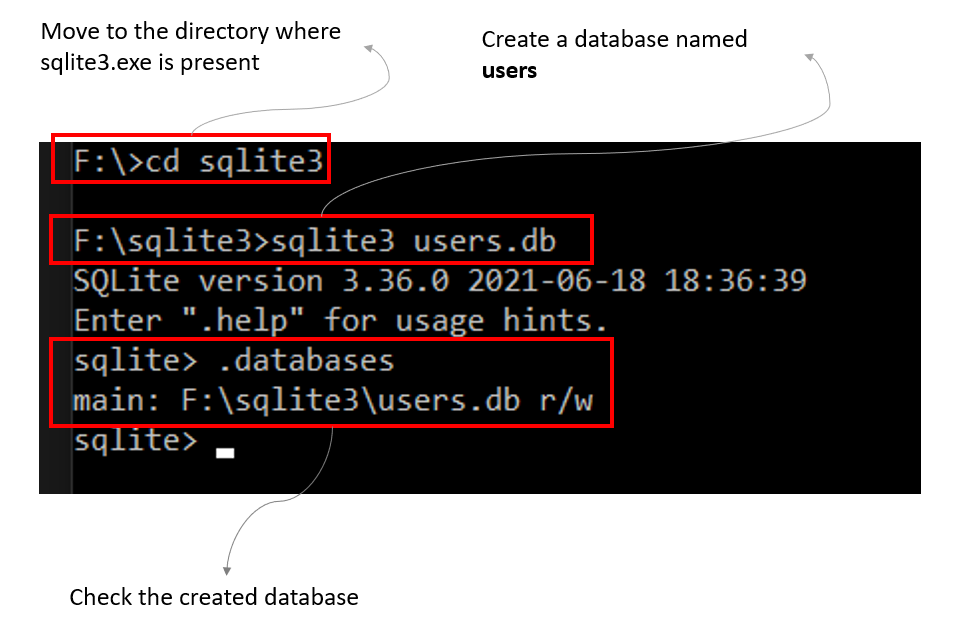
使用 sqlite3 创建数据库
在我们可以运行 SQLAlchemy 查询之前,我们需要一个数据库表和一些记录来处理。让我们创建一个名为 employees 的表并在其中插入一些值。原始 SQL 查询由下式给出:
CREATE TABLE employees (
emp_name VARCHAR(50),
emp_email VARCHAR(50),
emp_address VARCHAR(50)
);
INSERT INTO employees VALUES
('John', 'john.doe@email.com', 'Washington'),
('Sundar', 'spichai@eail.com', 'California'),
('Rahul', 'rahul@email.com', 'Mumbai'),
('Sonia', 'sonia@email.com', 'Mumbai'),
('Aisha', 'aisha@email.com', 'California');上述两个查询将创建employees表并在其中插入5 条记录。查询可以在 sqlite3 shell 中运行,如下所示 -
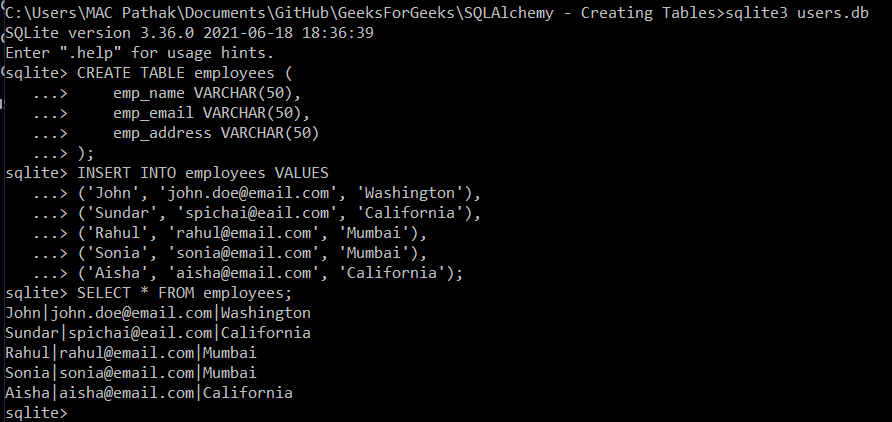
在 SQLite shell 中运行查询
使用 SQLAlchemy 获取不同的记录
现在,我们已经准备好表,因此我们可以编写 SQLAlchemy 代码来从表中提取不同的记录。我们将从employees表中为emp_address字段获取不同的(即唯一记录)。
Python
import sqlalchemy as db
# Define the Engine (Connection Object)
engine = db.create_engine("sqlite:///users.db")
# Create the Metadata Object
meta_data = db.MetaData(bind=engine)
db.MetaData.reflect(meta_data)
# Get the `employees` table from the Metadata object
EMPLOYEES = meta_data.tables['employees']
# SQLAlchemy Query to extract DISTINCT records
query = db.select([db.distinct(EMPLOYEES.c.emp_address)])
# Fetch all the records
result = engine.execute(query).fetchall()
# View the records
for record in result:
print("\n", record)输出:
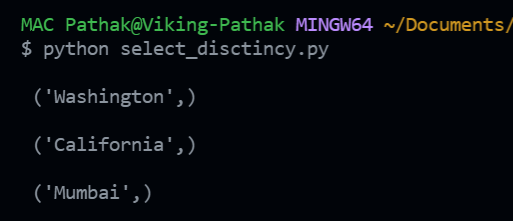
代码输出
解释:
- 首先,为简单起见,我们将 sqlalchemy 库导入为db 。所有 sqlalchemy 对象、方法等都将使用此db前缀导入,以更清晰。
- 然后我们创建引擎,它将作为与数据库的连接来执行所有数据库操作。
- 创建元数据对象。元数据对象“元数据”包含有关我们数据库的所有信息。
- 使用元数据信息从数据库中获取“员工”表。
- 我们现在可以编写一个 SQLAlchemy 查询来获取唯一记录。我们使用 SQLalchemy 的“distinct()”函数对emp_address字段执行 DISTINCT 操作,以检索相应字段中的唯一值集。
- 打印所有获取的记录。在输出中,我们可以看到我们只有 3 个不同的员工地址值。