用于情绪分析的微调 BERT 模型
Google 为自然语言处理预训练创建了一种基于 Transformer 的机器学习方法,称为来自 Transformers 的双向编码器表示。它有大量的参数,因此在一个小数据集上训练它会导致过度拟合。这就是为什么我们使用经过大量数据集训练的预训练 BERT 模型。使用预训练模型并尝试针对当前数据集“调整”它,即将学习从那个庞大的数据集转移到我们的数据集,以便我们可以从那时起“调整”BERT。
在本文中,我们将通过自己添加一些神经网络层并冻结 BERT 架构的实际层来微调 BERT。我们在这里采用的问题陈述是通过使用微调的 BERT 模型将句子分类为 POSITIVE 和 NEGATIVE。
准备数据集
数据集的链接。
句子列有文本,标签列有文本的情感——0 表示否定,1 表示肯定。我们首先加载数据集,然后在调整模型之前进行一些预处理。
加载数据集
Python
import pandas as pd
import numpy as np
df = pd.read_csv('/content/data.csv')Python
from sklearn.model_selection import train_test_split
train_text, temp_text, train_labels, temp_labels = train_test_split(df['sentence'], df['label'],
random_state = 2021,
test_size = 0.3,
stratify = df['label'])
val_text, test_text, val_labels, test_labels = train_test_split(temp_text, temp_labels,
random_state = 2021,
test_size = 0.5,
stratify = temp_labels)Python
#load model and tokenizer
bert = AutoModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')Python
train_lens = [len(i.split()) for i in train_text]
plt.hist(train_lens)Python
# tokenize and encode sequences
tokens_train = tokenizer.batch_encode_plus(
train_text.tolist(),
max_length = pad_len,
pad_to_max_length = True,
truncation = True
)
tokens_val = tokenizer.batch_encode_plus(
val_text.tolist(),
max_length = pad_len,
pad_to_max_length = True,
truncation = True
)
tokens_test = tokenizer.batch_encode_plus(
test_text.tolist(),
max_length = pad_len,
pad_to_max_length = True,
truncation = True
)
train_seq = torch.tensor(tokens_train['input_ids'])
train_mask = torch.tensor(tokens_train['attention_mask'])
train_y = torch.tensor(train_labels.tolist())
val_seq = torch.tensor(tokens_val['input_ids'])
val_mask = torch.tensor(tokens_val['attention_mask'])
val_y = torch.tensor(val_labels.tolist())
test_seq = torch.tensor(tokens_test['input_ids'])
test_mask = torch.tensor(tokens_test['attention_mask'])
test_y = torch.tensor(test_labels.tolist())Python
#freeze the pretrained layers
for param in bert.parameters():
param.requires_grad = False
#defining new layers
class BERT_architecture(nn.Module):
def __init__(self, bert):
super(BERT_architecture, self).__init__()
self.bert = bert
# dropout layer
self.dropout = nn.Dropout(0.2)
# relu activation function
self.relu = nn.ReLU()
# dense layer 1
self.fc1 = nn.Linear(768,512)
# dense layer 2 (Output layer)
self.fc2 = nn.Linear(512,2)
#softmax activation function
self.softmax = nn.LogSoftmax(dim=1)
#define the forward pass
def forward(self, sent_id, mask):
#pass the inputs to the model
_, cls_hs = self.bert(sent_id, attention_mask=mask, return_dict=False)
x = self.fc1(cls_hs)
x = self.relu(x)
x = self.dropout(x)
# output layer
x = self.fc2(x)
# apply softmax activation
x = self.softmax(x)
return xPython
optimizer = AdamW(model.parameters(),lr = 1e-5) # learning ratePython
# function to train the model
def train():
model.train()
total_loss, total_accuracy = 0, 0
# empty list to save model predictions
total_preds=[]
# iterate over batches
for step,batch in enumerate(train_dataloader):
# progress update after every 50 batches.
if step % 50 == 0 and not step == 0:
print(' Batch {:>5,} of {:>5,}.'.format(step, len(train_dataloader)))
# push the batch to gpu
batch = [r.to(device) for r in batch]
sent_id, mask, labels = batch
# clear previously calculated gradients
model.zero_grad()
# get model predictions for the current batch
preds = model(sent_id, mask)
# compute the loss between actual and predicted values
loss = cross_entropy(preds, labels)
# add on to the total loss
total_loss = total_loss + loss.item()
# backward pass to calculate the gradients
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# update parameters
optimizer.step()
# model predictions are stored on GPU. So, push it to CPU
preds=preds.detach().cpu().numpy()
# append the model predictions
total_preds.append(preds)
# compute the training loss of the epoch
avg_loss = total_loss / len(train_dataloader)
# predictions are in the form of (no. of batches, size of batch, no. of classes).
total_preds = np.concatenate(total_preds, axis=0)
#returns the loss and predictions
return avg_loss, total_predsPython
# code
print "GFG"
# function for evaluating the model
def evaluate():
print("\nEvaluating...")
# deactivate dropout layers
model.eval()
total_loss, total_accuracy = 0, 0
# empty list to save the model predictions
total_preds = []
# iterate over batches
for step,batch in enumerate(val_dataloader):
# Progress update every 50 batches.
if step % 50 == 0 and not step == 0:
# # Calculate elapsed time in minutes.
# elapsed = format_time(time.time() - t0)
# Report progress.
print(' Batch {:>5,} of {:>5,}.'.format(step, len(val_dataloader)))
# push the batch to gpu
batch = [t.to(device) for t in batch]
sent_id, mask, labels = batch
# deactivate autograd
with torch.no_grad():
# model predictions
preds = model(sent_id, mask)
# compute the validation loss between actual and predicted values
loss = cross_entropy(preds,labels)
total_loss = total_loss + loss.item()
preds = preds.detach().cpu().numpy()
total_preds.append(preds)
# compute the validation loss of the epoch
avg_loss = total_loss / len(val_dataloader)
# reshape the predictions in form of (number of samples, no. of classes)
total_preds = np.concatenate(total_preds, axis=0)
return avg_loss, total_predsPython
# get predictions for test data
with torch.no_grad():
preds = model(test_seq.to(device), test_mask.to(device))
preds = preds.detach().cpu().numpy()
from sklearn.metrics import classification_report
pred = np.argmax(preds, axis = 1)
print(classification_report(test_y, pred))拆分数据集:
加载数据后,将数据拆分为训练、验证和测试数据。我们为这个部门采用 70:15:15 的比例。下面使用 sklearn 的内置函数来拆分数据。我们使用分层属性来确保拆分数据后类别的比例保持不变。
Python
from sklearn.model_selection import train_test_split
train_text, temp_text, train_labels, temp_labels = train_test_split(df['sentence'], df['label'],
random_state = 2021,
test_size = 0.3,
stratify = df['label'])
val_text, test_text, val_labels, test_labels = train_test_split(temp_text, temp_labels,
random_state = 2021,
test_size = 0.5,
stratify = temp_labels)
加载预训练的 BERT 模型和分词器
接下来,我们继续加载预训练的 BERT 模型和标记器。我们将使用分词器将文本转换为可以发送到模型的格式(具有输入 ID、注意掩码)。
Python
#load model and tokenizer
bert = AutoModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
确定填充长度
如果我们将填充长度作为在训练文本中找到的最大文本长度,它可能会使训练数据变得稀疏。取最短的长度反过来会导致信息丢失。因此,我们将绘制图表并查看“平均”长度并将其设置为填充长度以在两个极端之间进行权衡。
Python
train_lens = [len(i.split()) for i in train_text]
plt.hist(train_lens)
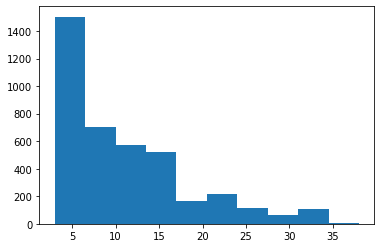
从上图中,我们将 17 作为填充长度。
标记数据
使用 BERT 分词器对数据进行分词并编码序列。
Python
# tokenize and encode sequences
tokens_train = tokenizer.batch_encode_plus(
train_text.tolist(),
max_length = pad_len,
pad_to_max_length = True,
truncation = True
)
tokens_val = tokenizer.batch_encode_plus(
val_text.tolist(),
max_length = pad_len,
pad_to_max_length = True,
truncation = True
)
tokens_test = tokenizer.batch_encode_plus(
test_text.tolist(),
max_length = pad_len,
pad_to_max_length = True,
truncation = True
)
train_seq = torch.tensor(tokens_train['input_ids'])
train_mask = torch.tensor(tokens_train['attention_mask'])
train_y = torch.tensor(train_labels.tolist())
val_seq = torch.tensor(tokens_val['input_ids'])
val_mask = torch.tensor(tokens_val['attention_mask'])
val_y = torch.tensor(val_labels.tolist())
test_seq = torch.tensor(tokens_test['input_ids'])
test_mask = torch.tensor(tokens_test['attention_mask'])
test_y = torch.tensor(test_labels.tolist())
定义模型
我们首先冻结 BERT 预训练模型,然后添加层,如以下代码片段所示:
Python
#freeze the pretrained layers
for param in bert.parameters():
param.requires_grad = False
#defining new layers
class BERT_architecture(nn.Module):
def __init__(self, bert):
super(BERT_architecture, self).__init__()
self.bert = bert
# dropout layer
self.dropout = nn.Dropout(0.2)
# relu activation function
self.relu = nn.ReLU()
# dense layer 1
self.fc1 = nn.Linear(768,512)
# dense layer 2 (Output layer)
self.fc2 = nn.Linear(512,2)
#softmax activation function
self.softmax = nn.LogSoftmax(dim=1)
#define the forward pass
def forward(self, sent_id, mask):
#pass the inputs to the model
_, cls_hs = self.bert(sent_id, attention_mask=mask, return_dict=False)
x = self.fc1(cls_hs)
x = self.relu(x)
x = self.dropout(x)
# output layer
x = self.fc2(x)
# apply softmax activation
x = self.softmax(x)
return x
此外,添加优化器以提高性能:
Python
optimizer = AdamW(model.parameters(),lr = 1e-5) # learning rate
然后计算类权重,并将它们作为参数发送,同时定义损失函数,以确保在计算损失时很好地处理数据集中的不平衡。
训练模型
定义模型后,定义一个函数来训练模型(在本例中为微调):
Python
# function to train the model
def train():
model.train()
total_loss, total_accuracy = 0, 0
# empty list to save model predictions
total_preds=[]
# iterate over batches
for step,batch in enumerate(train_dataloader):
# progress update after every 50 batches.
if step % 50 == 0 and not step == 0:
print(' Batch {:>5,} of {:>5,}.'.format(step, len(train_dataloader)))
# push the batch to gpu
batch = [r.to(device) for r in batch]
sent_id, mask, labels = batch
# clear previously calculated gradients
model.zero_grad()
# get model predictions for the current batch
preds = model(sent_id, mask)
# compute the loss between actual and predicted values
loss = cross_entropy(preds, labels)
# add on to the total loss
total_loss = total_loss + loss.item()
# backward pass to calculate the gradients
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# update parameters
optimizer.step()
# model predictions are stored on GPU. So, push it to CPU
preds=preds.detach().cpu().numpy()
# append the model predictions
total_preds.append(preds)
# compute the training loss of the epoch
avg_loss = total_loss / len(train_dataloader)
# predictions are in the form of (no. of batches, size of batch, no. of classes).
total_preds = np.concatenate(total_preds, axis=0)
#returns the loss and predictions
return avg_loss, total_preds
现在,定义另一个函数来评估验证数据上的模型。
Python
# code
print "GFG"
# function for evaluating the model
def evaluate():
print("\nEvaluating...")
# deactivate dropout layers
model.eval()
total_loss, total_accuracy = 0, 0
# empty list to save the model predictions
total_preds = []
# iterate over batches
for step,batch in enumerate(val_dataloader):
# Progress update every 50 batches.
if step % 50 == 0 and not step == 0:
# # Calculate elapsed time in minutes.
# elapsed = format_time(time.time() - t0)
# Report progress.
print(' Batch {:>5,} of {:>5,}.'.format(step, len(val_dataloader)))
# push the batch to gpu
batch = [t.to(device) for t in batch]
sent_id, mask, labels = batch
# deactivate autograd
with torch.no_grad():
# model predictions
preds = model(sent_id, mask)
# compute the validation loss between actual and predicted values
loss = cross_entropy(preds,labels)
total_loss = total_loss + loss.item()
preds = preds.detach().cpu().numpy()
total_preds.append(preds)
# compute the validation loss of the epoch
avg_loss = total_loss / len(val_dataloader)
# reshape the predictions in form of (number of samples, no. of classes)
total_preds = np.concatenate(total_preds, axis=0)
return avg_loss, total_preds
测试数据
对模型进行微调后,在测试数据集上对其进行测试。打印分类报告以更好地了解模型的性能。
Python
# get predictions for test data
with torch.no_grad():
preds = model(test_seq.to(device), test_mask.to(device))
preds = preds.detach().cpu().numpy()
from sklearn.metrics import classification_report
pred = np.argmax(preds, axis = 1)
print(classification_report(test_y, pred))
经过测试,我们会得到如下结果:
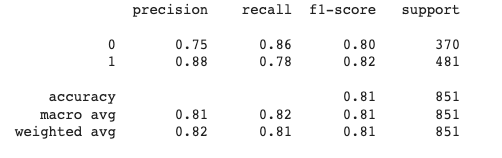
分类报告
链接到完整代码。
参考:
- https://huggingface.co/docs/transformers/model_doc/bert
- https://huggingface.co/docs/transformers/index
- https://huggingface.co/docs/transformers/custom_datasets