将 Pandas groupby 中的多列与字典相结合
让我们看看如何在不同示例的帮助下使用groupby和字典组合 Pandas 中的多个列。
示例 #1:
# importing pandas as pd
import pandas as pd
# Creating a dictionary
d = {'id':['1', '2', '3'],
'Column 1.1':[14, 15, 16],
'Column 1.2':[10, 10, 10],
'Column 1.3':[1, 4, 5],
'Column 2.1':[1, 2, 3],
'Column 2.2':[10, 10, 10], }
# Converting dictionary into a data-frame
df = pd.DataFrame(d)
print(df)
输出: 
# Creating the groupby dictionary
groupby_dict = {'Column 1.1':'Column 1',
'Column 1.2':'Column 1',
'Column 1.3':'Column 1',
'Column 2.1':'Column 2',
'Column 2.2':'Column 2' }
# Set the index of df as Column 'id'
df = df.set_index('id')
# Groupby the groupby_dict created above
df = df.groupby(groupby_dict, axis = 1).min()
print(df)
输出:

解释
- 在这里,我们将第 1.1 列、第 1.2 列和第 1.3 列分组到第 1 列,将第 2.1 列、第 2.2 列分组到第 2 列。
- 请注意,每列中的输出是组合在一起的列的每一行的最小值。即在第1列中,第一行的值是第1.1列第1行、第1.2列第1行和第1.3列第1行的最小值。
示例 #2:
# importing pandas as pd
import pandas as pd
# Create dictionary with data
dict = {
"ID":[1, 2, 3],
"Movies":["The Godfather", "Fight Club", "Casablanca"],
"Week_1_Viewers":[30, 30, 40],
"Week_2_Viewers":[60, 40, 80],
"Week_3_Viewers":[40, 20, 20] };
# Convert dictionary to dataframe
df = pd.DataFrame(dict);
print(df)
输出: 
# Create the groupby_dict
groupby_dict = {"Week_1_Viewers":"Total_Viewers",
"Week_2_Viewers":"Total_Viewers",
"Week_3_Viewers":"Total_Viewers",
"Movies":"Movies" }
df = df.set_index('ID')
df = df.groupby(groupby_dict, axis = 1).sum()
print(df)
输出: 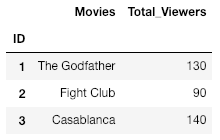
解释:
- 在这里,请注意,即使“电影”没有被合并到另一列中,它仍然必须存在于 groupby_dict 中,否则它不会出现在最终数据帧中。
- 为了计算 Total_Viewers,我们使用了 .sum()函数,该函数将相应行的所有值相加。