Java中的HashMap和TreeMap
HashMap 和 TreeMap 是集合框架的一部分。
Java.util.HashMap 类是一个基于散列的实现。在 HashMap 中,我们有一个键和一个值对
HashMap hmap = new HashMap(); 让我们考虑下面的示例,其中我们必须计算给定整数数组中每个整数的出现次数。
Input: arr[] = {10, 3, 5, 10, 3, 5, 10};
Output: Frequency of 10 is 3
Frequency of 3 is 2
Frequency of 5 is 2
/* Java program to print frequencies of all elements using
HashMap */
import java.util.*;
class Main
{
// This function prints frequencies of all elements
static void printFreq(int arr[])
{
// Creates an empty HashMap
HashMap hmap =
new HashMap();
// Traverse through the given array
for (int i = 0; i < arr.length; i++)
{
Integer c = hmap.get(arr[i]);
// If this is first occurrence of element
if (hmap.get(arr[i]) == null)
hmap.put(arr[i], 1);
// If elements already exists in hash map
else
hmap.put(arr[i], ++c);
}
// Print result
for (Map.Entry m:hmap.entrySet())
System.out.println("Frequency of " + m.getKey() +
" is " + m.getValue());
}
// Driver method to test above method
public static void main (String[] args)
{
int arr[] = {10, 34, 5, 10, 3, 5, 10};
printFreq(arr);
}
}
输出:
Frequency of 34 is 1
Frequency of 3 is 1
Frequency of 5 is 2
Frequency of 10 is 3关键点
- HashMap既不基于key也不基于value维护任何顺序,如果我们希望key保持有序,我们需要使用TreeMap。
- 复杂性:get/put/containsKey() 操作在平均情况下是 O(1),但我们不能保证,因为这完全取决于计算哈希所需的时间。
应用:
HashMap 基本上是散列的一种实现。因此,只要我们需要使用键值对进行散列,我们就可以使用 HashMap。例如,在 Web 应用程序中,用户名作为键存储,用户数据作为值存储在 HashMap 中,以便更快地检索与用户名对应的用户数据。
当我们只需要按排序顺序存储唯一元素时,TreeMap 可能会有点方便。 Java.util.TreeMap 在后台使用红黑树,确保没有重复;此外,它还按排序顺序维护元素。
TreeMap hmap = new TreeMap(); 下面是基于 TreeMap 的相同问题的实现。与具有 O(n) 的前一个解决方案相比,此解决方案具有更多的时间复杂度 O(nLogn)。这种方法的优点是,我们按排序顺序获取元素。
/* Java program to print frequencies of all elements using
TreeMap */
import java.util.*;
class Main
{
// This function prints frequencies of all elements
static void printFreq(int arr[])
{
// Creates an empty TreeMap
TreeMap tmap =
new TreeMap();
// Traverse through the given array
for (int i = 0; i < arr.length; i++)
{
Integer c = tmap.get(arr[i]);
// If this is first occurrence of element
if (tmap.get(arr[i]) == null)
tmap.put(arr[i], 1);
// If elements already exists in hash map
else
tmap.put(arr[i], ++c);
}
// Print result
for (Map.Entry m:tmap.entrySet())
System.out.println("Frequency of " + m.getKey() +
" is " + m.getValue());
}
// Driver method to test above method
public static void main (String[] args)
{
int arr[] = {10, 34, 5, 10, 3, 5, 10};
printFreq(arr);
}
}
输出:
Frequency of 3 is 1
Frequency of 5 is 2
Frequency of 10 is 3
Frequency of 34 is 1关键点
- 对于添加、删除、包含键等操作,时间复杂度为 O(log n 其中 n 是 TreeMap 中存在的元素数。
- TreeMap 总是保持元素的排序(递增)顺序,而 HashMap 中的元素没有顺序。 TreeMap 还为键的 first、last、floor 和 ceiling 提供了一些很酷的方法。
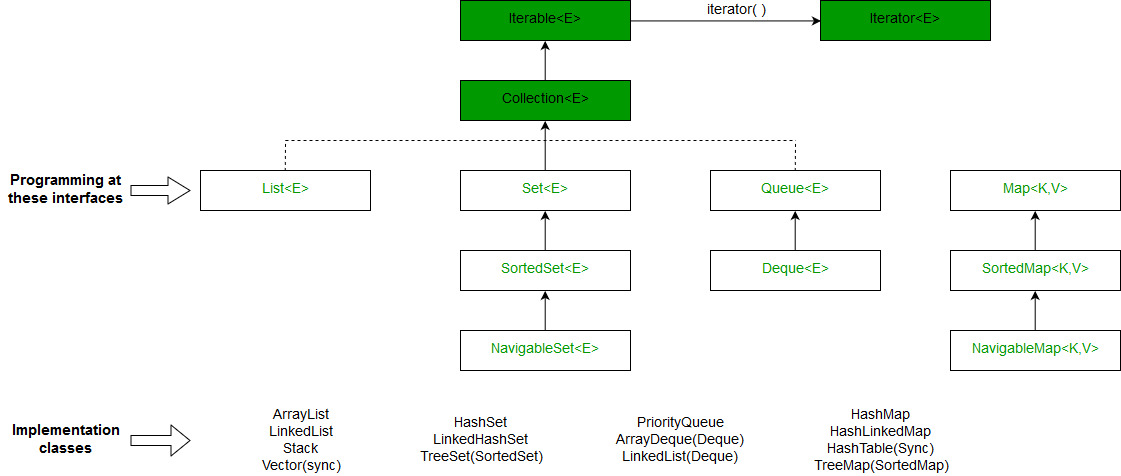
- HashMap 实现 Map 接口,而 TreeMap 实现 SortedMap 接口。 Sorted Map 接口是 Map 的子接口。
- HashMap 实现了 Hashing,而 TreeMap 实现了红黑树(一种自平衡二叉搜索树)。因此,哈希和平衡二叉搜索树之间的所有差异都适用于此。
- HashMap 和 TreeMap 都有对应的 HashSet 和 TreeSet。 HashSet 和 TreeSet 实现了 Set 接口。在 HashSet 和 TreeSet 中,我们只有 key,没有 value,这些主要用于查看集合中的存在/不存在。对于上述问题,我们不能使用 HashSet(或 TreeSet),因为我们不能存储计数。我们更喜欢 HashSet(或 TreeSet)而不是 HashMap(或 TreeMap)的一个示例问题是打印数组中的所有不同元素。
相关文章
- Java中的LinkedHashmap
- Java中TreeMap、HashMap和LinkedHashMap的区别
- Java中HashMap和HashTable的区别
参考 :
https://docs.oracle.com/javase/7/docs/api/java Java