使用Python导出 PDF 数据
有时,我们必须从 PDF 中提取数据。我们必须从 PDF 复制和粘贴数据。这很耗时。在Python中,我们可以使用一些包从 PDF 中提取数据并使用Python将其导出为不同的格式。我们将学习如何从 PDF 中提取数据。
使用 PDFMiner 提取文本
PDFMiner是一个 PDF 文档的文本提取工具。您可以尝试使用 pip 在您的系统中安装 PDFminer,如下所示:
pip install pdfminer让我们开始逐页提取 PDF 的所有文本。它需要以下步骤来提取页面数据
- 创建资源管理器实例。
- 通过 Python 的 io 模块创建一个类似文件的对象。
- 创建一个转换器。
- 创建一个 PDF 解释器对象,它将获取我们的资源管理器和转换器对象并提取文本。
- 打开 PDF 并循环浏览每一页。
下面是实现。
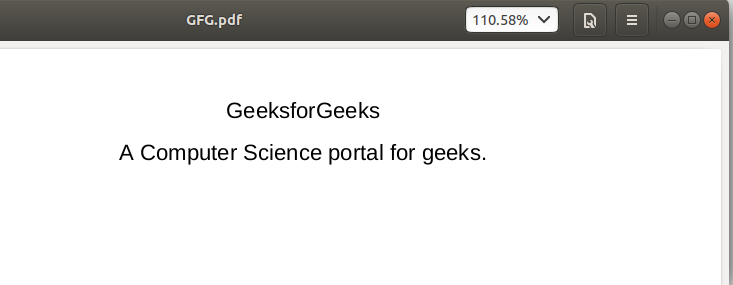
使用的 PDF 文件:
import io
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfpage import PDFPage
def extract_text_by_page(pdf_path):
with open(pdf_path, 'rb') as fh:
for page in PDFPage.get_pages(fh,
caching=True,
check_extractable=True):
resource_manager = PDFResourceManager()
fake_file_handle = io.StringIO()
converter = TextConverter(resource_manager,
fake_file_handle)
page_interpreter = PDFPageInterpreter(resource_manager,
converter)
page_interpreter.process_page(page)
text = fake_file_handle.getvalue()
yield text
# close open handles
converter.close()
fake_file_handle.close()
def extract_text(pdf_path):
for page in extract_text_by_page(pdf_path):
print(page)
print()
# Driver code
if __name__ == '__main__':
print(extract_text('GFG.pdf'))
输出:

在这个例子中,我们创建了一个函数来为每个页面生成文本。 extract_text函数打印出每一页的文本。