Python的功率分析简介
要了解什么是功效分析,我们必须首先了解统计假设检验的概念。统计假设检验计算给定假设(零假设)下的某个数量,检验结果使我们能够解释假设是否有效或假设是否被违反。对检验假设的违反通常称为第一个假设或替代假设。 p 值和临界值是统计检验最常见的结果,可以用不同的方式解释。
将p 值与显着性水平进行比较,  (在实验前指定,其值取决于实验类型和业务需求)。典型的显着性水平测量值为 0.10 或 10%、0.05 或 5% 以及 0.01 或 1%。
(在实验前指定,其值取决于实验类型和业务需求)。典型的显着性水平测量值为 0.10 或 10%、0.05 或 5% 以及 0.01 或 1%。
- 如果 p 值 <=
 :拒绝零假设(显着结果)。
:拒绝零假设(显着结果)。 - 如果 p 值 >
 :未能拒绝原假设(结果不显着)。
:未能拒绝原假设(结果不显着)。
所有统计假设检验都有可能出现以下任一类型的错误:
- I 型错误:错误拒绝真零假设或假阳性。
- 第二类错误:错误地接受了错误的零假设或错误的否定。
统计功效:仅当原假设为假时才相关。假设检验的统计功效是正确拒绝零假设的概率或接受替代假设(如果为真)的可能性。因此,给定测试的统计功效越高,产生 II 类(假阴性)错误的概率就越低。
在进行统计功效分析之前,您需要了解的最后一个概念是效应大小。它是实验群体中存在的结果或效应的量化幅度,通常通过特定的统计量度来衡量,例如 Pearson 相关性或 Cohen's d 来衡量两组平均值的差异。 Cohen d 的普遍接受的小、中、大和非常大的效应大小分别为 0.20、0.50、0.80 和 1.3。效果大小或“预期效果”是从试点研究、类似研究的结果、领域定义的效果或有根据的猜测确定的。
功效分析:它由 4 个变量构建而成,即效应量、显着性水平、功效、样本量。所有这些变量都是相互关联的,改变其中一个变量会影响其他三个变量。按照这种关系,功效分析涉及在其他三个变量已知时确定第四个变量。它是实验设计的有力工具。例如,在实验之前,可以在给定不同的所需显着性水平、效果大小和功效的情况下估计检测特定效果所需的样本大小。或者,可以验证一项研究的结果。通过使用给定的样本量、效应量和显着性水平,可以确定统计功效,从而有助于从决策的角度确定犯第二类错误的概率是否可接受。
使用Python功耗分析
这 Python中statsmodels包的stats.power模块包含对最常用的统计检验(如 t 检验、正态检验、F 检验和卡方拟合优度检验)进行功效分析所需的函数。它的solve_power函数将上述 4 个变量中的 3 个作为输入参数,并计算剩余的第 4 个变量。
考虑学生的 t 检验,这是一种统计假设检验,用于比较两个高斯变量样本的均值。在对两组变量的初步研究中,N1 = 4,Mean1 = 90,SD1 = 5; N2 = 4, Mean2 = 85, SD2 = 5。检验的假设或原假设是样本总体具有相同的均值。由于 alpha 通常设置为 0.05,功效为 0.80,因此研究人员主要需要关注样本量和效应量。让我们确定所需的试验,其中的80%的功率是可以接受的,与在5%显着性水平和预期的效果大小的样本大小,以使用导频研究中找到。
示例 1:
首先,导入相关库。使用 Cohen's d 计算效果大小。 TTestIndPower函数为两个独立样本的 t 检验实现统计函数计算。类似地,还有用于 F 检验、Z 检验和卡方检验的函数。接下来,初始化用于功效分析的变量。然后使用 solve_power函数,我们可以获得所需的缺失变量,即本例中的样本大小。
代码:
Python
# import required modules
from math import sqrt
from statsmodels.stats.power import TTestIndPower
#calculation of effect size
# size of samples in pilot study
n1, n2 = 4, 4
# variance of samples in pilot study
s1, s2 = 5**2, 5**2
# calculate the pooled standard deviation
# (Cohen's d)
s = sqrt(((n1 - 1) * s1 + (n2 - 1) * s2) / (n1 + n2 - 2))
# means of the samples
u1, u2 = 90, 85
# calculate the effect size
d = (u1 - u2) / s
print(f'Effect size: {d}')
# factors for power analysis
alpha = 0.05
power = 0.8
# perform power analysis to find sample size
# for given effect
obj = TTestIndPower()
n = obj.solve_power(effect_size=d, alpha=alpha, power=power,
ratio=1, alternative='two-sided')
print('Sample size/Number needed in each group: {:.3f}'.format(n))Python
from statsmodels.stats.power import TTestPower
power = TTestPower()
n_test = power.solve_power(nobs=40, effect_size = 0.5,
power = None, alpha = 0.05)
print('Power: {:.3f}'.format(n_test))Python
# import required libraries
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.stats.power import TTestIndPower
# power analysis varying parameters
effect_sizes = np.array([0.2, 0.5, 0.8,1.3])
sample_sizes = np.array(range(5, 100))
# plot power curves
obj = TTestIndPower()
obj.plot_power(dep_var='nobs', nobs=sample_sizes,
effect_size=effect_sizes)
plt.show()输出:
Effect size: 1.0
Sample size/Number needed in each group: 16.715因此,建议的每组中所需的最小样本数为 17,以便在 t 检验中具有显着的 p 值。如果我们在功效分析之前继续并使用推论 t 检验,我们可能会发现一个不显着的 p 值,即使有很大的影响,可能是由于样本量较小 (4)。
示例 2:
或者,我们可以测试特定建议样本量的功效。
代码:
Python
from statsmodels.stats.power import TTestPower
power = TTestPower()
n_test = power.solve_power(nobs=40, effect_size = 0.5,
power = None, alpha = 0.05)
print('Power: {:.3f}'.format(n_test))
输出:
Power: 0.869这告诉我们,最小样本量为 40 将产生 0.87 的功效。
示例 3:
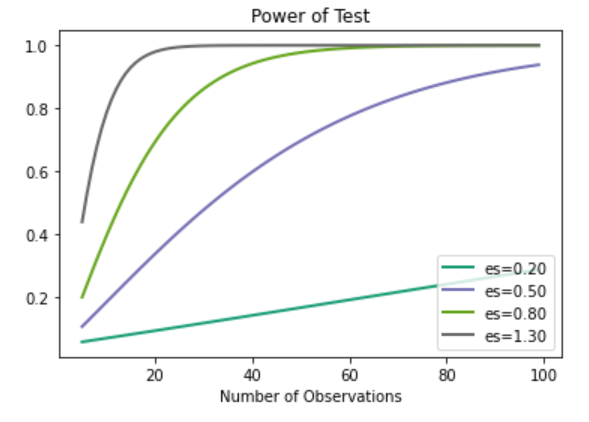
我们还可以绘制功率曲线。功效曲线是显示效应量和样本量的变化如何影响统计检验功效的线图。 plot_power()函数可用于创建功率曲线。 'dep_var' 参数指定因变量(x 轴),可以是 'nobs'、'effect_size' 或 'alpha'。此处,'nobs' 是样本大小并采用数组值。因此,为每个效应量值创建一条曲线。
让我们假设显着性水平为 0.05,并使用 Cohen d 标准低、中和高效应量探索样本量在 5 到 100 之间的变化。
代码:
Python
# import required libraries
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.stats.power import TTestIndPower
# power analysis varying parameters
effect_sizes = np.array([0.2, 0.5, 0.8,1.3])
sample_sizes = np.array(range(5, 100))
# plot power curves
obj = TTestIndPower()
obj.plot_power(dep_var='nobs', nobs=sample_sizes,
effect_size=effect_sizes)
plt.show()
输出: