在 Pandas 中没有聚合的 Groupby
Pandas 是一个很棒的用于操作数据的Python包,我们作为初学者学习的一些工具是 Pandas 的聚合和按功能分组。
通过...分组() 是用于在数据帧中的数据分割成基于给定的条件组的函数。另一方面,聚合对系列、数据进行操作并返回数据的数字摘要。有很多聚合函数,如count(),max(),min(),mean(),std(),describe() 。我们可以结合这两个函数来查找特定列上的多个聚合。有关更多详细信息,请参阅本文如何在 Pandas 中组合 Groupby 和多聚合函数。
我们可以不使用 groupby 聚合,而不是一起使用 groupby 聚合,这适用于单独聚合数据。我们将通过一个示例来了解这一点,其中我们将采用具有不同数值特征(如平均面积、最差纹理等)的乳腺癌数据集。目标列有 0 表示癌症是良性的,1 表示癌症是恶性的。
示例 1:
Python3
# importing python libraries and breast_cancer dataset from sklearn
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.datasets import load_breast_cancer
# data is loaded in a DataFrame
cancer_data = load_breast_cancer()
df = pd.DataFrame(cancer_data.data, columns=cancer_data.feature_names)
df['target'] = pd.Series(cancer_data.target)
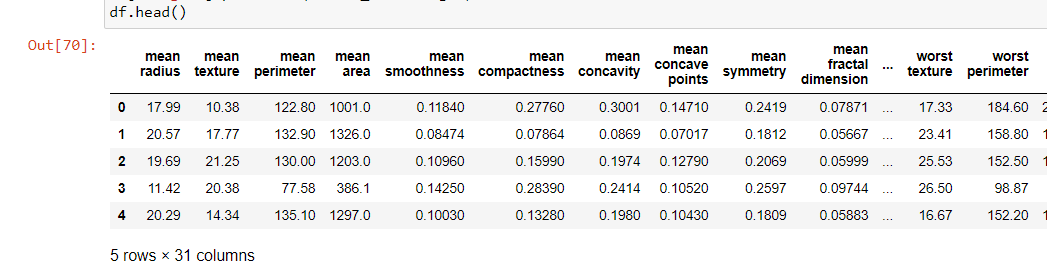
df.head()Python3
print(df['target'].describe(), df['worst texture'].describe())Python3
df1 = df[['worst texture', 'worst area', 'target']]
gr1 = df1.groupby(df1['target']).mean()
gr1Python3
# function to take the data as group and perform aggregation
def meanofTargets(group1):
wt = group1['worst texture'].agg('mean')
wa = group1['worst area'].agg('mean')
group1['Mean worst texture'] = wt
group1['Mean worst area'] = wa
return group1
df2 = df1.groupby('target').apply(meanofTargets)
df2Python3
# dataframe df_3 to contain only mean_area,Cat_mean_area and target
df_3 = df_2[['mean area', 'Cat_mean_area', 'target']]
# applying groupby sum
gr2 = df_3.groupby(df_2['Cat_mean_area']).sum()
gr2Python3
# function to take the data as group and perform aggregation
def totalTargets(group):
g = group['target'].agg('sum')
group['Total_targets'] = g
return group
df_4 = df_3.groupby(df_3['Cat_mean_area']).apply(totalTargets)
df_4输出:
因此,我们可以可视化包含所有列的数据,但所有列都是数字形式,并且没有分类数据而只有目标列,所以让我们看看目标和另一列名为“最坏纹理”的列。
蟒蛇3
print(df['target'].describe(), df['worst texture'].describe())
输出:
count 569.000000
mean 0.627417
std 0.483918
min 0.000000
25% 0.000000
50% 1.000000
75% 1.000000
max 1.000000
Name: target, dtype: float64
count 569.000000
mean 25.677223
std 6.146258
min 12.020000
25% 21.080000
50% 25.410000
75% 29.720000
max 49.540000
Name: worst texture, dtype: float64在这里我们可以看到目标和最坏纹理列的摘要,我们只使用这些列来更好地理解 groupby 聚合函数。
蟒蛇3
df1 = df[['worst texture', 'worst area', 'target']]
gr1 = df1.groupby(df1['target']).mean()
gr1
输出:
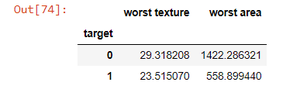
所以这里我们看到了围绕良性和恶性癌症分组的最坏纹理和最坏区域的平均值,现在正常数据已经被这种方法干扰了,我们必须单独添加它们,这就是为什么没有聚合的groupby变得方便。
蟒蛇3
# function to take the data as group and perform aggregation
def meanofTargets(group1):
wt = group1['worst texture'].agg('mean')
wa = group1['worst area'].agg('mean')
group1['Mean worst texture'] = wt
group1['Mean worst area'] = wa
return group1
df2 = df1.groupby('target').apply(meanofTargets)
df2
输出:
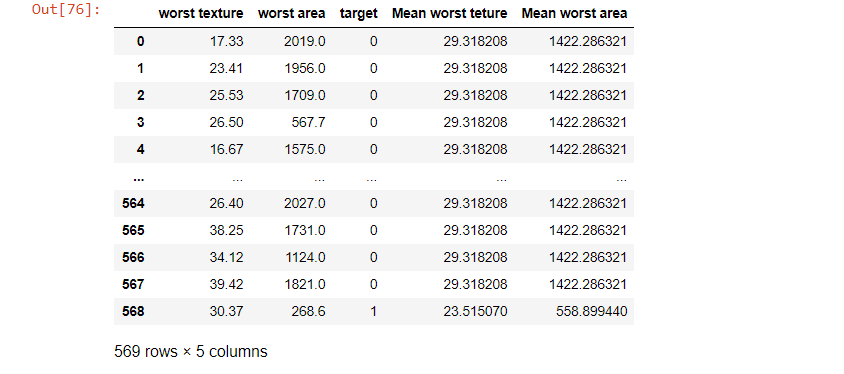
因此,在上面的数据集中,我们可以将最差区域和最差纹理的平均值加入单独的列中,并且我们使用目标列的 groupby 方法将'1'和 0'分开分组。
示例 2:
同样,让我们看另一个使用 groupby 而不使用聚合的示例。但是由于没有分类栏,我们将不得不自己制作分类栏。为此,让我们选择最大值为 2500 和最小值为 150 的平均区域,因此我们将使用 pandas cut 方法将它们分为范围为 400 的 6 组,将连续转换为分类。由于这与本文主题无关,请参阅此处的 GitHub 存储库以获取更多信息。
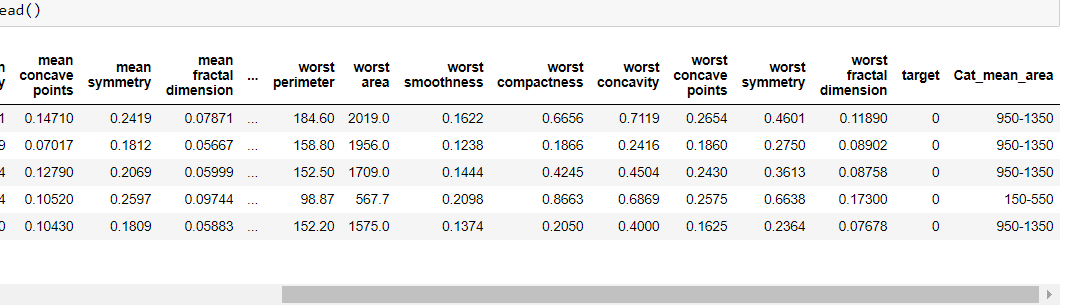
因此,我们创建了一个分类列“Cat_mean_area”,我们也可以在这里执行 groupby 聚合方法。但是,我们可以使用一些特定的列,例如仅平均面积和目标,而不是对整个数据集进行分组。
蟒蛇3
# dataframe df_3 to contain only mean_area,Cat_mean_area and target
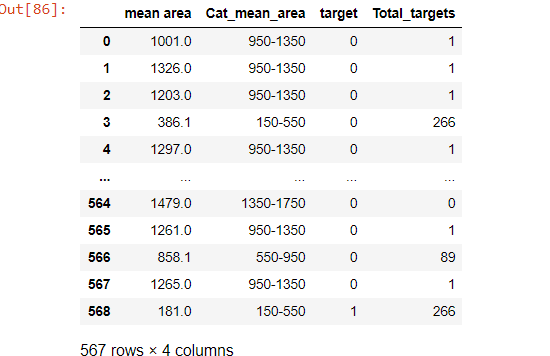
df_3 = df_2[['mean area', 'Cat_mean_area', 'target']]
# applying groupby sum
gr2 = df_3.groupby(df_2['Cat_mean_area']).sum()
gr2
输出:
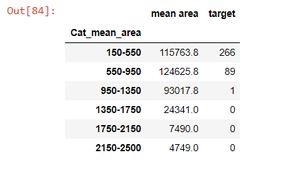
因此,通过上述步骤,我们在没有聚合的情况下执行 groupby。
蟒蛇3
# function to take the data as group and perform aggregation
def totalTargets(group):
g = group['target'].agg('sum')
group['Total_targets'] = g
return group
df_4 = df_3.groupby(df_3['Cat_mean_area']).apply(totalTargets)
df_4
输出: