Scrapy – 物品加载器
在本文中,我们将讨论Scrapy 中的项目加载器。
Scrapy 用于提取数据,使用蜘蛛,爬过网站。获取的数据也可以以Scrapy Items的形式进行处理。在填充项目字段之前,项目加载器在解析数据方面发挥着重要作用。在本文中,我们将了解项目加载器。
安装 Scrapy:
Scrapy,需要Python版本 3.6 及以上。使用 pip 命令在终端安装它,如下所示:
pip install Scrapy 此命令将在您的环境中安装 Scrapy 库。现在,我们可以创建一个 Scrapy 项目,来编写Python Spider 代码。
创建一个 Scrapy Spider 项目
Scrapy 带有一个高效的命令行工具,称为 Scrapy 工具。这些命令根据其用途具有一组不同的参数。为了编写 Spider 代码,我们首先创建一个 Scrapy 项目。在终端使用以下“startproject”命令——
scrapy startproject gfg_itemloaders此命令将创建一个名为“gfg_itemloaders”的文件夹。现在,将目录更改为同一文件夹,如下所示 –
使用 'startproject' 命令创建 Scrapy 项目
scrapy项目的文件夹结构如下图所示:
Scrapy项目的文件夹结构
它有一个scrapy.cfg 文件,它是项目配置文件。包含此文件的文件夹称为根目录。该目录下,还有 items.py 、 middleware.py 等设置文件,如下图——
Scrapy项目的文件夹结构
用于抓取的蜘蛛文件将在“蜘蛛”文件夹中创建。我们将在 items.py 文件中提及我们的 Scrapy 项目和相关的加载器逻辑。暂时保留文件的内容。使用 'genspider' 命令,创建一个蜘蛛代码文件。
scrapy genspider gfg_loadbookdata “books.toscrape.com/catalogue/category/books/womens-fiction_9”
命令,在终端,如下所示 -

使用 'genspider' 命令创建蜘蛛文件
使用 Scrapy 项目提取数据
我们将从女性小说网页上抓取书名和书价。 Scrapy,允许使用选择器来编写提取代码。可以使用遍历整个 HTML 页面的 CSS 或 XPath 表达式来编写它们,以获取我们想要的数据。抓取的主要目标是从非结构化来源获取结构化数据。通常 Scrapy 蜘蛛会在Python字典对象中产生数据。该方法是有益的,数据量很小。但是,随着数据的增加,复杂性也会增加。此外,可能需要在我们存储内容之前将数据处理为任何文件格式。这就是 Scrapy Items 派上用场的地方。它们允许使用项目加载器处理数据。让我们为 Book Title 和 Price 编写 Scrapy Item,以及 XPath 表达式。
'items.py' 文件,提到属性,我们需要抓取。
我们将它们定义如下:
Python3
# Define here the models for your scraped item
import scrapy
# Item class name for the book title and price
class GfgItemloadersItem(scrapy.Item):
# Scrape Book price
price = scrapy.Field()
# Scrape Book Title
title = scrapy.Field()Python3
# Import Scrapy library
import scrapy
# Import Item class
from ..items import GfgItemloadersItem
# Spider class name
class GfgLoadbookdataSpider(scrapy.Spider):
# Name of the spider
name = 'gfg_loadbookdata'
# The domain to be scraped
allowed_domains = [
'books.toscrape.com/catalogue/category/books/womens-fiction_9']
# The URL to be scraped
start_urls = [
'http://books.toscrape.com/catalogue/category/books/womens-fiction_9/']
# Default parse callback method
def parse(self, response):
# Create an object of Item class
item = GfgItemloadersItem()
# loop through all books
for books in response.xpath('//*[@class="product_pod"]'):
# XPath expression for the book price
price = books.xpath(
'.//*[@class="product_price"]/p/text()').extract_first()
# place price value in item key
item['price'] = price
# XPath expression for the book title
title = books.xpath('.//h3/a/text()').extract()
# place title value in item key
item['title'] = title
# yield the item
yield itemPython3
# Import the processor
from itemloaders.processors import Identity
# Create object of Identity processor
proc = Identity()
# Assign values and print result
print(proc(['star','moon','galaxy']))Python3
# import the processor module
from itemloaders.processors import TakeFirst
# Create object of TakeFirst processor
proc = TakeFirst()
# assign values and print the result
print(proc(['', 'star','moon','galaxy']))Python3
# Import the processor module
from itemloaders.processors import Compose
# Create an object of Compose processor and pass values
proc = Compose(lambda v: v[0], str.upper)
# Assign values and print result
print(proc(['hi', 'there']))Python3
# Import MapCompose processor
from itemloaders.processors import MapCompose
# custom function to filter star
def filter_star(x):
# return None if 'star' is present
return None if x == 'star' else x
# Assign the functions to MapCompose
proc = MapCompose(filter_star, str.upper)
# pass arguments and print result
print(proc(['twinkle', 'little', 'star','wonder', 'they']))Python3
# Import required processors
from itemloaders.processors import Join
# Put separator
while creating Join() object
proc = Join('')
# pass the values and print result
print(proc(['Sky', 'Moon','Stars']))Python3
# Import the class
from itemloaders.processors import SelectJmes
# prepare object of SelectJmes
proc = SelectJmes("hello")
# Print the output of json path
print(proc({'hello': 'scrapy'}))Python3
# Create loader object
loader = ItemLoader(item=Item())
# Item loader method for phoneno,
# mention the field name and xpath expression
loader.add_xpath('phoneno',
'//footer/a[@class = "phoneno"]/@href')
# Item loader method for map,
# mention the field name and xpath expression
loader.add_xpath('map',
'//footer/a[@class = "map"]/@href')
# populate the item
loader.load_item()Python3
# Define Item Loader object by passing item
loader = ItemLoader(item=Item())
# Create nested loader with footer selector
footer_loader = loader.nested_xpath('//footer')
# Add phoneno xpath values relative to the footer
footer_loader.add_xpath('phoneno', 'a[@class = "phoneno"]/@href')
# Add map xpath values relative to the footer
footer_loader.add_xpath('map', 'a[@class = "map"]/@href')
# Call loader.load_item() to populate values
loader.load_item()Python3
# Import the MapCompose built-in processor
from itemloaders.processors import MapCompose
# Import the existing BookLoader
# Item loader used for scraping book data
from myproject.ItemLoaders import BookLoader
# Custom function to remove the '*'
def strip_asterisk(x):
return x.strip('*')
# Extend and reuse the existing BookLoader class
class SiteSpecificLoader(BookLoader):
authorname = MapCompose(strip_asterisk,
BookLoader.authorname)Python3
# Import the Item Loader class
from scrapy.loader import ItemLoader
# Import the processors
from scrapy.loader.processors import TakeFirst, MapCompose, Join
# Extend the ItemLoader class
class BookLoader(ItemLoader):
# Mention the default output processor
default_output_processor = Takefirst()
# Input processor for book name
book_name_in = MapCompose(unicode.title)
# Output processor for book name
book_name_out = Join()
# Input processor for book price
book_price_in = MapCompose(unicode.strip)Python3
# Define here the models for your scraped items
# import Scrapy library
import scrapy
# import itemloader methods
from itemloaders.processors import TakeFirst, MapCompose
# import remove_tags method to remove all tags present
# in the response
from w3lib.html import remove_tags
# custom method to replace '&' with 'AND'
# in book title
def replace_and_sign(value):
# python replace method to replace '&' operator
# with 'AND'
return value.replace('&', ' AND ')
# custom method to remove the pound currency sign from
# book price
def remove_pound_sign(value):
# for pound press Alt + 0163
# python replace method to replace '£' with a blank
return value.replace('£', '').strip()
# Item class to define all the Item fields - book title
# and price
class GfgItemloadersItem(scrapy.Item):
# Assign the input and output processor for book price field
price = scrapy.Field(input_processor=MapCompose(
remove_tags, remove_pound_sign), output_processor=TakeFirst())
# Assign the input and output processor for book title field
title = scrapy.Field(input_processor=MapCompose(
remove_tags, replace_and_sign), output_processor=TakeFirst())Python3
# Import the required Scrapy library
import scrapy
# Import the Item Loader library
from scrapy.loader import ItemLoader
# Import the items class from 'items.py' file
from ..items import GfgItemloadersItem
# Spider class having Item loader
class GfgLoadbookdataSpider(scrapy.Spider):
# Name of the spider
name = 'gfg_loadbookdata'
# The domain to be scraped
allowed_domains = [
'books.toscrape.com/catalogue/category/books/womens-fiction_9']
# The webpage to be scraped
start_urls = [
'http://books.toscrape.com/catalogue/category/books/womens-fiction_9/']
# Default callback method used by the spider
# Data in the response will be processed here
def parse(self, response):
# Loop through all the books using XPath expression
for books in response.xpath('//*[@class="product_pod"]'):
# Define Item Loader object,
# by passing item and selector attribute
loader = ItemLoader(item=GfgItemloadersItem(), selector=books)
# Item loader method add_xpath(),for price,
# mention the field name and xpath expression
loader.add_xpath('price', './/*[@class="product_price"]/p/text()')
# Item loader method add_xpath(),
# for title, mention the field name
# and xpath expression
loader.add_xpath('title', './/h3/a/@title')
# use the load_item method of
# loader to populate the parsed items
yield loader.load_item()- 请注意,Field() 允许一种在一个位置定义所有字段元数据的方法。它不提供任何额外的属性。
- XPath 表达式,允许我们遍历网页,并提取数据。右键单击其中一本书,然后选择“检查”选项。这应该在浏览器中显示其 HTML 属性。网页上的所有书籍都包含在同一个
HTML 标签中,具有 class 属性,如“product_pod”。如下图所示——
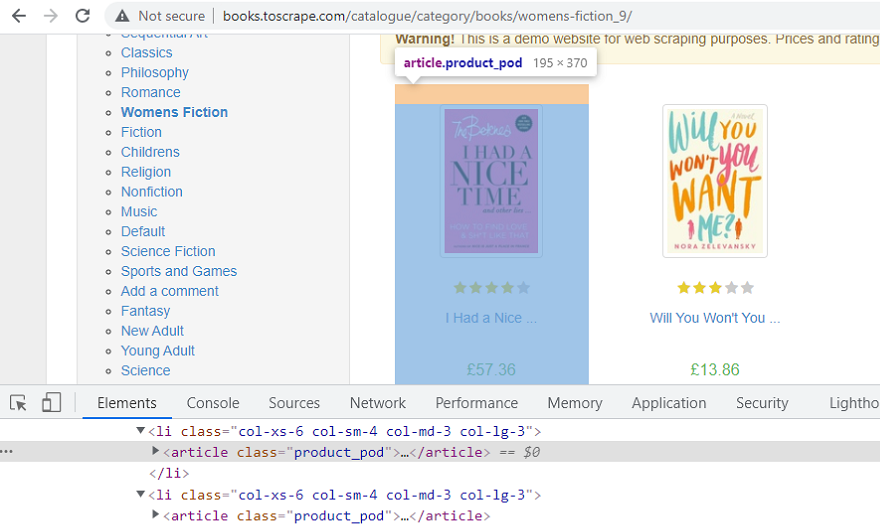
所有书籍都属于同一个 'class' 属性 'product_pod'
- 因此,我们可以遍历
标签类属性,以提取网页上的所有书名和价格。同样,XPath 表达式将是 books =response.xpath('//*[@class="product_pod"]')。这应该返回所有书籍 HTML 标签,属于“product_pod”类属性。 '*'运算符表示所有标签,属于类 'product_pod'。因此,我们现在可以有一个循环,导航到页面上的每一本书。 - 在循环内部,我们需要获得书名。因此,右键单击标题并选择“检查”。它包含在 标签中,在标题
标签内。我们将获取 标签的“title”属性。同样,XPath 表达式将是 books.xpath('.//h3/a/@title').extract()。点运算符, 表示我们现在将使用 'books' 对象从中提取数据。这种语法,将遍历标题,然后, 标记,以获取书名。
- 类似地,要获得书的价格,请右键单击并在其上说“检查”,以获取其 HTML 属性。所有 price 元素都属于 标签,类属性为“product_price”。实际价格在元素内的段落标记内被提及。因此,要获取 Price 的实际文本,XPath 表达式将是 books.xpath('.//*[@class="product_price"]/p/text()').extract_first()。 extract_first() 方法返回第一个价格值。
我们将在 Spider 中创建上述 Item 类的对象,并产生相同的结果。蜘蛛代码文件将如下所示:
蟒蛇3
# Import Scrapy library import scrapy # Import Item class from ..items import GfgItemloadersItem # Spider class name class GfgLoadbookdataSpider(scrapy.Spider): # Name of the spider name = 'gfg_loadbookdata' # The domain to be scraped allowed_domains = [ 'books.toscrape.com/catalogue/category/books/womens-fiction_9'] # The URL to be scraped start_urls = [ 'http://books.toscrape.com/catalogue/category/books/womens-fiction_9/'] # Default parse callback method def parse(self, response): # Create an object of Item class item = GfgItemloadersItem() # loop through all books for books in response.xpath('//*[@class="product_pod"]'): # XPath expression for the book price price = books.xpath( './/*[@class="product_price"]/p/text()').extract_first() # place price value in item key item['price'] = price # XPath expression for the book title title = books.xpath('.//h3/a/text()').extract() # place title value in item key item['title'] = title # yield the item yield item- 当我们执行时,上面的代码,使用scrapy“crawl”命令,使用语法为,scrapy crawl spider_name,在终端为——
scrapy crawl gfg_loadbookdata -o not_parsed_data.json数据被导出,在“not_parsed_data.json”文件中,可以看到如下:
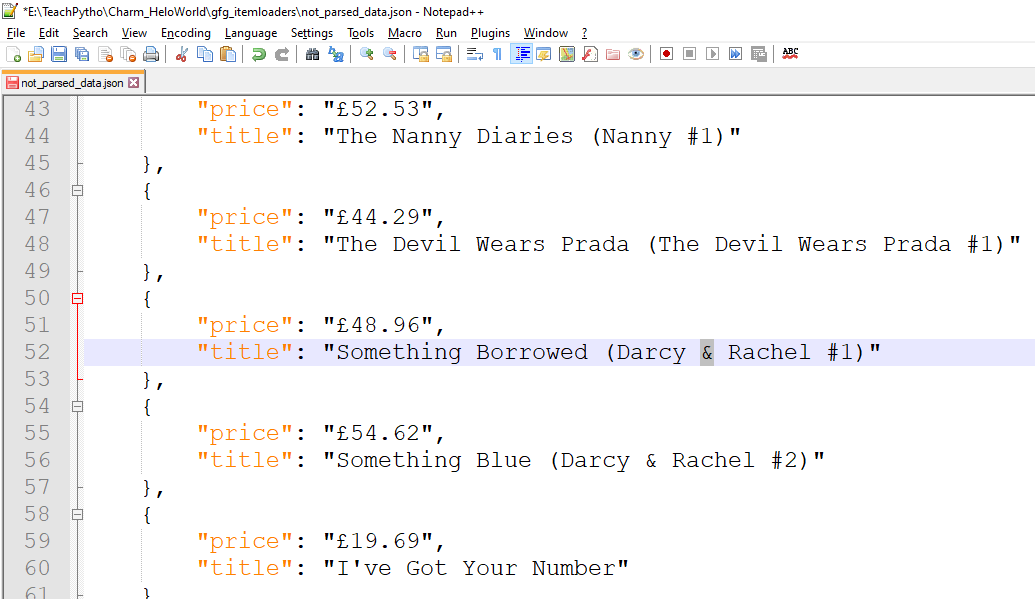
未解析数据时产生的项目
现在,假设我们想在产生和存储它们之前以任何文件格式处理抓取的数据,然后我们可以使用项目加载器。
物品加载器简介
项目加载器,允许更顺畅的方式来管理抓取的数据。很多时候,我们可能需要处理我们抓取的数据。这种处理可以是:
- 细化或编辑当前文本。
- 用另一个替换任何存在的字符,或者用正确的字符替换丢失的数据。
- 去除不需要的字符。
- 干净的空白字符。
在本文中,我们将进行以下处理——
- 从书价中删除“£”(英镑)货币。
- 将书名中出现的“&”符号替换为“AND”。
物品加载器如何工作?
到目前为止,我们知道,Item Loaders 用于在填充 Item 字段之前解析数据。让我们了解一下,Item Loaders 是如何工作的——
- 项目加载器,有助于将抓取的数据填充到 Scrapy 项目中。 Items 是在“items.py”文件中定义的字段。
- Item Loader 将有一个输入处理器和一个输出处理器,为每个 Item 字段定义。
- 我们知道,Scrapy 使用 Selectors,即 XPath 或 CSS 表达式来导航到所需的 HTML 标签。
- 项目加载器使用其 add_xpath() 或 add_css() 方法来获取所需的数据。
- 输入处理器,然后对这些数据采取行动。我们可以提到,我们的自定义函数,作为参数,输入处理器,解析我们想要的数据。
- 输入处理器的结果存储在 ItemLoader 中。
- 一旦接收到所有数据,并根据 input_processor 进行解析,加载器将调用其 load_item() 方法来填充 Item 对象。
- 在此过程中,输出处理器被调用,并作用于该中间数据。
- 输出处理器的结果分配给 Item 对象。
- 这就是解析 Item 对象的产生方式。
内置处理器:
现在,让我们了解内置处理器,以及我们将在项目加载器中使用的方法、实现。 Scrapy,有六个内置处理器。让我们知道他们——
Identity():这是默认的,也是最简单的处理器。它永远不会改变任何值。它可以用作输入和输出处理器。这意味着,当没有提到其他处理器时,它会起作用,并返回不变的值。
蟒蛇3
# Import the processor from itemloaders.processors import Identity # Create object of Identity processor proc = Identity() # Assign values and print result print(proc(['star','moon','galaxy']))输出:
['star','moon','galaxy']TakeFirst():从接收到的数据中返回第一个非空或非空值。它通常用作输出处理器。
蟒蛇3
# import the processor module from itemloaders.processors import TakeFirst # Create object of TakeFirst processor proc = TakeFirst() # assign values and print the result print(proc(['', 'star','moon','galaxy']))输出:
'star'Compose():这需要数据,并将其传递给函数,存在于参数中。如果参数中存在多个函数, 则将前一个函数的结果传递给下一个。这将继续,直到执行最后一个函数,并接收到输出。
蟒蛇3
# Import the processor module from itemloaders.processors import Compose # Create an object of Compose processor and pass values proc = Compose(lambda v: v[0], str.upper) # Assign values and print result print(proc(['hi', 'there']))输出:
HIMapCompose():此处理器的工作方式类似于 Compose。它可以在参数中具有多个功能。在这里,输入值被迭代,第一个函数,被应用于所有这些,产生一个新的可迭代对象。这个新的可迭代对象现在被传递给第二个函数,in 参数,依此类推。这主要用作输入处理器。
蟒蛇3
# Import MapCompose processor from itemloaders.processors import MapCompose # custom function to filter star def filter_star(x): # return None if 'star' is present return None if x == 'star' else x # Assign the functions to MapCompose proc = MapCompose(filter_star, str.upper) # pass arguments and print result print(proc(['twinkle', 'little', 'star','wonder', 'they']))输出:
['TWINKLE', 'LITTLE', 'WONDER', 'THEY']Join():这个处理器,返回连接在一起的值。要放置表达式,在每一项之间,可以使用分隔符,默认为'u'。在下面的示例中,我们使用 作为分隔符:
蟒蛇3
# Import required processors from itemloaders.processors import Join # Put separator
while creating Join() object proc = Join('') # pass the values and print result print(proc(['Sky', 'Moon','Stars']))输出:
SelectJmes():该处理器使用给定的 JSON 路径查询值并返回输出。
蟒蛇3
# Import the class from itemloaders.processors import SelectJmes # prepare object of SelectJmes proc = SelectJmes("hello") # Print the output of json path print(proc({'hello': 'scrapy'}))输出:
scrapy在这个例子中,我们使用了 TakeFirst() 和 MapCompose() 处理器。当项目加载器函数(如 add_xpath() 和其他函数)被执行时,处理器对抓取的数据进行操作。最常用的加载器函数是——
- add_xpath() – 此方法采用 item 字段,以及对应的 XPath 表达式。它主要接受参数为——
- field_name – 项目字段名称,在“items.py”类中定义。
- XPath - XPath 表达式,用于导航到标记。
- 处理器 - 输入处理器名称。如果未定义任何处理器,则调用默认处理器。
- add_css() – 此方法获取 item 字段,以及对应的 CSS 表达式。它主要接受参数为——
- field_name – 项目字段名称,在“items.py”类中定义。
- CSS- CSS 表达式,用于导航到标签。
- 处理器 - 输入处理器名称。如果未定义任何处理器,则调用默认处理器。
- add_value() – 此方法采用字符串字面量及其值。它接受参数为 -
- field_name- 任何字符串字面量。
- value –字符串字面量的值。
- 处理器 - 输入处理器名称。如果未定义任何处理器,则调用默认处理器。
可以使用任何上述加载程序方法。在本文中,我们使用了 XPath 表达式来抓取数据,因此使用了 loader 的 add_xpath() 方法。在 Scrapy 配置中,存在 processor.py 文件,我们可以从中导入所有提到的处理器。
项目加载器对象
通过实例化 ItemLoader 类,我们获得了一个项目加载器对象。 Scrapy 库中的 ItemLoader 类是 scrapy.loader.ItemLoader。 ItemLoader 对象创建的参数是 –
- item –这是 Item 类,通过调用 add_xpath()、add_css() 或 add_value() 方法来填充。
- 选择器——它是 CSS 或 XPath 表达式选择器,用于从网站获取要抓取的数据。
- response –使用 default_selector_class,用于准备一个选择器。
以下是 ItemLoader 对象可用的方法:
Sr. No Method Description 1 get_value(value,*processors,**kwargs) The value, is processed by the mentioned processor, and, keyword arguments. The keyword argument parameter can be :
‘re’ , A regular expression to use, for getting data, from the given value, applied before processor.
2 add_value(fieldname,*processors, **kwargs) Process, and, then add the given value, for the field given. Here, value is first passed, through the get_value(), by giving the processor and kwargs. It is then passed, through the field input processor. The result is appended, to the data collected, for that field. If field, already contains data, then, new data is added. The field name can have None value as well. Here, multiple values can be added, in the form of dictionary objects. 3 replace_value(fieldname, *processors, **kwargs) This method, replaces the collected value with new value, instead of adding it. 4 get_xpath( xpath,*processors, **kwargs) This method receives an XPath expression. This expression, is used to get a list of Unicode strings, from the selector, which is related, to the ItemLoader. This method, is similar to ItemLoader.get_value(). The parameters, to this method are –
xpath – the XPath expression to extract data from webpage
re – A regular expression string, or, a pattern to get data from the XPAth region.
5 add_xpath(xpath,*processors, **kwargs) This method, receives an XPAth expression, that is used to select, a list of strings, from the selector, related with the ItemLoader. It is similar to ItemLoader.add_value(). Parameter is –
xpath – The XPAth expression to extract data from.
6 replace_xpath(fieldname, xpath,*processors,**kwargs) Instead of, adding the extracted data, this method, replaces the collected data. 7 get_css(css, *processors, **kwargs) This method, receives a CSS selector, and, not a value, which is then used to get a list of Unicode strings, from the selector, associated with the ItemLoader. The parameters can be –
css – The string selector to get data from
re – A regular expression string or a pattern to get data from the CSS region.
8 add_css(fieldname, css, *processors, **kwargs) This method, adds a CSS selector, to the field. It is similar to add_value(), but, receives a CSS selector. Parameter is –
css – A string CSS selector to extract data from
9 replace_css(fieldname, css, *processors, **kwargs) Instead of, adding collected data, this method replaces it, using the CSS selector. 10 load_item() This method, is used to populate, the item received so far, and return it. The data, is first passed through, the output_processors, so that the final value, is assigned to each field. 11 nested_css(css, **context) Using CSS selector, this method is used to create nested selectors. The CSS supplied, is applied relative, to the selector, associated to the ItemLoader. 12 nested_xpath(xpath) Using XPath selector, create a nested loader. The XPAth supplied, is applied relative, to the selector associated to the ItemLoader. 嵌套加载器
当我们从文档的子部分解析相关的值时,嵌套加载器很有用。如果没有它们,我们需要提及我们想要提取的数据的整个 XPath 或 CSS 路径。考虑以下 HTML 页脚示例 -
蟒蛇3
# Create loader object loader = ItemLoader(item=Item()) # Item loader method for phoneno, # mention the field name and xpath expression loader.add_xpath('phoneno', '//footer/a[@class = "phoneno"]/@href') # Item loader method for map, # mention the field name and xpath expression loader.add_xpath('map', '//footer/a[@class = "map"]/@href') # populate the item loader.load_item()
使用嵌套加载器,我们可以避免使用嵌套页脚选择器,如下所示:蟒蛇3
# Define Item Loader object by passing item loader = ItemLoader(item=Item()) # Create nested loader with footer selector footer_loader = loader.nested_xpath('//footer') # Add phoneno xpath values relative to the footer footer_loader.add_xpath('phoneno', 'a[@class = "phoneno"]/@href') # Add map xpath values relative to the footer footer_loader.add_xpath('map', 'a[@class = "map"]/@href') # Call loader.load_item() to populate values loader.load_item()请注意以下有关嵌套加载器的要点:
- 它们与 CSS 和 XPath 选择器一起使用。
- 它们可以随机嵌套。
- 它们可以使代码看起来更简单。
- 不要不必要地使用它们,否则解析器会变得难以阅读。
重用和扩展项目加载器
随着项目的增长,以及为数据抓取而编写的蜘蛛程序的数量,维护变得困难。此外,每个其他蜘蛛的解析规则可能会改变。为简化维护,解析,Item Loaders 支持,常规Python继承,处理差异,存在于一组蜘蛛中。让我们看一个例子,扩展加载器可能会带来好处。
假设任何电子商务图书网站都有其图书作者姓名,以“*”(星号)开头。如果需要,要删除出现在最终抓取的作者姓名中的那些“*”,我们可以重用并扩展默认加载器类“BookLoader”,如下所示:
蟒蛇3
# Import the MapCompose built-in processor from itemloaders.processors import MapCompose # Import the existing BookLoader # Item loader used for scraping book data from myproject.ItemLoaders import BookLoader # Custom function to remove the '*' def strip_asterisk(x): return x.strip('*') # Extend and reuse the existing BookLoader class class SiteSpecificLoader(BookLoader): authorname = MapCompose(strip_asterisk, BookLoader.authorname)在上面的代码中,BookLoader 是一个父类,对于 SiteSpecificLoader 类。通过重用现有的加载器,我们在新的加载器类中只添加了带“*”的功能。
声明自定义项目加载器处理器
就像项目一样,项目加载器也可以使用类语法来声明。可以进行声明,如下所示:
蟒蛇3
# Import the Item Loader class from scrapy.loader import ItemLoader # Import the processors from scrapy.loader.processors import TakeFirst, MapCompose, Join # Extend the ItemLoader class class BookLoader(ItemLoader): # Mention the default output processor default_output_processor = Takefirst() # Input processor for book name book_name_in = MapCompose(unicode.title) # Output processor for book name book_name_out = Join() # Input processor for book price book_price_in = MapCompose(unicode.strip)代码可以理解为:
- BookLoader 类扩展了 ItemLoader。
- book_name_in 有一个 MapCompose 实例,定义了函数unicode.title,它将应用于 book_name 项。
- book_name_out 被定义为 Join() 类实例。
- book_price_in 有一个 MapCompose 实例,具有定义的函数unicode.strip,它将应用于 book_price 项目。
实现项目加载器来解析数据:
现在,我们对项目加载器有了一个大致的了解。让我们在我们的例子中实现上述概念——
- 在spider 'gfg_loadbookdata.py' 文件中,我们通过使用Scrapy.Loader.Itemloader 模块定义了ItemLoaders。语法将是 -“from scrapy.loader import ItemLoader”。
- 在 parse 方法中,它是蜘蛛的默认回调方法,我们已经在遍历所有书籍。
- 在循环内,创建一个 ItemLoader 类的对象,使用参数作为 –
- 传递项目属性名称,作为 GfgItemloadersItem
- 传递选择器属性,作为“书籍”
- 所以代码看起来 - “loader = ItemLoader(item=GfgItemloadersItem(), selector=books)”
- 使用项目加载器方法 add_xpath(),并传递项目字段名称和 XPath 表达式。
- 使用 'price' 字段,并在 add_xpath() 方法中写入它的 XPath。语法将是 – “loader.add_xpath('price', './/*[@class="product_price"]/p/text()')”。在这里,我们通过导航到价格标签来选择价格文本,然后使用 text() 方法获取。
- 使用“title”字段,并在 add_xpath() 方法中编写其 XPath 表达式。语法将是 – “loader.add_xpath('title', './/h3/a/@title')”。在这里,我们正在获取 标签的“title”属性值。
- Yield,加载器项目,现在通过使用加载器的 load_item() 方法。
- 现在,让我们在“items.py”文件中进行更改。对于此处定义的 Every Item 字段,有一个输入和输出处理器。当接收到数据时,输入处理器对它们进行处理,如函数定义的那样。然后,准备一个内部元素列表,并在填充它们时使用 load_item() 方法将它们传递给输出处理器函数。目前,价格和标题被定义为scrapy.Field()。
- 对于 Book Price 值,我们需要将“£”符号替换为空白。在这里,我们将 MapCompose() 内置处理器分配为 input_processor。第一个参数是 remove_tags 方法,它删除所选响应中存在的所有标签。第二个参数将是我们的自定义函数,remove_pound_sign(),它将替换“£”符号为空白。对于 Price 字段,output_processor 将是 TakeFirst(),它是内置处理器,用于从输出中返回第一个非空值。因此,Price Item 字段的语法将是 price = scrapy.Field(input_processor=MapCompose(remove_tags, remove_pound_sign), output_processor=TakeFirst())。
- 用于 Price 的函数是 remove_tags 和 remove_pound_sign。 remove_tags() 方法是从 Urllib HTML 模块导入的。它会删除抓取的响应中存在的所有标签。 remove_pound_sign() 是我们的自定义方法,它接受每本书的“价格”值,并将其替换为空白。内置的Python替换函数用于替换。
- 同样,对于书名,我们将通过分配适当的输入和输出处理器将 '&' 替换为 'AND'。 input_processor 将是 MapCompose(),它的第一个参数将是 remove_tags 方法,它将删除所有标签,以及 replace_and_sign(),我们的自定义方法将“&”替换为“AND”。 output_processor 将是 TakeFirst(),它将从输出中返回第一个非空值。因此,书名字段将是 title= scrapy.Field(input_processor=MapCompose(remove_tags, replace_and_sign), output_processor=TakeFirst())。
- 用于 Title 的函数是 remove_tags 和 replace_and_sign。 remove_tags 方法是从 Urllib HTML 模块导入的。它会删除抓取的响应中存在的所有标签。 replace_and_sign() 是我们的自定义方法,它接受每本书的“&”运算符,并用“AND”替换它。内置的Python替换函数用于替换。
我们的“items.py”类的最终代码如下所示:
蟒蛇3
# Define here the models for your scraped items # import Scrapy library import scrapy # import itemloader methods from itemloaders.processors import TakeFirst, MapCompose # import remove_tags method to remove all tags present # in the response from w3lib.html import remove_tags # custom method to replace '&' with 'AND' # in book title def replace_and_sign(value): # python replace method to replace '&' operator # with 'AND' return value.replace('&', ' AND ') # custom method to remove the pound currency sign from # book price def remove_pound_sign(value): # for pound press Alt + 0163 # python replace method to replace '£' with a blank return value.replace('£', '').strip() # Item class to define all the Item fields - book title # and price class GfgItemloadersItem(scrapy.Item): # Assign the input and output processor for book price field price = scrapy.Field(input_processor=MapCompose( remove_tags, remove_pound_sign), output_processor=TakeFirst()) # Assign the input and output processor for book title field title = scrapy.Field(input_processor=MapCompose( remove_tags, replace_and_sign), output_processor=TakeFirst())最终的蜘蛛文件代码如下所示:
蟒蛇3
# Import the required Scrapy library import scrapy # Import the Item Loader library from scrapy.loader import ItemLoader # Import the items class from 'items.py' file from ..items import GfgItemloadersItem # Spider class having Item loader class GfgLoadbookdataSpider(scrapy.Spider): # Name of the spider name = 'gfg_loadbookdata' # The domain to be scraped allowed_domains = [ 'books.toscrape.com/catalogue/category/books/womens-fiction_9'] # The webpage to be scraped start_urls = [ 'http://books.toscrape.com/catalogue/category/books/womens-fiction_9/'] # Default callback method used by the spider # Data in the response will be processed here def parse(self, response): # Loop through all the books using XPath expression for books in response.xpath('//*[@class="product_pod"]'): # Define Item Loader object, # by passing item and selector attribute loader = ItemLoader(item=GfgItemloadersItem(), selector=books) # Item loader method add_xpath(),for price, # mention the field name and xpath expression loader.add_xpath('price', './/*[@class="product_price"]/p/text()') # Item loader method add_xpath(), # for title, mention the field name # and xpath expression loader.add_xpath('title', './/h3/a/@title') # use the load_item method of # loader to populate the parsed items yield loader.load_item()我们可以运行,并将数据保存在 JSON 文件中,使用 scrapy 'crawl' 命令使用语法 scrapy crawl spider_name as –
scrapy crawl gfg_loadbookdata -o parsed_bookdata.json
上面的命令将抓取数据,解析数据,这意味着井号不会出现,并且“&”运算符将被替换为“AND”。 parsed_bookdata.json 文件创建如下:
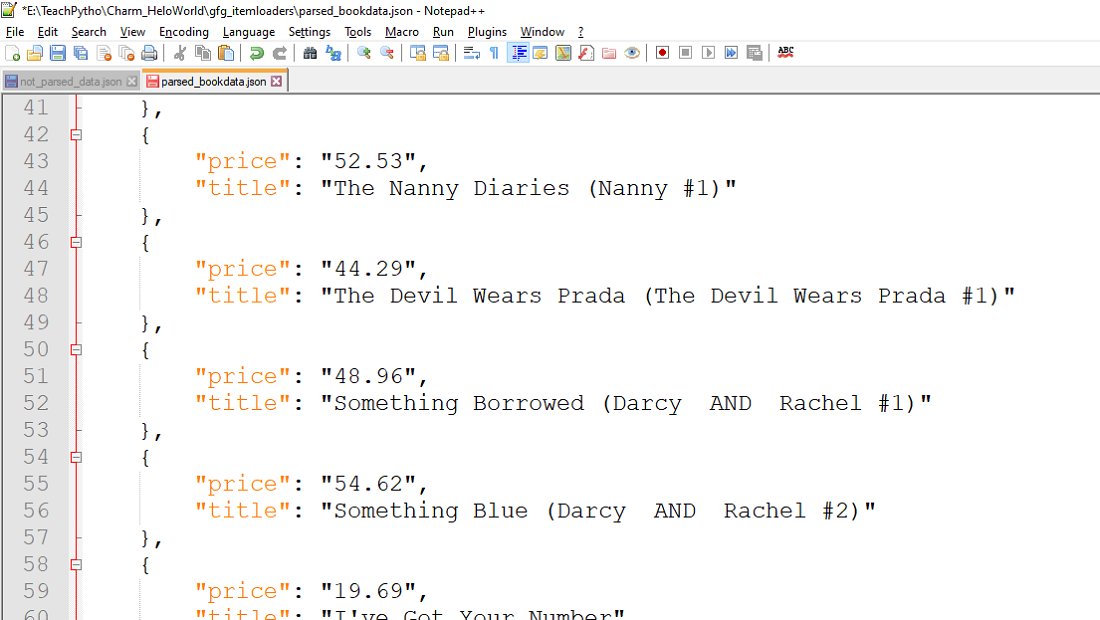
使用 Item Loaders 解析的 JSON 输出文件