毫升 |使用Python进行逻辑回归
先决条件:了解逻辑回归
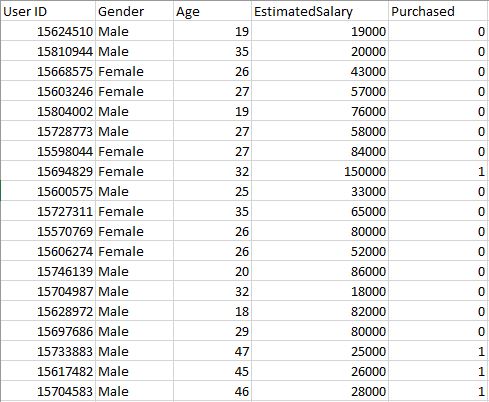
用户数据库——该数据集包含来自公司数据库的用户信息。它包含有关用户 ID、性别、年龄、EstimatedSalary、已购买的信息。我们使用这个数据集来预测用户是否会购买公司新推出的产品。
数据 – User_Data
让我们建立逻辑回归模型,预测用户是否会购买产品。
输入库
Python3
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltPython3
dataset = pd.read_csv('...\\User_Data.csv')Python3
# input
x = dataset.iloc[:, [2, 3]].values
# output
y = dataset.iloc[:, 4].valuesPython3
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(
x, y, test_size = 0.25, random_state = 0)Python3
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
xtrain = sc_x.fit_transform(xtrain)
xtest = sc_x.transform(xtest)
print (xtrain[0:10, :])Python3
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(xtrain, ytrain)Python3
y_pred = classifier.predict(xtest)Python3
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(ytest, y_pred)
print ("Confusion Matrix : \n", cm)Python3
from sklearn.metrics import accuracy_score
print ("Accuracy : ", accuracy_score(ytest, y_pred))Python3
from matplotlib.colors import ListedColormap
X_set, y_set = xtest, ytest
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(
np.array([X1.ravel(), X2.ravel()]).T).reshape(
X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Classifier (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()加载数据集 – User_Data
Python3
dataset = pd.read_csv('...\\User_Data.csv')
现在,要预测用户是否会购买产品,需要找出年龄和预估薪水之间的关系。在这里,用户 ID 和性别不是找出这一点的重要因素。
Python3
# input
x = dataset.iloc[:, [2, 3]].values
# output
y = dataset.iloc[:, 4].values
拆分数据集以进行训练和测试。 75% 的数据用于训练模型,25% 用于测试我们模型的性能。
Python3
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(
x, y, test_size = 0.25, random_state = 0)
现在,在这里执行特征缩放非常重要,因为 Age 和 Estimated Salary 值位于不同的范围内。如果我们不对特征进行缩放,那么当模型在数据空间中找到与数据点最近的邻居时,估计薪水特征将主导年龄特征。
Python3
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
xtrain = sc_x.fit_transform(xtrain)
xtest = sc_x.transform(xtest)
print (xtrain[0:10, :])
输出 :
[[ 0.58164944 -0.88670699]
[-0.60673761 1.46173768]
[-0.01254409 -0.5677824 ]
[-0.60673761 1.89663484]
[ 1.37390747 -1.40858358]
[ 1.47293972 0.99784738]
[ 0.08648817 -0.79972756]
[-0.01254409 -0.24885782]
[-0.21060859 -0.5677824 ]
[-0.21060859 -0.19087153]]这里曾经看到 Age 和 Estimated Salary 特征值被删除,现在在 -1 到 1 之间。因此,每个特征都将在决策制定中做出同等贡献,即最终确定假设。
最后,我们正在训练我们的逻辑回归模型。
Python3
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(xtrain, ytrain)
在训练模型之后,是时候使用它对测试数据进行预测了。
Python3
y_pred = classifier.predict(xtest)
让我们测试一下我们模型的性能——混淆矩阵
Python3
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(ytest, y_pred)
print ("Confusion Matrix : \n", cm)
输出 :
Confusion Matrix :
[[65 3]
[ 8 24]]满分 100 :
真阳性 + 真阴性 = 65 + 24
假阳性 + 假阴性 = 3 + 8
绩效衡量——准确性
Python3
from sklearn.metrics import accuracy_score
print ("Accuracy : ", accuracy_score(ytest, y_pred))
输出 :
Accuracy : 0.89可视化我们模型的性能。
Python3
from matplotlib.colors import ListedColormap
X_set, y_set = xtest, ytest
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(
np.array([X1.ravel(), X2.ravel()]).T).reshape(
X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Classifier (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
输出 :
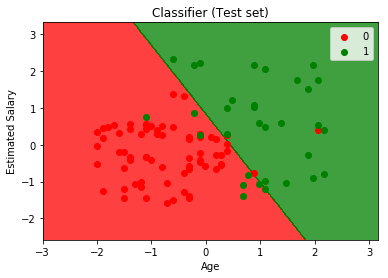
分析性能指标——准确度和混淆矩阵以及图表,我们可以清楚地说我们的模型表现得非常好。