R 编程中的逻辑回归
R编程中的逻辑回归是一种分类算法,用于查找事件成功和事件失败的概率。当因变量本质上是二元(0/1、真/假、是/否)时,使用逻辑回归。 Logit函数用作二项分布中的链接函数。

逻辑回归也称为二项式逻辑回归。它基于 sigmoid函数,其中输出是概率,输入可以从 -infinity 到 +infinity。
理论
逻辑回归也称为广义线性模型。由于它被用作预测定性响应的分类技术,因此 y 的值范围从 0 到 1,可以用以下等式表示:
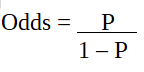
p是感兴趣特征的概率。优势比定义为成功概率与失败概率的比较。它是逻辑回归系数的关键表示,可以取 0 到无穷大之间的值。当成功的概率等于失败的概率时,优势比为 1。当成功概率是失败概率的两倍时,优势比为 2。当失败概率是成功概率的两倍时,优势比为 0.5。
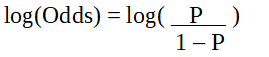
由于我们使用的是二项分布(因变量),因此我们需要选择最适合该分布的链接函数。
![]()
它是logit函数。在上面的等式中,选择括号是为了最大化观察样本值的可能性,而不是最小化平方误差之和(如普通回归)。 logit 也称为赔率对数。 logit函数必须与自变量线性相关。这来自方程 A,其中左侧是 x 的线性组合。这类似于 y 与 x 线性相关的 OLS 假设。
变量 b0、b1、b2 ... 等是未知的,必须根据可用的训练数据进行估计。在逻辑回归模型中,将 b1 乘以一个单位会将 logit 更改为 b0。由于一个单位的变化而导致的 P 变化将取决于乘以的值。如果 b1 为正,则 P 将增加,如果 b1 为负,则 P 将减少。
数据集
mtcars (motor trend car road test)包含了32辆汽车的油耗、性能和汽车设计的10个方面。它预先安装在 R 中的dplyr包中。
# Installing the package
install.packages("dplyr")
# Loading package
library(dplyr)
# Summary of dataset in package
summary(mtcars)
对数据集执行逻辑回归
逻辑回归在 R 中使用glm()通过使用数据集中的特征或变量训练模型来实现。
# Installing the package
install.packages("caTools") # For Logistic regression
install.packages("ROCR") # For ROC curve to evaluate model
# Loading package
library(caTools)
library(ROCR)
# Splitting dataset
split <- sample.split(mtcars, SplitRatio = 0.8)
split
train_reg <- subset(mtcars, split == "TRUE")
test_reg <- subset(mtcars, split == "FALSE")
# Training model
logistic_model <- glm(vs ~ wt + disp,
data = train_reg,
family = "binomial")
logistic_model
# Summary
summary(logistic_model)
# Predict test data based on model
predict_reg <- predict(logistic_model,
test_reg, type = "response")
predict_reg
# Changing probabilities
predict_reg <- ifelse(predict_reg >0.5, 1, 0)
# Evaluating model accuracy
# using confusion matrix
table(test_reg$vs, predict_reg)
missing_classerr <- mean(predict_reg != test_reg$vs)
print(paste('Accuracy =', 1 - missing_classerr))
# ROC-AUC Curve
ROCPred <- prediction(predict_reg, test_reg$vs)
ROCPer <- performance(ROCPred, measure = "tpr",
x.measure = "fpr")
auc <- performance(ROCPred, measure = "auc")
auc <- auc@y.values[[1]]
auc
# Plotting curve
plot(ROCPer)
plot(ROCPer, colorize = TRUE,
print.cutoffs.at = seq(0.1, by = 0.1),
main = "ROC CURVE")
abline(a = 0, b = 1)
auc <- round(auc, 4)
legend(.6, .4, auc, title = "AUC", cex = 1)
wt正向影响因变量,wt 增加一个单位会使 vs = 1 的几率对数增加 1.44。 disp对因变量产生负面影响,并且 disp 增加一个单位会使 vs = 1 的几率对数减少 0.0344。空偏差为 31.755(用截距拟合因变量),残差为 14.457(用所有自变量拟合因变量)。 AIC(碱性信息标准)值为 20.457,即模型越小越好。准确度为 0.75,即 75%。
使用混淆矩阵、AUC(曲线下面积)和 ROC(接受者操作特征)曲线评估模型。在混淆矩阵中,我们不应该总是寻找准确性,还要寻找敏感性和特异性。绘制 ROC 和 AUC 曲线。
输出:
- 使用混淆矩阵评估模型精度:

有 0 个类型 2 错误,即当它为假时无法拒绝它。此外,还有 3 个类型 1 错误,即当它为真时拒绝它。
- ROC曲线:

在 ROC 曲线中,曲线下面积越大,模型越好。
- ROC-AUC 曲线:
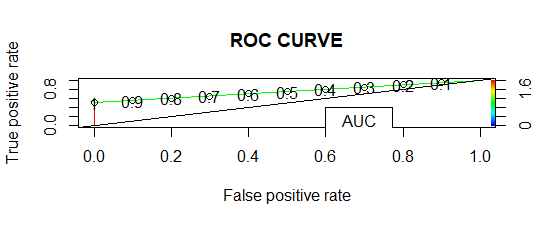
AUC 为 0.7333,因此 AUC 越大,模型性能越好。