📅 最后修改于: 2020-10-14 06:38:14 🧑 作者: Mango
数据结构
介绍
数据结构可以定义为一组数据元素,它提供了一种在计算机中存储和组织数据的有效方式,以便可以有效地使用它。数据结构的一些示例是数组,链表,堆栈,队列等。数据结构几乎在计算机科学的各个方面(例如操作系统,编译器设计,人工智能,图形等)广泛使用。
数据结构是许多计算机科学算法的主要部分,因为它们使程序员能够高效地处理数据。它在提高软件或程序的性能方面起着至关重要的作用,因为软件的主要函数是尽可能快地存储和检索用户数据。
基本术语
数据结构是任何程序或软件的基础。为程序选择合适的数据结构是程序员最困难的任务。就数据结构而言,使用以下术语
数据:数据可以定义为基本值或值的集合,例如,学生的姓名及其ID是有关学生的数据。
小组项目:具有从属数据项目的数据项目称为小组项目,例如,学生的名字可以有名字和姓氏。
记录:记录可以定义为各种数据项的集合,例如,如果我们谈论学生实体,则可以将其名称,地址,课程和标记分组在一起以形成学生的记录。
文件:文件是一种类型的实体的各种记录的集合,例如,如果班级中有60名员工,则相关文件中将有20条记录,其中每个记录都包含有关每个员工的数据。
属性和实体:实体代表某些对象的类。它包含各种属性。每个属性代表该实体的特定属性。
字段:字段是表示实体属性的单个基本信息单元。
数据结构需求
随着应用程序变得越来越复杂,数据量日益增加,可能会出现以下问题:
处理器速度:要处理大量数据,需要进行高速处理,但是随着数据一天一天地增长到每个实体数十亿个文件,处理器可能无法处理那么多数据。
数据搜索:考虑商店中库存商品的大小为106,如果我们的应用程序需要搜索特定商品,则每次需要遍历106个商品,这会减慢搜索过程。
多个请求:如果成千上万的用户正在Web服务器上同时搜索数据,则在此过程中很可能导致大型服务器发生故障
为了解决上述问题,使用了数据结构。数据被组织成一个数据结构,从而不需要搜索所有项目,并且可以立即搜索所需数据。
数据结构的优势
效率:程序的效率取决于数据结构的选择。例如:假设,我们有一些数据,我们需要搜索垂直记录。在这种情况下,如果我们将数据组织在一个数组中,则必须逐个元素顺序搜索。因此,在这里使用数组可能不是很有效。有更好的数据结构可以使搜索过程高效,例如有序数组,二进制搜索树或哈希表。
可重用性:数据结构是可重用的,即一旦实现了特定的数据结构,便可以在其他任何地方使用它。可以将数据结构的实现编译成可以供不同客户端使用的库。
抽象:数据结构由ADT指定,该结构提供了抽象级别。客户端程序仅通过接口使用数据结构,而无需深入了解实现细节。
数据结构分类
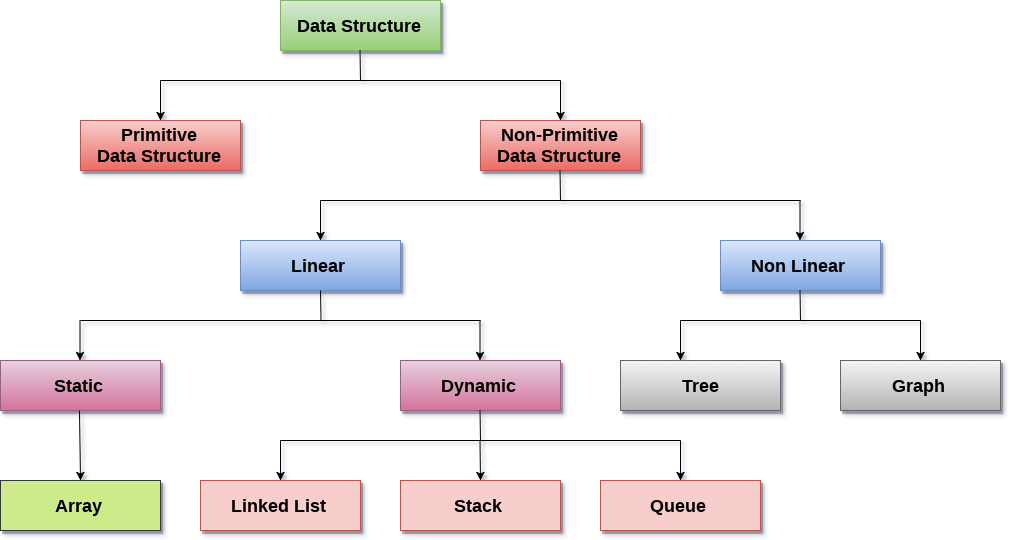
线性数据结构:如果数据结构的所有元素都按线性顺序排列,则称其为线性。在线性数据结构中,元素以非分层方式存储,其中每个元素除第一个和最后一个元素外,都有后继者和前任者。
线性数据结构的类型如下:
数组的元素共享相同的变量名,但是每个元素带有不同的索引号,称为下标。该阵列可以是一维,二维或多维的。
数组年龄的各个元素是:
年龄[0],年龄[1],年龄[2],年龄[3],………年龄[98],年龄[99]。
链接列表:链接列表是一种线性数据结构,用于在内存中维护列表。可以将其视为存储在非连续内存位置的节点的集合。列表中的每个节点都包含一个指向其相邻节点的指针。
堆栈:堆栈是一个线性列表,其中仅在一端(称为top)允许插入和删除。
堆栈是一种抽象数据类型(ADT),可以用大多数编程语言来实现。之所以称为“堆栈”,是因为它的行为类似于现实世界中的堆栈,例如:-一堆盘子或一副纸牌等。
队列:队列是一个线性列表,其中元素只能在称为后方的一端插入,而只能在称为前方的另一端删除。
它是一种抽象的数据结构,类似于堆栈。队列在两端均打开,因此遵循先进先出(FIFO)方法存储数据项。
非线性数据结构:此数据结构不形成序列,即每个项目或元素都以非线性排列方式与两个或多个其他项目连接。数据元素未按顺序结构排列。
非线性数据结构的类型如下:
树:树是多级数据结构,在其元素之间具有分层关系,称为节点。最高层中的最底层节点称为叶节点,而最高层的节点称为根节点。每个节点都包含指向相邻节点的指针。
树数据结构基于节点之间的父子关系。除叶节点外,树中的每个节点可以有多个子节点,而除根节点外,每个节点最多可以有一个父节点。树可以分为许多类别,本教程后面将对此进行讨论。
图形:图形可以定义为通过称为边的链接连接的元素集(由顶点表示)的图形表示。图与树的不同之处在于,图可以具有循环而树不可以具有循环。
数据结构操作
1)遍历:每个数据结构都包含一组数据元素。遍历数据结构意味着访问数据结构的每个元素,以便执行某些特定操作,例如搜索或排序。
示例:如果我们需要计算一个学生在6个不同科目中获得的平均分数,则需要遍历完整的分数数组并计算总和,那么我们将该总和除以科目数量即6,为了找到平均值。
2)插入:插入可以定义为在任何位置将元素添加到数据结构的过程。
如果数据结构的大小为n,那么我们只能将n-1个数据元素插入其中。
3)删除:从数据结构中删除元素的过程称为删除。我们可以在任何随机位置从数据结构中删除元素。
如果我们尝试从空数据结构中删除元素,则会发生下溢。
4)搜索:在数据结构中查找元素位置的过程称为“搜索”。有两种执行搜索的算法,线性搜索和二进制搜索。在本教程的后面,我们将讨论其中的每一个。
5)排序:按特定顺序排列数据结构的过程称为排序。有许多算法可用于执行排序,例如插入排序,选择排序,冒泡排序等。
6)合并:当两个相似大小的元素的列表A和列表B分别为M和N时,合并或合并以生成大小为(M + N)的列表C,则此过程称为合并