- 渐进测试
- 渐进符号和先验分析
- 渐进符号和先验分析(1)
- 软件测试中的渐进测试
- 软件测试中的渐进测试(1)
- html拖拽渐进栏 - Html(1)
- html拖拽渐进栏 - Html代码示例
- 数据结构-渐近分析
- 数据结构-渐近分析(1)
- C++数据结构(1)
- 树数据结构
- 堆数据结构(1)
- 数据结构-图(1)
- 数据结构-图
- 数据结构 (1)
- C++数据结构
- 堆数据结构
- 数据结构-树
- c++ 数据结构 - C++ (1)
- 树数据结构(1)
- 堆数据结构
- 算法分析|大O分析(1)
- 算法分析|大O分析
- 算法分析|大O分析
- Python数据结构
- Python数据结构(1)
- c++ 数据结构 - C++ 代码示例
- 数据结构-图形数据结构(1)
- 数据结构-图形数据结构
📅 最后修改于: 2020-10-14 06:46:41 🧑 作者: Mango
渐近分析
众所周知,数据结构是有效组织数据的一种方式,效率是根据时间或空间来衡量的。因此,理想的数据结构是一种占用最少时间来执行其所有操作和存储空间的结构。我们的重点是找到时间复杂度而不是空间复杂度,并且通过找到时间复杂度,我们可以决定哪种数据结构最适合算法。
我们想到的主要问题是,应在什么基础上比较数据结构的时间复杂度?可以基于对其执行的操作来比较时间复杂度。让我们考虑一个简单的例子。
假设我们有一个由100个元素组成的数组,并且我们想在数组的开头插入一个新元素。这是一项非常繁琐的任务,因为我们首先需要将元素向右移动,然后在数组的开头添加新元素。
假设我们将链表视为要在开头添加元素的数据结构。链表包含两部分,即下一个节点的数据和地址。我们只需在新节点中添加第一个节点的地址,然后头指针将指向新添加的节点。因此,我们得出的结论是,将数据添加到链表的开头比数组快。这样,我们可以比较数据结构并选择最佳的数据结构来执行操作。
如何找到执行操作的时间复杂度或运行时间?
实际运行时间的测量根本不可行。执行任何操作的运行时间取决于输入的大小。让我们通过一个简单的示例来理解该语句。
假设我们有一个由五个元素组成的数组,并且我们想在数组的开头添加一个新元素。为此,我们需要将每个元素向右移动,并假设每个元素花费一个单位时间。有五个元素,因此将采用五个时间单位。假设数组中有1000个元素,那么转移需要1000单位时间。结论是时间复杂度取决于输入大小。
因此,如果输入大小为n,则f(n)是n的函数,n表示时间复杂度。
如何计算f(n)?
对于较小的程序,计算f(n)的值很容易,但是对于较大的程序,并不是那么容易。我们可以通过比较它们的f(n)值来比较它们。我们可以通过比较它们的f(n)值来比较它们。我们将找到f(n)的增长率,因为一种可能的情况是,一个较小输入大小的数据结构优于另一个,而不是较大大小的数据结构。现在,如何找到f(n)。
让我们看一个简单的例子。
f(n)= 5n2 + 6n + 12
其中n是执行的指令数,它取决于输入的大小。
当n = 1
5n2 = * 100 = 21.74%导致的运行时间百分比
由于6n = * 100 = 26.09%而导致的运行时间百分比
由于12 = * 100 = 52.17%而导致的运行时间百分比
从上面的计算可以看出,大多数时间是由12占用的。但是,我们必须找到f(n)的增长率,我们不能说最大时间是由12占用的。不同的n值来找到f(n)的增长率。
| n | 5n2 | 6n | 12 |
| 1 | 21.74% | 26.09% | 52.17% |
| 10 | 87.41% | 10.49% | 2.09% |
| 100 | 98.79% | 1.19% | 0.02% |
| 1000 | 99.88% | 0.12% | 0.0002% |
从上表可以看出,随着n值的增加,5n2的运行时间增加,而6n和12的运行时间也减少。因此,可以观察到,对于较大的n值,平方项几乎消耗了99%的时间。由于n2项在大多数情况下都起作用,因此我们可以消除其余两个项。
因此,
f(n)= 5n2
在这里,我们得到了近似的时间复杂度,其结果与实际结果非常接近。这种时间复杂度的近似度量称为渐进复杂度。在这里,我们没有计算确切的运行时间,我们正在消除不必要的术语,而我们只是在考虑花费大部分时间的术语。
在数学分析中,算法的渐近分析是定义其运行时性能的数学界限的一种方法。使用渐近分析,我们可以轻松得出算法的平均情况,最佳情况和最坏情况。
它用于数学计算算法内部任何操作的运行时间。
示例:一个操作的运行时间为x(n),而另一操作的运行时间计算为f(n2)。它指的是第一时间的运行时间将随着“ n”的增加而线性增加,而第二时间的运行时间将呈指数增长。同样,如果n很小,则两个操作的运行时间将相同。
通常,算法所需的时间分为以下三种:
最坏的情况:它定义了算法需要花费大量时间的输入。
平均情况:花费平均时间执行程序。
最佳情况:它定义算法所需时间最少的输入
渐近符号
下面给出了用于计算算法运行时间复杂度的常用渐近符号:
- 大哦符号(?)
- Ω表示法(Ω)
- θ符号(θ)
大哦记法(O)
- Big O表示法是一种渐进式表示法,通过简单地提供函数的增长顺序来衡量算法的性能。
- 该符号为函数提供了上限,以确保函数的增长永远不会快于上限。因此,它给出了函数的最小上限,因此该函数的增长永远不会比这个上限快。
这是表达算法运行时间上限的正式方法。它测量时间复杂度的最坏情况或算法完成操作所需的最长时间。如下图所示:

例如:
如果f(n)和g(n)是为正整数定义的两个函数,
则f(n)= O(g(n)),因为f(n)大g(n)或f(n)约g(n))如果存在常数c且不存在常数c :
对于所有n≥no,f(n)≤cg(n)
这意味着f(n)的增长不会快于g(n),或者g(n)是函数f(n)的上限。在这种情况下,我们正在计算最终计算函数,即算法如何执行最差的最坏时间复杂度函数的增长速度。
让我们通过例子来了解
例1:f(n)= 2n + 3,g(n)= n
现在,我们必须找到f(n)= O(g(n))?
要检查f(n)= O(g(n)),它必须满足给定条件:
f(n)<= cg(n)
首先,我们将f(n)替换为2n + 3,将g(n)替换为n。
2n + 3 <= cn
假设c = 5,那么n = 1
2 * 1 + 3 <= 5 * 1
5 <= 5
对于n = 1,上述条件为真。
如果n = 2
2 * 2 + 3 <= 5 * 2
7 <= 10
对于n = 2,上述条件为真。
我们知道,对于任何n值,它都满足上述条件,即2n + 3 <= cn如果c的值等于5,则它将满足条件2n + 3 <= cn从1开始的n值将始终满足。因此,我们可以说,对于某些常数c和某些常数n0,它将始终满足2n + 3 <= cn。因为它满足上述条件,所以f(n)大于g(n)哦,或者说f(n)线性增长。因此,可以得出结论cg(n)是f(n)的上限。它可以用图形表示为:
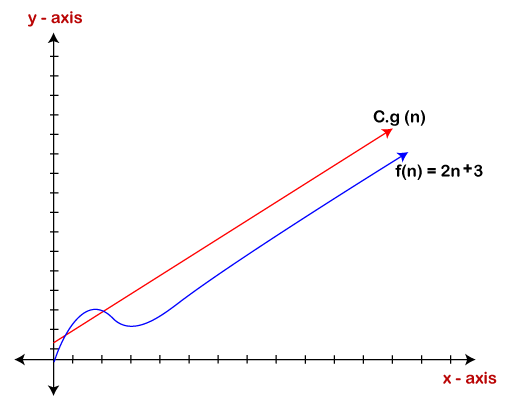
使用大符号的想法是给特定函数一个上限,最终导致最坏的时间复杂度。它可以确保特定函数不会突然表现为二次或三次形式,而是在最坏的情况下以线性方式表现。
Ω表示法(Ω)
- 它基本上描述了与大记号相反的最佳情况。
- 这是表示算法运行时间下限的正式方法。它测量算法完成可能花费的最佳时间或最佳情况下的时间复杂度。
- 它确定算法可以最快运行的时间。
如果我们要求算法至少花费一定的时间而不使用上限,则使用bigΩ表示法,即希腊字母“ omega”。它用于限制大输入量时运行时间的增长。
如果f(n)和g(n)是为正整数定义的两个函数,
然后f(n)=Ω(g(n)),因为f(n)是g(n)的Ω或f(n)处于g(n)的量级),如果存在常数c且不存在常数:
对于所有n≥no并且c> 0的f(n)> = cg(n)
让我们考虑一个简单的例子。
如果f(n)= 2n + 3,则g(n)= n,
f(n)=Ω(g(n))吗?
它必须满足以下条件:
f(n)> = cg(n)
为了检查上述条件,我们首先将f(n)替换为2n + 3,将g(n)替换为n。
2n + 3> = c * n
假设c = 1
2n + 3> = n(对于从1开始的n的任何值,此方程式均成立)。
因此,证明了g(n)是2n + 3函数的大Ω。
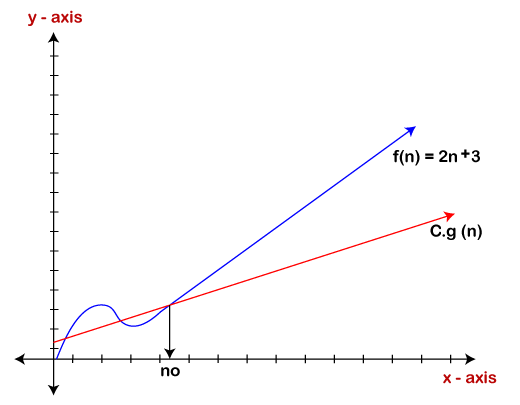
如上图所示,当c的值等于1时,g(n)函数是f(n)函数的下限。因此,该表示法给出了最快的运行时间。但是,我们对寻找最快的运行时间并不感兴趣,我们对计算最坏的情况感兴趣,因为我们想检查算法以获取更大的输入,这将是最坏的时间,以便我们可以采取进一步的措施在进一步流程中做出决定。
θ符号(θ)
- Theta符号主要描述平均情况。
- 它代表了算法的实际时间复杂度。每次,算法都不会执行最差或最好的情况,在实际问题中,算法主要在最坏情况和最佳情况之间波动,这为我们提供了算法的平均情况。
- 大theta主要在最差情况和最佳情况的值相同时使用。
- 这是表达算法运行时间的上限和下限的正式方法。
让我们从数学上理解大theta符号:
令f(n)和g(n)是n的函数,其中n是执行程序所需的步骤,然后:
f(n)=θg(n)
仅在以下情况下满足上述条件
c1.g(n)<= f(n)<= c2.g(n)
其中函数受两个限制(即上限和下限)限制,并且f(n)介于两者之间。当且仅当c1.g(n)小于或等于f(n)并且c2.g(n)大于或等于f(n)时,条件f(n)=θg(n)成立。 )。下面给出了theta符号的图形表示:
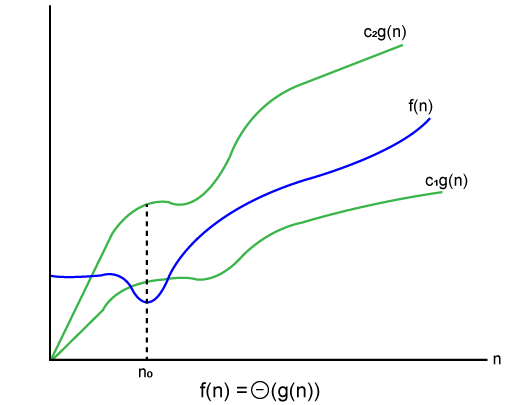
让我们考虑相同的示例,其中f(n)= 2n + 3 g(n)= n
由于c1.g(n)应小于f(n),因此c1必须为1,而c2.g(n)应大于f(n),因此c2等于5。c1.g(n)是f(n)的下限,而c2.g(n)是f(n)的上限。
c1.g(n)<= f(n)<= c2.g(n)
将g(n)替换为n,将f(n)替换为2n + 3
c1.n <= 2n + 3 <= c2.n
如果c1 = 1,c2 = 2,n = 1
1 * 1 <= 2 * 1 + 3 <= 2 * 1
1 <= 5 <= 2 //对于n = 1,它满足条件c1.g(n)<= f(n)<= c2.g(n)
如果n = 2
1 * 2 <= 2 * 2 + 3 <= 2 * 2
2 <= 7 <= 4 //对于n = 2,它满足条件c1.g(n)<= f(n)<= c2.g(n)
因此,可以说对于任何n值,它都满足条件c1.g(n)<= f(n)<= c2.g(n)。因此,证明f(n)是g(n)的大θ。因此,这是提供实际时间复杂度的平均情况。
为什么我们要进行三种不同的渐近分析?
我们知道,大欧米茄是最好的情况,大哦是最坏的情况,而大theta是普通的情况。现在,我们将找出线性搜索算法的平均,最差和最佳情况。
假设我们有一个n个数字的数组,我们想使用线性搜索在数组中找到特定的元素。在线性搜索中,在每次迭代中将每个元素与搜索到的元素进行比较。假设,如果仅在第一次迭代中找到匹配项,则最佳情况为Ω(1),如果元素与最后一个元素(即数组的第n个元素)匹配,则最差情况为O(n) 。平均情况是最佳情况和最坏情况的中间值,因此它变为θ(n / 1)。在时间复杂度中可以忽略常数项,因此平均情况为θ(n)。
因此,三种不同的分析提供了实际功能之间的适当界限。在这里,边界意味着我们有上限和下限,这可以确保算法仅在这些限制之间运行,即不会超出这些限制。
常见渐近符号
| constant | – | ?(1) |
| linear | – | ?(n) |
| logarithmic | – | ?(log n) |
| n log n | – | ?(n log n) |
| exponential | – | 2?(n) |
| cubic | – | ?(n3) |
| polynomial | – | n?(1) |
| quadratic | – | ?(n2) |