- Python词干和词法化
- Python词干和词法化(1)
- 词干python(1)
- 词干python代码示例
- Python|使用 NLTK 词干词干(1)
- Python|使用 NLTK 词干词干
- 词干简介(1)
- 词干简介
- 什么是Dart的词法范围和词法闭包
- 什么是Dart的词法范围和词法闭包(1)
- 词法范围 javascript 代码示例
- 从词法上讲C++中的下一个排列(1)
- 从词法上讲C++中的下一个排列(1)
- 从词法上讲C++中的下一个排列
- 从词法上讲C++中的下一个排列
- 在 jsx 中添加 if 词干 - Javascript (1)
- 在 jsx 中添加 if 词干 - Javascript 代码示例
- 标记、模式和词法
- 标记、模式和词法(1)
- Python | 用NLTK进行词干分析(1)
- Python | 用NLTK进行词干分析
- 词法分析简介(1)
- 词法分析简介
- 字符串的词法等级(1)
- 字符串的词法等级
- R 编程中的词法作用域
- R 编程中的词法作用域(1)
- 词法分析导论
- 词法分析导论(1)
📅 最后修改于: 2020-10-14 09:12:49 🧑 作者: Mango
什么是梗?
词干法是一种通过删除词缀来提取词的基本形式的技术。就像砍掉树枝到其茎上一样。例如,吃,吃,吃就是吃这句话。
搜索引擎使用词干为单词建立索引。这就是为什么搜索引擎只能存储词干而不是存储所有形式的单词。这样,词干可以减小索引的大小并提高检索精度。
多种词干算法
在NLTK中,具有stem()方法的stemmerI ,接口具有我们接下来要介绍的所有词干。让我们用下图来了解它
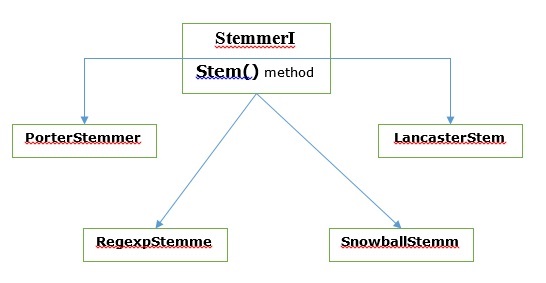
波特词干算法
它是最常见的词干提取算法之一,其基本目的是删除和替换众所周知的英语单词后缀。
PorterStemmer类
NLTK具有PorterStemmer类,借助该类,我们可以轻松地为想要词干的单词实现Porter Stemmer算法。此类知道几种常规的单词形式和后缀,借助它们可以将输入单词转换为最终词干。结果词干通常是具有相同词根含义的较短单词。让我们看一个例子-
首先,我们需要导入自然语言工具包(nltk)。
import nltk
现在,导入PorterStemmer类以实现Porter Stemmer算法。
from nltk.stem import PorterStemmer
接下来,如下创建Porter Stemmer类的实例-
word_stemmer = PorterStemmer()
现在,输入您要阻止的单词。
word_stemmer.stem('writing')
输出
'write'
word_stemmer.stem('eating')
输出
'eat'
完整的实施示例
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')
输出
'write'
Lancaster提取算法
它是由兰开斯特大学(Lancaster University)开发的,是另一种非常常见的词干算法。
LancasterStemmer类
NLTK具有LancasterStemmer类,借助该类,我们可以轻松地为想要词干的单词实现Lancaster Stemmer算法。让我们看一个例子-
首先,我们需要导入自然语言工具包(nltk)。
import nltk
现在,导入LancasterStemmer类以实现Lancaster Stemmer算法
from nltk.stem import LancasterStemmer
接下来,如下创建LancasterStemmer类的实例-
Lanc_stemmer = LancasterStemmer()
现在,输入您要阻止的单词。
Lanc_stemmer.stem('eats')
输出
'eat'
完整的实施示例
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')
输出
'eat'
正则表达式词干算法
借助这种词干算法,我们可以构建自己的词干搜索器。
RegexpStemmer类
NLTK具有RegexpStemmer类,借助它可以轻松实现正则表达式词干算法。它基本上采用单个正则表达式,并删除与该表达式匹配的任何前缀或后缀。让我们看一个例子-
首先,我们需要导入自然语言工具包(nltk)。
import nltk
现在,导入RegexpStemmer类以实现正则表达式Stemmer算法。
from nltk.stem import RegexpStemmer
接下来,创建RegexpStemmer类的实例,并提供您要从单词中删除的后缀或前缀,如下所示:
Reg_stemmer = RegexpStemmer(‘ing’)
现在,输入您要阻止的单词。
Reg_stemmer.stem('eating')
输出
'eat'
Reg_stemmer.stem('ingeat')
输出
'eat'
Reg_stemmer.stem('eats')
输出
'eat'
完整的实施示例
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')
输出
'eat'
雪球提取算法
这是另一个非常有用的词干算法。
SnowballStemmer类
NLTK拥有SnowballStemmer类,借助该类,我们可以轻松实现Snowball Stemmer算法。它支持15种非英语语言。为了使用此流化类,我们需要使用我们使用的语言名称创建一个实例,然后调用stem()方法。让我们看一个例子-
首先,我们需要导入自然语言工具包(nltk)。
import nltk
现在,导入SnowballStemmer类以实现Snowball Stemmer算法
from nltk.stem import SnowballStemmer
让我们看看它支持的语言-
SnowballStemmer.languages
输出
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)
接下来,使用您要使用的语言创建SnowballStemmer类的实例。在这里,我们正在创建“法语”语言的词干。
French_stemmer = SnowballStemmer(‘french’)
现在,调用stem()方法并输入要阻止的单词。
French_stemmer.stem (‘Bonjoura’)
输出
'bonjour'
完整的实施示例
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)
输出
'bonjour'
什么是合法化?
拔胶技术就像茎秆一样。词条定理后得到的输出称为“词条”,它是词根而不是词根,即词干的输出。进行定形后,我们将得到一个表示相同意思的有效单词。
NLTK提供了WordNetLemmatizer类,它是围绕wordnet语料库的薄包装。此类对WordNet CorpusReader类使用morphy()函数来查找引理。让我们通过一个例子来理解它-
例
首先,我们需要导入自然语言工具包(nltk)。
import nltk
现在,导入WordNetLemmatizer类以实现lemmatization技术。
from nltk.stem import WordNetLemmatizer
接下来,创建WordNetLemmatizer类的实例。
lemmatizer = WordNetLemmatizer()
现在,调用lemmatize()方法并输入要查找引理的单词。
lemmatizer.lemmatize('eating')
输出
'eating'
lemmatizer.lemmatize('books')
输出
'book'
完整的实施示例
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')
输出
'book'
词根和词法化之间的区别
通过以下示例,让我们了解词干和词法化之间的区别-
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')
输出
believ
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')
输出
believ
这两个程序的输出说明了词干和词根化之间的主要区别。 PorterStemmer类从单词中剔除“ es”。另一方面, WordNetLemmatizer类可找到有效单词。用简单的词来说,词干法只看单词的形式,而词干化技术则看词的含义。这意味着在应用完词后,我们将始终得到一个有效的单词。