- 数据结构|数组|问题2
- 数据结构 |数组 |问题 1(1)
- 数据结构|数组|问题1(1)
- 数据结构 |数组 |问题2
- 数据结构|数组|问题2(1)
- 数据结构 |数组 |问题2(1)
- 数据结构 |数组 |问题 1
- 数据结构|数组|问题1
- 堆数据结构
- 树数据结构(1)
- c++ 数据结构 - C++ (1)
- 堆数据结构
- 树数据结构
- 数据结构-图(1)
- 数据结构-树
- 堆数据结构(1)
- 数据结构 (1)
- C++数据结构(1)
- 数据结构-图
- C++数据结构
- 数据结构和算法-数组
- 数据结构和算法-数组(1)
- Python数据结构(1)
- Python数据结构
- c++ 数据结构 - C++ 代码示例
- 数据结构-图形数据结构(1)
- 数据结构-图形数据结构
- Java-数据结构
- Java-数据结构(1)
📅 最后修改于: 2020-10-15 00:39:33 🧑 作者: Mango
数组
定义
- 数组定义为存储在连续内存位置的相似类型数据项的集合。
- 数组是C编程语言中的派生数据类型,可以存储原始数据类型,例如int,char,double,float等。
- 数组是最简单的数据结构,其中每个数据元素都可以使用其索引号进行随机访问。
- 例如,如果我们想将一个学生的成绩存储在6个学科中,则无需为不同学科中的成绩定义不同的变量。取而代之的是,我们可以定义一个数组,该数组可以将标记存储在每个主题的连续存储位置中。
数组marks [10]定义了10个不同学科中学生的分数,每个学科的分数位于数组中的特定下标上,即marks [0]表示第一学科的分数,marks [1]表示第二学科的分数主题等等。
数组的属性
- 每个元素具有相同的数据类型,并具有相同的大小,即int = 4个字节。
- 数组的元素存储在连续的存储位置,第一个元素存储在最小的存储位置。
- 数组的元素可以随机访问,因为我们可以使用给定的基地址和数据元素的大小来计算数组的每个元素的地址。
例如,在C语言中,声明数组的语法如下:
int arr[10]; char arr[10]; float arr[5]
需要使用数组
在计算机编程中,大多数情况下需要存储大量相似类型的数据。为了存储如此大量的数据,我们需要定义大量的变量。在编写程序时记住所有变量的名称将非常困难。与其用不同的名称命名所有变量,不如定义一个数组并将所有元素存储到其中。
以下示例说明了数组如何在针对特定问题的代码编写中有用。
在下面的示例中,我们在六个不同学科上都有一个学生的成绩。该问题旨在计算学生所有分数的平均值。
为了说明数组的重要性,我们创建了两个程序,一个程序不使用数组,另一个程序使用数组存储标记。
没有数组的程序:
#include
void main ()
{
int marks_1 = 56, marks_2 = 78, marks_3 = 88, marks_4 = 76, marks_5 = 56, marks_6 = 89;
float avg = (marks_1 + marks_2 + marks_3 + marks_4 + marks_5 +marks_6) / 6 ;
printf(avg);
}
使用数组编程:
#include
void main ()
{
int marks[6] = {56,78,88,76,56,89);
int i;
float avg;
for (i=0; i<6; i++ )
{
avg = avg + marks[i];
}
printf(avg);
}
数组运算的复杂性
下表描述了各种阵列操作的时间和空间复杂度。
时间复杂度
| Algorithm | Average Case | Worst Case |
|---|---|---|
| Access | O(1) | O(1) |
| Search | O(n) | O(n) |
| Insertion | O(n) | O(n) |
| Deletion | O(n) | O(n) |
空间复杂度
在阵列中,最坏情况的空间复杂度为O(n)。
阵列的优点
- 数组为同一类型的变量组提供了唯一的名称,因此,很容易记住数组中所有元素的名称。
- 遍历数组是一个非常简单的过程,我们只需要增加数组的基地址即可逐个访问每个元素。
- 数组中的任何元素都可以使用索引直接访问。
阵列的内存分配
正如我们已经提到的,数组的所有数据元素都存储在主存储器中的相邻位置。数组的名称表示基地址或主存储器中第一个元素的地址。数组的每个元素都由适当的索引表示。
可以通过三种方式定义数组的索引。
- 0(从零开始的索引):数组的第一个元素将是arr [0]。
- 1(基于一个索引):数组的第一个元素将是arr [1]。
- n(基于n的索引):数组的第一个元素可以位于任何随机索引号处。
在下图中,我们显示了大小为5的数组arr的内存分配。该数组遵循基于0的索引方法。数组的基址为第100个字节。这将是arr [0]的地址。在这里,int的大小为4个字节,因此每个元素在内存中将占用4个字节。
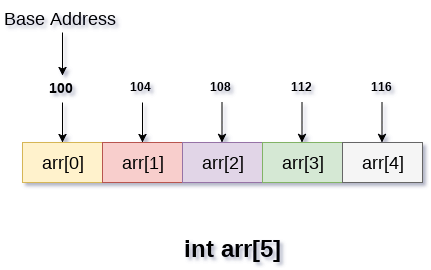
在基于0的索引中,如果数组的大小为n,则元素可以具有的最大索引数为n-1。但是,如果我们使用基于1的索引,它将为n。
访问数组的元素
要访问数组的任何随机元素,我们需要以下信息:
- 阵列的基址。
- 元素的大小(以字节为单位)。
- 数组遵循哪种类型的索引。
一维数组的任何元素的地址都可以使用以下公式计算:
Byte address of element A[i] = base address + size * ( i - first index)
范例:
In an array, A[-10 ..... +2 ], Base address (BA) = 999, size of an element = 2 bytes,
find the location of A[-1].
L(A[-1]) = 999 + [(-1) - (-10)] x 2
= 999 + 18
= 1017
将数组传递给函数:
如前所述,数组的名称表示数组的起始地址或第一个元素的地址。可以使用基地址遍历数组的所有元素。
以下示例说明如何将数组传递给函数。
例:
#include
int summation(int[]);
void main ()
{
int arr[5] = {0,1,2,3,4};
int sum = summation(arr);
printf("%d",sum);
}
int summation (int arr[])
{
int sum=0,i;
for (i = 0; i<5; i++)
{
sum = sum + arr[i];
}
return sum;
}
上面的程序定义了一个名为sumsum的函数,该函数接受一个数组作为参数。该函数计算数组中所有元素的总和并返回它。