根据哈佛商业评论,数据科学家是“21 世纪最性感的工作” 。这还不够了解更多数据科学吗!
介绍
在数据空间的世界中,当组织处理 PB 和 EB 的数据时,大数据时代就出现了。直到2010年,行业对于数据的存储变得非常艰难。现在,当Hadoop等流行框架解决存储问题时,重点是处理数据。在这里,数据科学发挥着重要作用。如今,数据科学的发展以各种方式增加,因此应该通过了解数据科学是什么以及我们如何为其增加价值来为未来做好准备。
什么是数据科学?
所以现在出现的第一个问题是,“什么是数据科学? ” 数据科学对不同的人意味着不同的东西,但从本质上讲,数据科学是使用数据来回答问题。这个定义是一个中等宽泛的定义,那是因为必须说数据科学是一个中等宽泛的领域!
Data science is the science of analyzing raw data using statistics and machine learning techniques with the purpose of drawing conclusions about that information.
简而言之,可以说数据科学涉及:
- 统计学、计算机科学、数学
- 数据清理和格式化
- 数据可视化
数据科学的关键支柱
通常,数据科学家来自不同的教育和工作经验背景,大多数应该精通,或者在理想情况下是四个关键领域的大师。
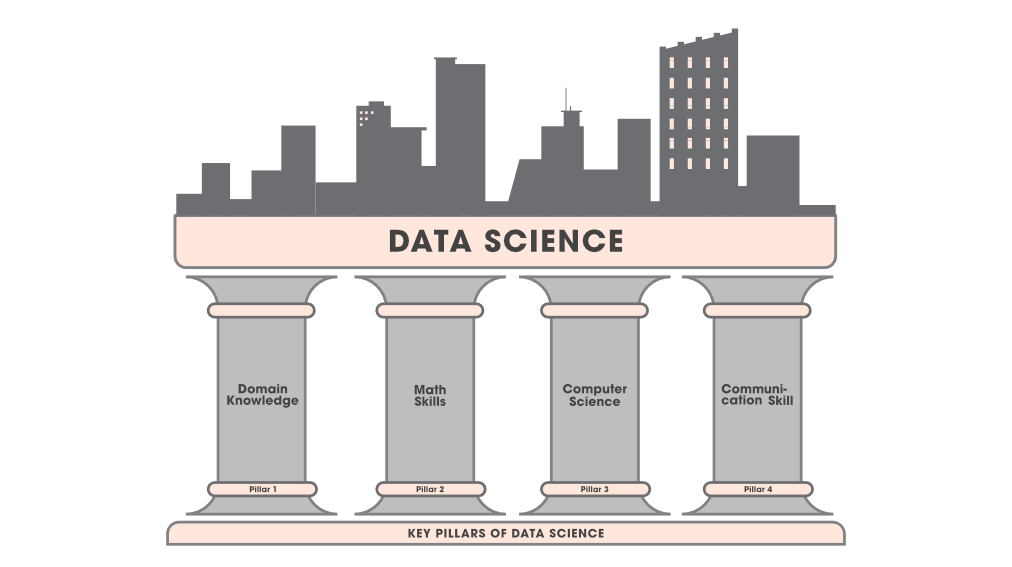
数据科学的支柱
- 领域知识:
- 大多数人认为领域知识在数据科学中并不重要,但它是必不可少的。数据科学的首要目标是从该数据中提取有用的见解,以便为公司的业务带来利润。如果您不了解公司的业务方面,即公司的商业模式如何运作以及您如何构建它,那么您对这家公司毫无用处。
- 您需要知道如何向正确的人提出正确的问题,以便您能够感知到获得所需信息所需的适当信息。在业务端使用了一些可视化工具,例如Tableau ,可帮助您以适当的非技术格式(例如业务人员可以理解的图形或饼图)显示您的宝贵结果或见解。
- 数学技能:
- 线性代数、多元微积分和优化技术:这三件事非常重要,因为它们有助于我们理解在数据科学中发挥重要作用的各种机器学习算法。
- 统计与概率:了解统计非常重要,因为这是数据分析的一部分。概率对于统计学也很重要,它被认为是掌握机器学习的先决条件。
- 计算机科学:
- 编程知识:需要掌握数据结构、算法等编程概念。使用的编程语言是Python、 R 、 Java、 Scala 。 C++在一些性能非常重要的地方也很有用。
- 关系数据库:需要了解SQL 或 Oracle等数据库,以便他/她可以在需要时从中检索必要的数据。
- 非关系型数据库:非关系型数据库有很多种,但最常用的类型是Cassandra、HBase、MongoDB、CouchDB、Redis、Dynamo。
- 机器学习:它是数据科学中最重要的部分之一,也是研究人员最热门的研究课题,因此每年都会在这方面取得新的进展。至少需要了解监督学习和无监督学习的基本算法。 Python和 R 中有多个库可用于实现这些算法。
- 分布式计算:处理大量数据也是最重要的技能之一,因为在单个系统上无法处理这么多数据。最常用的工具是Apache Hadoop 和 Spark 。这些收费的两个主要部分是HDFS(Hadoop 分布式文件系统) ,用于通过分布式文件系统收集数据。另一部分是map-reduce ,我们通过它来操作数据。可以在Java或Python程序中编写 map-reduce。还有各种其他工具,如PIG、HIVE等。
- 交流技能:
- 它包括书面和口头交流。在数据科学项目中发生的事情是在从分析中得出结论之后,该项目必须传达给其他人。有时,这可能是您发送给工作中的老板或团队的报告。其他时候它可能是一篇博客文章。通常,它可能是向一群同事进行的演示。无论如何,数据科学项目总是涉及项目发现的某种形式的交流。因此,成为数据科学家必须具备沟通技巧。
谁是数据科学家?
所以我们已经讨论了数据科学是什么以及数据科学的关键支柱,但我们还需要讨论的是数据科学家到底是谁?经济学人特别报告称,数据科学家被定义为:
“who integrates the skills of software programmer, statistician and storyteller slash artist to extract the nuggets of gold hidden under mountains of data”
但现在问题来了,数据科学家具备哪些技能?为了回答这个问题,让我们讨论流行的维恩图Drew Conway 的数据科学维恩图,其中数据科学是三个部门的交集——实质性专业知识、黑客技能以及数学和统计知识。
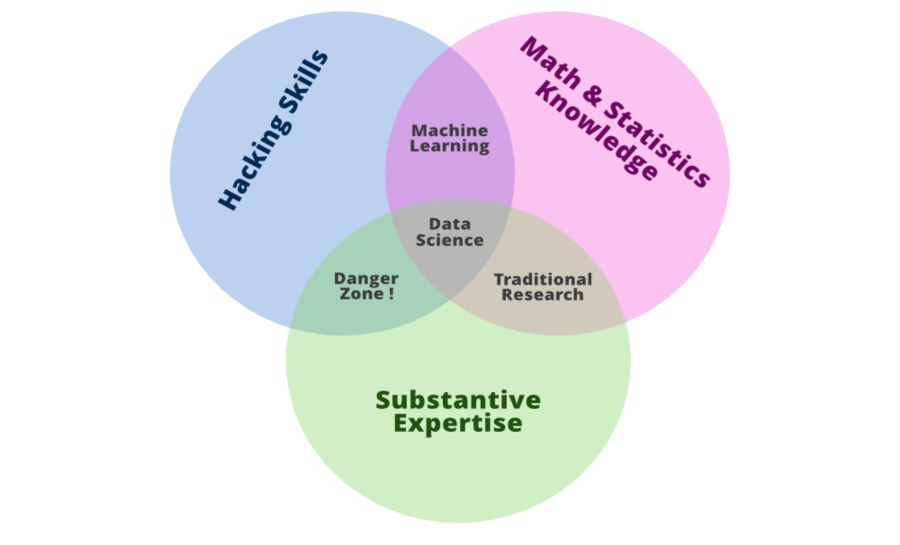
让我们稍微解释一下这个维恩图的意思,我们知道我们使用数据科学来回答问题——所以首先,我们需要在我们想要询问的领域有足够的经验,以便表达问题并理解什么样的数据与回答这个问题相关。一旦我们有了问题和相关数据,我们就会从数据科学所使用的数据类型中了解到,通常需要对其进行大量清理和格式化——这通常需要计算机编程技能。最后,一旦我们有了数据,我们就需要对其进行分析,这通常需要数学和统计知识。
数据科学家的角色和职责:
- 管理:数据科学家扮演着微不足道的管理角色,他支持在数据和分析领域内构建未来主义和技术能力的基础,以协助各种计划和持续的数据分析项目。
- 分析:数据科学家代表一个科学角色,他计划、实施和评估高级统计模型和策略,以便在业务最复杂的问题中应用。数据科学家为各种问题开发计量经济学和统计模型,包括预测、分类、聚类、模式分析、抽样、模拟等。
- 战略/设计:数据科学家在创新战略的推进中发挥着至关重要的作用,以了解企业的消费者趋势和管理以及解决困难业务问题的方法,例如优化产品履行和整体利润。
- 协作:数据科学家的角色不是一个单独的角色,在这个职位上,他与优秀的数据科学家合作,将障碍和发现传达给相关利益相关者,以努力提高业务绩效和决策制定。
- 知识:数据科学家还带头探索不同的技术和工具,以最灵活可行的速度为企业创建创新的数据驱动洞察力。在这种情况下,数据科学家还主动为业务评估和利用新的和增强的数据科学方法,并将其交付给高级管理层批准。
- 其他职责:数据科学家还执行高级数据科学家、数据科学主管、首席数据官或雇主分配的相关任务和任务。
数据科学家、数据分析师和数据工程师之间的区别:
数据科学家、数据工程师和数据分析师是数据科学中最常见的三个职业。因此,让我们通过将数据科学家与其类似的工作进行比较来了解谁是数据科学家。
|
Data Scientist |
Data Analyst |
Data Engineer |
|---|---|---|
| The focus will be on the futuristic display of data. | The main focus of a data analyst is on optimization of scenarios, for example how an employee can enhance the company’s product growth. | Data Engineers focus on optimization techniques and the construction of data in a conventional manner. The purpose of a data engineer is continuously advancing data consumption. |
| Data scientists present both supervised and unsupervised learning of data, say regression and classification of data, Neural networks, etc. | Data formation and cleaning of raw data, interpreting and visualization of data to perform the analysis and to perform the technical summary of data. | Frequently data engineers operate at the back end. Optimized machine learning algorithms were used for keeping data and making data to be prepared most accurately. |
| Skills required for Data Scientist are Python, R, SQL, Pig, SAS, Apache Hadoop, Java, Perl, Spark. | Skills required for Data Analyst are Python, R, SQL, SAS. | Skills required for Data Engineer are MapReduce, Hive, Pig Hadoop, techniques. |
一些鼓舞人心的数据科学家
通过查看数据科学家的例子,可以体现使用数据科学的各种领域。
- Hilary Mason :她是 FastForward labs 的联合创始人,这是一家机器学习公司,最近由数据科学公司Cloudera拥有。她是 Accel 的数据科学家。从广义上讲,她使用数据来解决有关挖掘网络的问题,并学习人们如何通过社交媒体相互交流的方法。
- Nate Silver:他是当今世界上最杰出的数据科学家或统计学家之一。他是 FiveThirtyEight 的创始人。 FiveThirtyEight 是一个应用统计分析来讲述有关选举、政治、体育、科学和生活方式的引人入胜故事的网站。他利用大量公共数据来预测各种主题;最突出的是,他预测谁将赢得美国大选,并且在准确性方面有着非凡的记录。
- 达里尔·莫雷:他是美国篮球队休斯顿火箭队的总经理。基于他的计算机科学学士学位和麻省理工学院的 MBA 学位,他被授予 GM 的职位
为什么我们需要数据科学?
近年来数据科学加速发展的原因之一是当前可用和正在生成的大量数据。不仅收集了关于世界和我们生活的许多方面的大量数据,而且我们同时还拥有廉价计算的兴起。这形成了一场完美的风暴,我们在其中拥有丰富的数据和分析工具。提高计算机内存容量、更强大的软件、更能干的处理器,现在,更多的数据科学家有能力使用这些技术并使用数据解决问题!
什么是大数据?
我们经常听到大数据这个词。所以它值得在这里介绍——因为它是数据科学兴起不可或缺的一部分。
大数据意味着什么?
大数据的字面意思是大量的数据。大数据是这一想法背后的支柱,即人们可以对大量数据进行有用的推断,而这在以前使用较小的数据集是不可能的。因此,可以通过计算分析极大的数据集,以揭示不透明或不易识别的模式、趋势和关联。
为什么每个人都对大数据感兴趣?
Big data is everywhere!
每次你上网并做一些收集数据的事情时,每次你从电子商务之一购买东西时,你的数据都会被收集。每当您去商店时,数据都是在销售点收集的,当您进行银行交易时,数据就在那里,当您访问 Facebook、Twitter 等社交网络时,这些数据都会被收集。现在,这些是更多的社会数据,但同样的事情开始发生在真正的工程工厂中。从世界各地的工厂收集实时数据。如果您正在进行更复杂的模拟,分子模拟,不仅会产生这些,还会生成大量的数据,这些数据也会被收集和存储。
大数据有多少数据?
- Google每天处理 20 PB (2008)
- Facebook拥有 2.5 PB 的用户数据 + 每天 15 TB(2009 年)
- eBay拥有 6.5 PB 的用户数据 + 每天 50 TB (2009)
- CERN 的大型强子对撞机 (LHC)每年产生 15 PB
为什么要做数据科学?
说到需求,对具有数据科学技能的个人有着巨大的需求。根据 LinkedIn 美国新兴就业报告,2020 年数据科学家排名第三,年增长率为 37%。该领域连续三年位居新兴工作岗位榜首。
此外,根据 Glassdoor 列出的美国前 50 名最令人满意的工作,数据科学家是 2020 年美国第三大工作,基于工作满意度(4.0/5)、薪水(107,801 美元)和需求。
所以这是进入数据科学的好时机——我们不仅有更多的数据,还有更多的收集、仓储和解释数据的工具,而且对数据科学家的需求正在不断增长,并且在许多领域被认为是必不可少的。不同的部门,而不仅仅是商业和学术界。
数据科学在行动!
数据科学在行动的一个著名例子是 2009 年,其中谷歌的一些研究人员分析了五年内 5000 万个常用搜索词,并将它们与CDC(疾病控制和预防中心)关于流感爆发的数据进行了比较。他们的目标是了解某些特定搜索是否与流感爆发相协调。
数据科学和大数据的优势之一是它可以区分相关性;在这种情况下,他们区分了45 个与 CDC 流感爆发数据有很强相关性的词。使用这些数据,他们能够仅根据通常的 Google 搜索来预测流感爆发!如果没有如此海量的数据,这 45 个词是无法提前预测的。
什么是数据?
由于我们已经花了一些时间讨论什么是数据科学,因此有必要花一些时间来了解数据究竟是什么。维基百科将数据定义为,
A set of values of qualitative or quantitative variables.
这个定义更侧重于数据意味着什么。尽管这是一个相当简短的定义。让我们花一点时间来解析它并分别关注每个组件。
- 一组值:第一个要关注的术语是“一组值” ——要获得数据,我们需要包含一组值。在统计学中,这组值被称为人口。例如,回答您的问题所需的那组值可能是所有网站或应用程序,也可能是所有获得特定药物的人或访问特定网站的人的集合。但一般来说,它是一组您将要对其进行测量的事物。
- 变量:接下来要关注的是“变量” ——变量是一个项目的度量或特征。例如,您可能正在测量一个人的体重,或者您正在估计一个人访问网站或应用程序的时间。或者它可能是您试图衡量的另一个定性特征,例如一个人在网站上点击了什么,或者您认为访问的人是男性还是女性。
- 定性和定量变量:最后,我们有“定性和定量变量”。定性变量是关于质量的信息。它们是诸如原籍国、性别、宗教等之类的东西。它们通常用文字而不是数字来表示,并且它们没有索引或排序。另一方面,定量变量是关于数量的信息。定量测量通常用数字表示,并按恒定的有序尺度进行估计;它们类似于体重、身高、年龄和血压。
数据科学的过程
一个完整的数据科学项目所涉及的部分是,

- 形成问题:每个数据科学项目都从一个要用数据回答的问题开始。这意味着“形成问题”是该过程中重要的第一步。从数据科学项目开始时,最好明确定义您的问题。执行分析时可能会出现更多问题,但了解分析需要回答的问题是非常重要的第一步。
- 查找或生成数据:第二步是“查找或生成数据”,您将使用它来回答该问题。可以以任何随机格式获得数据的生成。因此,根据选择的方法和要获得的输出,应验证收集的数据。因此,如果需要,可以收集更多数据或丢弃不相关的数据。
- 然后分析数据:随着问题的固化和数据的掌握,“然后分析数据”。这可以分两部分完成。
- 探索数据:在此步骤中,您将研究和预处理数据以进行建模。您将能够执行数据清理和可视化。这将有助于发现差异并在因素之间建立联系。完成该步骤后,就可以对其进行探索性分析了。
- 数据建模:在此步骤中,您将生成用于训练和测试目的的数据集。您可以解读分类、聚类等各种学习方法,最后完成最优秀的拟合技术来构建节目。简而言之,这意味着使用一些统计或机器学习技术来分析数据并回答您的问题。
- 与他人沟通:从分析得出结论后,项目必须“与他人沟通” 。任何数据科学项目的一个重要组成部分是充分描述项目的输出。有时,这是您发送给老板的报告,也可能是博客文章。
一些很酷的数据科学项目:
以下是一些很酷的数据科学项目。在每个项目中,作者都有一个问题,他们想解决这个问题。他们利用数据来解决这个问题。他们对数据进行了分析和可视化。然后,他们写了博客文章来传达他们的结果。看一看以了解有关主题的更多信息,并了解其他人如何完成数据科学项目并交付结果!
- 对特朗普推文的文本分析证实他只写了(愤怒的)Android 一半,作者:David Robinson
- 希拉里:希拉里帕克在美国历史上最毒的婴儿名字
- 在美国住哪里,作者:Maelle Salmon
- 多伦多的性健康诊所,作者:Sharla Gelfand
一些重要的统计见解
Stackoverflow 开发人员调查,2020 年 – 开发人员角色
根据 StackOverflow 开发人员调查,2020 年 – 开发人员角色,大约8.1%的受访者认为是数据科学家或机器学习专家。
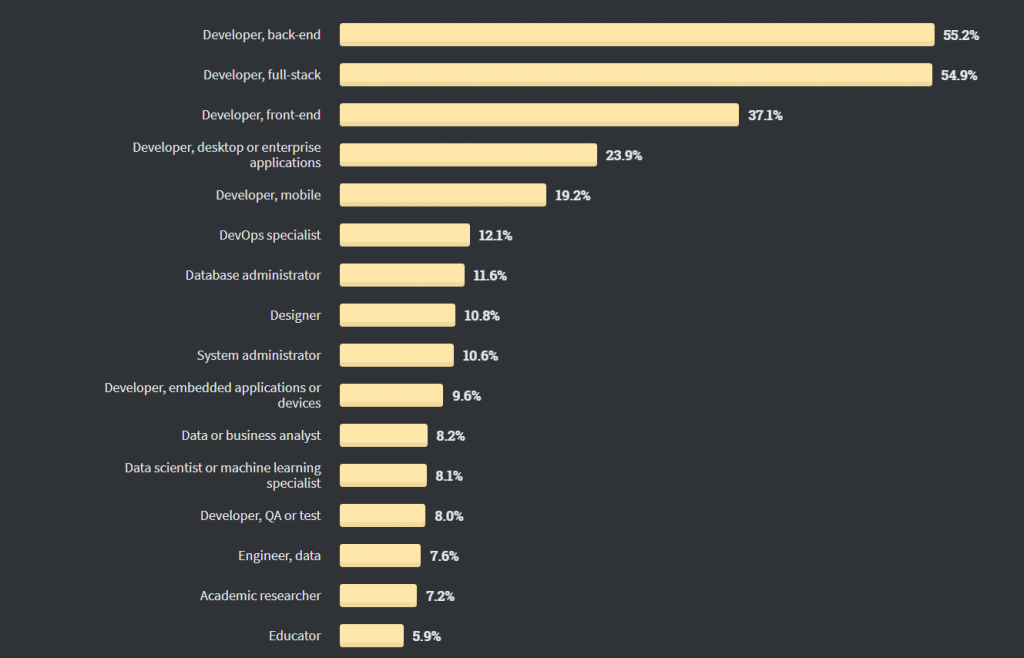
Stackoverflow 开发人员调查,2020 年 – 开发人员角色
2019 年最受欢迎的数据科学技能
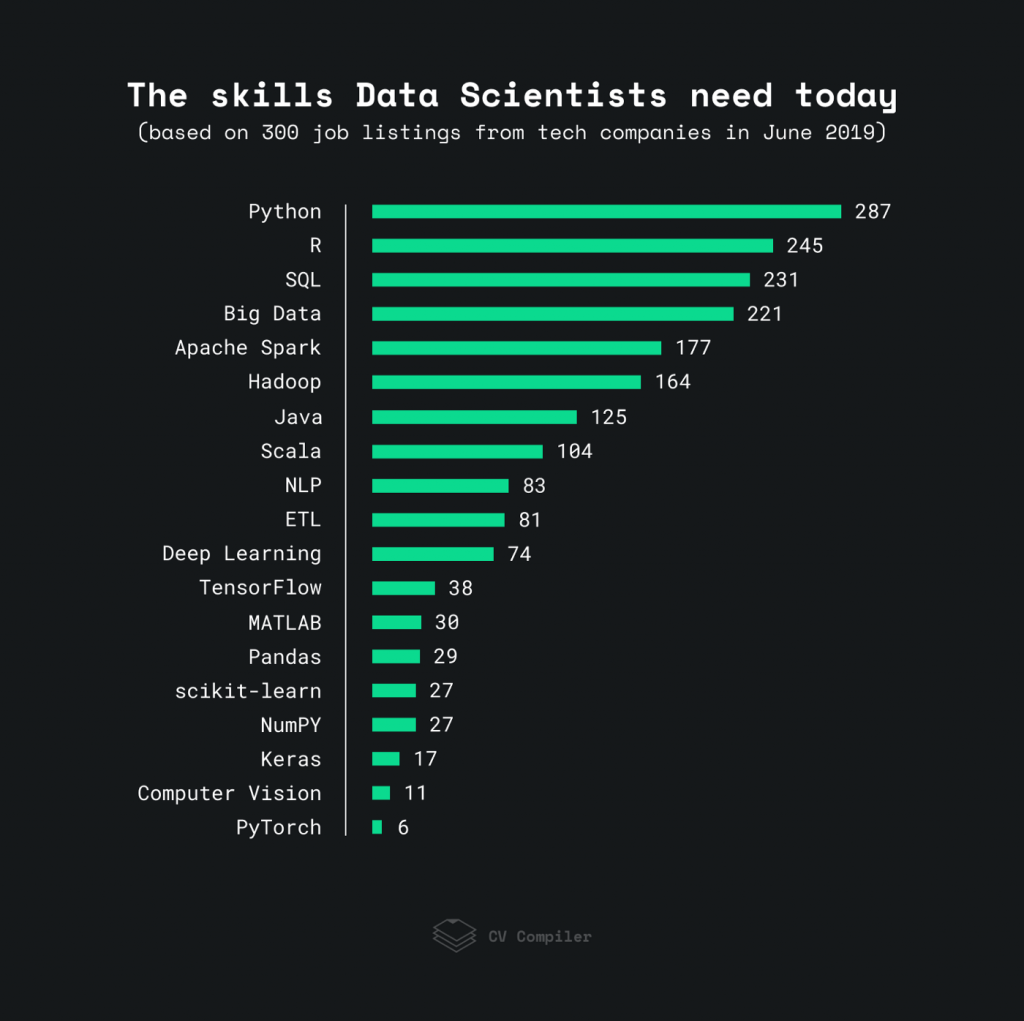
作为数据科学家如何变得更有市场