机器学习:正如本文所讨论的,机器学习只不过是一个研究领域,它允许计算机像人类一样“学习”,而无需任何显式编程。
什么是预测建模:预测建模是一个概率过程,它允许我们根据一些预测因子预测结果。这些预测器基本上是在决定最终结果(即模型的结果)时发挥作用的特征。
什么是降维?
在机器学习分类问题中,往往有太多的因素作为最终分类的依据。这些因素基本上是称为特征的变量。特征数量越多,将训练集可视化并对其进行处理就越困难。有时,这些特征中的大多数是相关的,因此是多余的。这就是降维算法发挥作用的地方。降维是通过获得一组主要变量来减少所考虑的随机变量数量的过程。可分为特征选择和特征提取。
为什么降维在机器学习和预测建模中很重要?
降维的直观例子可以通过一个简单的电子邮件分类问题来讨论,其中我们需要对电子邮件是否是垃圾邮件进行分类。这可能涉及大量特征,例如电子邮件是否具有通用标题、电子邮件的内容、电子邮件是否使用模板等。但是,其中一些特征可能会重叠.在另一种情况下,依赖于湿度和降雨量的分类问题可以被分解为一个基本特征,因为上述两个特征高度相关。因此,我们可以减少此类问题中的特征数量。 3-D 分类问题很难可视化,而 2-D 问题可以映射到简单的 2 维空间,而 1-D 问题可以映射到简单的线。下图说明了这个概念,其中一个 3-D 特征空间被分成两个 1-D 特征空间,然后,如果发现相关,特征的数量可以进一步减少。
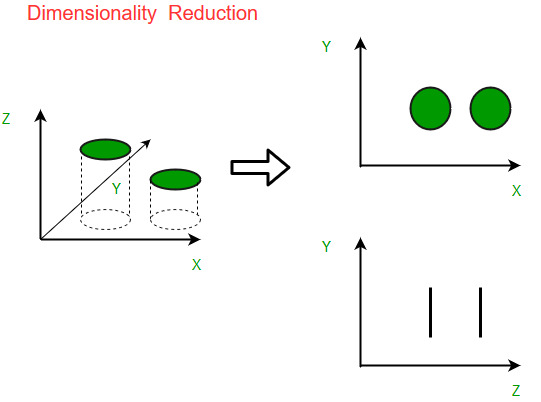
降维的组成部分
降维有两个组成部分:
- 特征选择:在这里,我们尝试找到原始变量或特征集的子集,以获得可用于对问题建模的较小子集。它通常包括三种方式:
- 筛选
- 包装器
- 嵌入式
- 特征提取:这将高维空间中的数据减少到较低维空间,即具有较小编号的空间。的维度。
降维方法
用于降维的各种方法包括:
- 主成分分析 (PCA)
- 线性判别分析 (LDA)
- 广义判别分析 (GDA)
降维可以是线性的也可以是非线性的,这取决于所使用的方法。下面讨论称为主成分分析或 PCA 的主要线性方法。
主成分分析
这种方法是由卡尔·皮尔逊 (Karl Pearson) 引入的。它的工作条件是,当高维空间中的数据映射到低维空间中的数据时,低维空间中数据的方差应该最大。
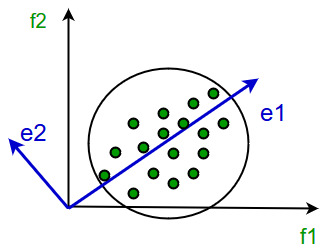
它包括以下步骤:
- 构造数据的协方差矩阵。
- 计算这个矩阵的特征向量。
- 对应于最大特征值的特征向量用于重建原始数据的大部分方差。
因此,我们留下的特征向量数量较少,并且在此过程中可能会丢失一些数据。但是,最重要的方差应该由剩余的特征向量保留。
降维的优势
- 它有助于数据压缩,从而减少存储空间。
- 它减少了计算时间。
- 它还有助于删除冗余功能(如果有)。
降维的缺点
- 它可能会导致一定数量的数据丢失。
- PCA 倾向于发现变量之间的线性相关性,这有时是不可取的。
- 在均值和协方差不足以定义数据集的情况下,PCA 会失败。
- 我们可能不知道要保留多少个主成分 – 在实践中,应用了一些拇指规则。