“计算机能够看到、听到和学习。欢迎来到未来。 ”
机器学习是未来。据福布斯报道,机器学习专利在 2013 年至 2017 年间以 34% 的速度增长,而且在未来一段时间内只会增加。此外,哈佛商业评论文章称数据科学家是“21 世纪最性感的工作”(这就是激励措施!!!)。
在这个高度动态的时代,开发了各种机器学习算法来解决复杂的现实世界问题。这些算法是高度自动化和自我修改的,因为它们随着时间的推移随着数据量的增加和所需的人工干预的减少而不断改进。所以这篇文章涉及Top 10 Machine Learning 算法。
但要理解这些算法,首先要简要说明它们可以属于的不同类型。

机器学习算法的类型 –
机器学习算法可以分为 3 种不同的类型,即:
监督机器学习算法:
想象一个老师在监督一个班级。老师已经知道正确的答案,但学习过程不会停止,直到学生也学会了答案(可怜的孩子!)。这是监督机器学习算法的本质。在这里,算法是从训练数据集中学习并做出由教师纠正的预测的学生。这个学习过程一直持续到算法达到所需的性能水平。
无监督机器学习算法:
在这种情况下,班上没有老师,让穷学生自己学习!这意味着对于无监督机器学习算法,没有具体的答案要学习,也没有老师。该算法在无人监督的情况下寻找数据中的底层结构,以便越来越多地了解数据本身。
强化机器学习算法:
好吧,这里假设学生随着时间的推移从他们自己的错误中学习(这就像生活!)。因此,强化机器学习算法通过反复试验来学习最佳动作。这意味着算法通过学习基于其当前状态的行为来决定下一步行动,这将最大化未来的奖励。
顶级机器学习算法
开发了特定的机器学习算法来处理复杂的现实世界数据问题。所以,既然我们已经看到了机器学习算法的类型,让我们研究一下现存的并且被数据科学家实际使用的顶级机器学习算法。
1.朴素贝叶斯分类器算法——
如果您必须手动对网页、文档或电子邮件等数据文本进行分类,会发生什么?好吧,你会发疯的!但幸运的是,这项任务是由朴素贝叶斯分类器算法执行的。该算法基于概率的贝叶斯定理(您可能在数学中读到过),它将元素值分配给可用类别之一的总体。
![]()
其中,y 是类变量,X 是依赖特征向量(大小为n ),其中:
![]()
朴素贝叶斯分类器算法使用的一个例子是电子邮件垃圾邮件过滤。 Gmail 使用此算法将电子邮件分类为垃圾邮件或非垃圾邮件。
2. K均值聚类算法——
假设您想在维基百科上搜索“日期”一词。现在,“约会”可以指一个水果,一个特定的日子,甚至是与您的爱人度过的浪漫夜晚!!!因此,维基百科使用 K 均值聚类算法(因为它是一种流行的聚类分析算法)对讨论相同想法的网页进行分组。
K 均值聚类算法通常使用 K 个聚类对给定的数据集进行操作。以这种方式,输出包含 K 个簇,输入数据在簇之间进行分区(因为具有不同“日期”含义的页面被分区)。
3.支持向量机算法——
支持向量机算法用于分类或回归问题。在这种情况下,通过找到将数据集分成多个类的特定线(超平面)将数据分为不同的类。支持向量机算法试图找到最大化类之间距离(称为边际最大化)的超平面,因为这增加了更准确地对数据进行分类的概率。
支持向量机算法使用的一个例子是比较同一行业股票的股票表现。这有助于管理金融机构的投资决策。
4. Apriori 算法 –
Apriori 算法使用 IF_THEN 格式生成关联规则。这意味着如果事件 A 发生,那么事件 B 也会以一定的概率发生。例如:如果一个人买了一辆汽车,那么他们也购买了汽车保险。 Apriori 算法通过观察购买汽车后购买汽车保险的人数来生成此关联规则。
Apriori 算法用法的一个示例是 Google 自动完成。当在 Google 中键入一个词时,Apriori 算法会查找通常在该词之后键入的关联词并显示可能性。
5. 线性回归算法——
线性回归算法显示了自变量和因变量之间的关系。它展示了当自变量以任何方式改变时对因变量的影响。因此,自变量称为解释变量,因变量称为感兴趣因子。

线性回归算法使用的一个例子是保险领域的风险评估。线性回归分析可用于找出多个年龄的客户的索赔数量,然后推断随着客户年龄的增加而增加的风险。
6.逻辑回归算法——
Logistic 回归算法处理离散值,而线性回归算法处理连续值的预测。因此,逻辑回归适用于二元分类,其中如果事件发生,则将其归类为 1,否则,将其归类为 0。因此,特定事件发生的概率是基于给定的预测变量来预测的。

Logistic 回归算法使用的一个例子是在政治中预测特定候选人是否会赢得或失去政治选举。
7. 决策树算法——
假设您要决定生日的地点。所以有很多问题会影响你的决定,比如“这家餐厅是意大利餐厅吗?”、“餐厅有现场音乐吗?”、“餐厅离你家近吗?”等等。这些问题中的每一个都有一个是或否的答案,这有助于您的决定。
这就是决策树算法中发生的基本情况。此处使用树分支方法显示决策的所有可能结果。内部节点是对各种属性的测试,树的分支是测试的结果,叶节点是在计算所有属性后做出的决定。
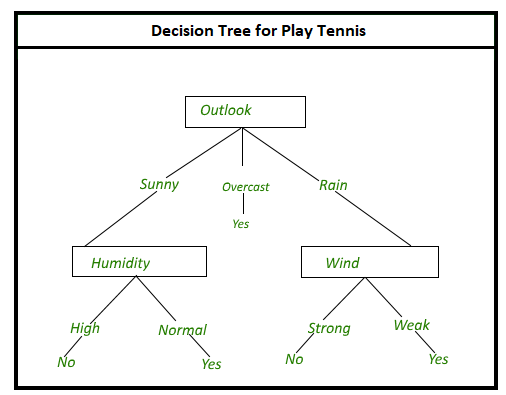
决策树算法使用的一个例子是在银行业中,根据贷款申请人拖欠所述贷款付款的可能性对他们进行分类。
8. 随机森林算法——
随机森林算法处理了决策树算法的一些局限性,即当树中的决策数量增加时,结果的准确性会降低。
所以,在随机森林算法中,有多个决策树代表各种统计概率。所有这些树都映射到称为 CART 模型的单个树。 (分类和回归树)。最后,随机森林算法的最终预测是通过轮询所有决策树的结果得到的。
随机森林算法使用的一个例子是在汽车行业中预测任何特定汽车零件的未来故障。
9. K 最近邻算法 –
K 最近邻算法根据距离函数等类似度量将数据点划分为不同的类。然后通过在整个数据集中搜索 K 个最相似的实例(邻居)并总结这些 K 个实例的输出变量,对新数据点进行预测。对于回归问题,这可能是结果的平均值,对于分类问题,这可能是众数(最常见的类)。
K 最近邻算法可能需要大量内存或空间来存储所有数据,但仅在需要预测时及时执行计算(或学习)。
10.人工神经网络算法——
人脑包含神经元,这些神经元是我们保持能力和敏锐智慧的基础(至少对我们中的一些人来说!)因此人工神经网络试图通过创建相互连接的节点来复制人脑中的神经元。这些神经元通过另一个神经元接收信息,根据需要执行各种动作,然后将信息作为输出传递给另一个神经元。
人工神经网络的一个例子是人脸识别。可以识别人脸图像并将其与“非面部”图像区分开来。然而,这可能需要几个小时,具体取决于数据库中的图像数量,而人类大脑可以立即完成。