在这里,我们将编写一个 Map-Reduce 程序来分析天气数据集,以了解其数据处理编程模型。天气传感器正在通过大量日志数据收集全球的天气信息。这种天气数据是半结构化的,以记录为导向。
此数据以面向行的 ASCII 格式存储,其中每一行代表一条记录。每行都有很多字段,如经度、纬度、每日最高-最低温度、每日平均温度等,为方便起见,我们将重点关注主要元素,即温度。我们将使用来自国家环境信息中心 (NCEI) 的数据。它拥有大量的历史天气数据,我们可以将其用于数据分析。
问题陈述:
Analyzing weather data of Fairbanks, Alaska to find cold and hot days using MapReduce Hadoop.第1步:
我们可以从这个链接下载数据集,对于不同年份的不同城市。选择您选择的年份并选择任何一个数据文本文件进行分析。就我而言,我选择了CRND0103-2020-AK_Fairbanks_11_NE.txt数据集来分析阿拉斯加费尔班克斯的冷热天。
我们可以从 NCEI 网站上提供的README.txt文件中获取有关数据的信息。
第2步:
下面是我们的数据集示例,其中第 6 列和第 7 列分别显示最高和最低温度。

第 3 步:
在 Eclipse 中创建一个项目,步骤如下:
- 首先打开Eclipse -> 然后选择File -> New -> Java Project -> Name it MyProject -> 然后选择use an execution environment -> 选择JavaSE-1.8然后next -> Finish 。
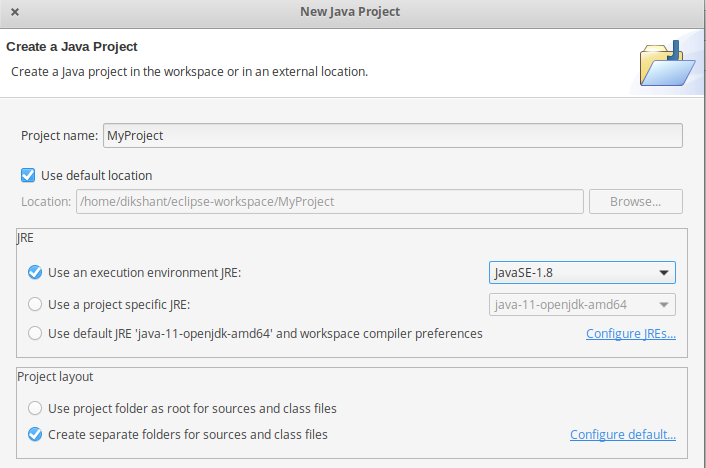
- 在此项目中创建名为MyMaxMin 的Java类 -> 然后单击完成
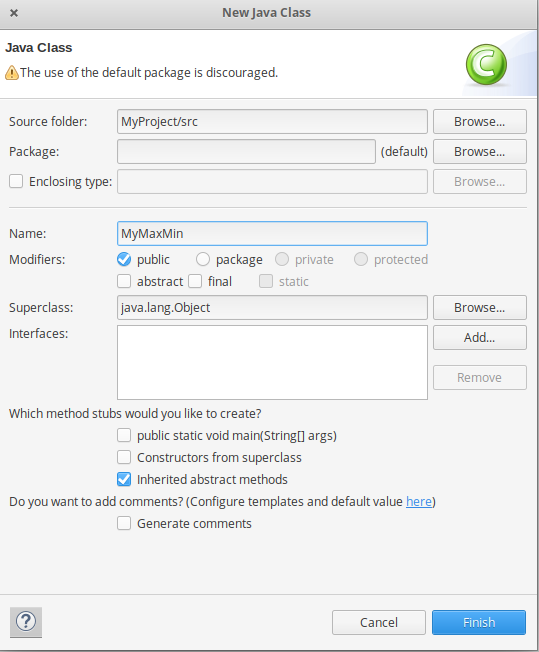
- 将下面的源代码复制到这个MyMaxMin Java类
// importing Libraries import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.conf.Configuration; public class MyMaxMin { // Mapper /*MaxTemperatureMapper class is static * and extends Mapper abstract class * having four Hadoop generics type * LongWritable, Text, Text, Text. */ public static class MaxTemperatureMapper extends MapperValues, Context context) throws IOException, InterruptedException { // putting all the values in // temperature variable of type String String temperature = Values.next().toString(); context.write(Key, new Text(temperature)); } } /** * @method main * This method is used for setting * all the configuration properties. * It acts as a driver for map-reduce * code. */ public static void main(String[] args) throws Exception { // reads the default configuration of the // cluster from the configuration XML files Configuration conf = new Configuration(); // Initializing the job with the // default configuration of the cluster Job job = new Job(conf, "weather example"); // Assigning the driver class name job.setJarByClass(MyMaxMin.class); // Key type coming out of mapper job.setMapOutputKeyClass(Text.class); // value type coming out of mapper job.setMapOutputValueClass(Text.class); // Defining the mapper class name job.setMapperClass(MaxTemperatureMapper.class); // Defining the reducer class name job.setReducerClass(MaxTemperatureReducer.class); // Defining input Format class which is // responsible to parse the dataset // into a key value pair job.setInputFormatClass(TextInputFormat.class); // Defining output Format class which is // responsible to parse the dataset // into a key value pair job.setOutputFormatClass(TextOutputFormat.class); // setting the second argument // as a path in a path variable Path OutputPath = new Path(args[1]); // Configuring the input path // from the filesystem into the job FileInputFormat.addInputPath(job, new Path(args[0])); // Configuring the output path from // the filesystem into the job FileOutputFormat.setOutputPath(job, new Path(args[1])); // deleting the context path automatically // from hdfs so that we don't have // to delete it explicitly OutputPath.getFileSystem(conf).delete(OutputPath); // exiting the job only if the // flag value becomes false System.exit(job.waitForCompletion(true) ? 0 : 1); } } - 现在我们需要为我们导入的包添加外部 jar。根据你的Hadoop版本下载Hadoop Common和Hadoop MapReduce Core的jar包。
您可以检查 Hadoop 版本:
hadoop version
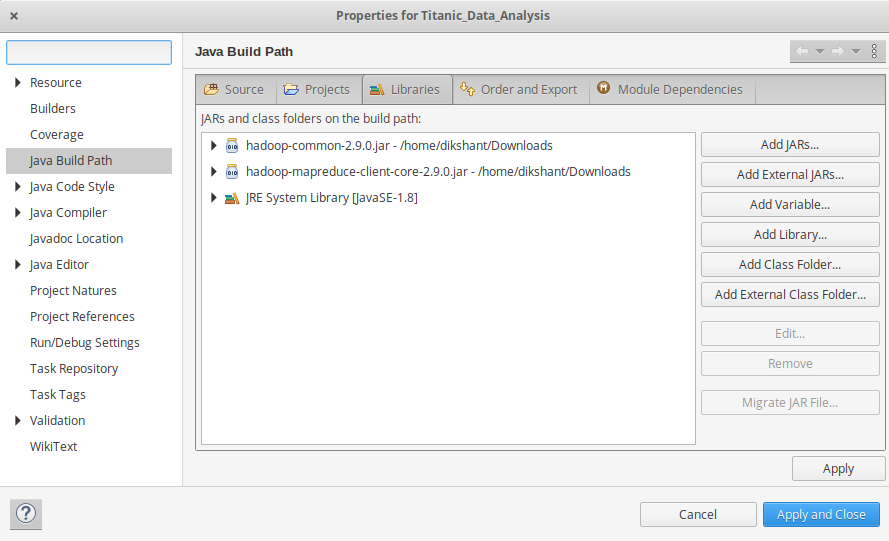
- 现在我们将这些外部 jars 添加到我们的MyProject 中。右键单击MyProject -> 然后选择Build Path -> 单击Configue Build Path并选择Add External jars…。并从它的下载位置添加 jars 然后单击 -> Apply and Close 。
- 现在将项目导出为 jar 文件。右键单击MyProject选择Export..并转到Java -> JAR 文件单击 -> Next并选择导出目标,然后单击 -> Next 。
通过单击 -> Browse选择 Main Class 作为MyMaxMin ,然后单击 -> Finish -> Ok 。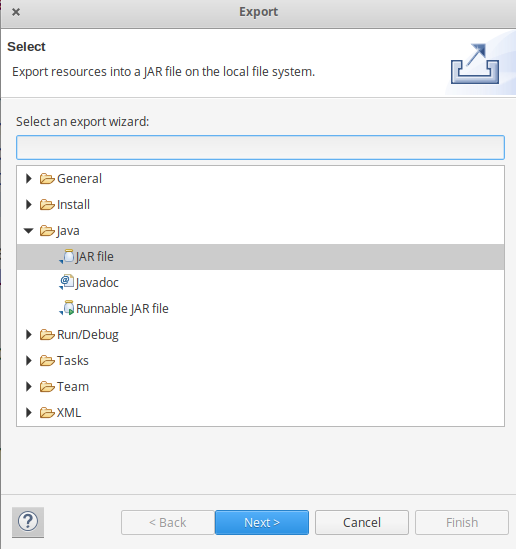
第四步:
启动我们的 Hadoop 守护进程
start-dfs.sh
start-yarn.sh
第 5 步:
将您的数据集移动到 Hadoop HDFS。
句法:
hdfs dfs -put /file_path /destination
在下面的命令中/显示了我们 HDFS 的根目录。
hdfs dfs -put /home/dikshant/Downloads/CRND0103-2020-AK_Fairbanks_11_NE.txt /
检查发送到我们 HDFS 的文件。
hdfs dfs -ls /

第 6 步:
现在使用以下命令运行您的 Jar 文件并在MyOutput文件中生成输出。
句法:
hadoop jar /jar_file_location /dataset_location_in_HDFS /output-file_name
命令:
hadoop jar /home/dikshant/Documents/Project.jar /CRND0103-2020-AK_Fairbanks_11_NE.txt /MyOutput

第 7 步:
现在移至localhost:50070/ ,在实用程序下选择Browse the file system并在/MyOutput目录中下载part-r-00000以查看结果。


第 8 步:
在下载的文件中查看结果。
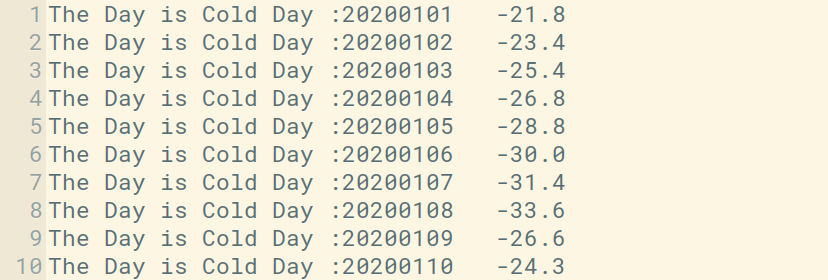
在上图中,您可以看到显示寒冷天气的前 10 个结果。第二列是 yyyy/mm/dd 格式的一天。例如, 20200101表示
year = 2020
month = 01
Date = 01