Map-Reduce 是一种编程模型,用于处理 Hadoop 中分布式系统上的大型数据集。 Map阶段和Reduce阶段是任何Map-Reduce作业的主要两个重要部分。 Map-Reduce 应用程序受到集群上可用带宽的限制,因为数据从 Mapper 移动到 Reducer。
例如,如果我们的集群中有 1 GBPS(每秒千兆位)的网络,并且我们正在处理数百 PB(Peta 字节)范围内的数据。以超过 1GBPS 的速度移动如此大的数据集需要花费大量时间来处理。组合器用于通过最小化在 Map 和 Reduce 之间混洗的数据来解决这个问题。
在本文中,我们将介绍 Map-Reduce 中的 Combiner,涵盖以下所有方面。
- 什么是合路器?
- 合路器的工作原理
- 合路器的优势
- 合路器的缺点
什么是合路器?
组合器总是在 Mapper 和 Reducer 之间工作。 Mapper 产生的输出是键值对的中间输出,其大小很大。如果我们直接将这个巨大的输出提供给 Reducer,那么这将导致网络拥塞增加。因此,为了尽量减少这种网络拥塞,我们必须在 Mapper 和 Reducer 之间放置组合器。这些组合器也称为半减速器。没有必要向 Map-Reduce 程序添加组合器,它是可选的。组合器也是我们Java程序中的一个类,就像Map和Reduce类,用于这个Map和Reduce类之间。组合器帮助我们生成抽象的细节或非常大的数据集的摘要。当我们处理或处理非常大的数据集时,使用Hadoop Combiner是非常有必要的,从而导致整体性能的提升。
合路器是如何工作的?
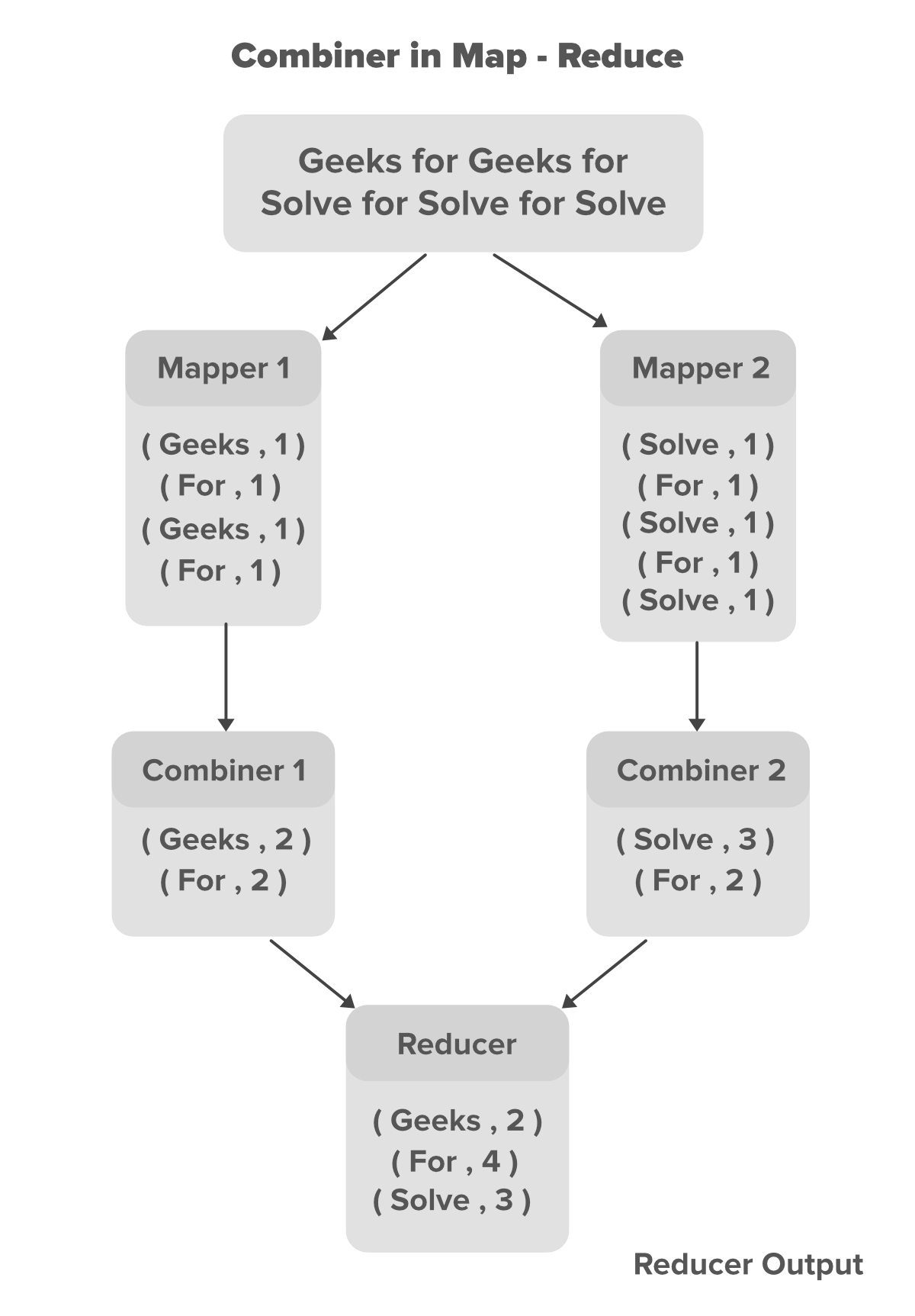
在上面的例子中,我们可以看到两个 Mapper 包含不同的数据。主文本文件分为两个不同的映射器。每个映射器都被分配来处理我们数据的不同行。在我们上面的例子中,我们有两行数据,所以我们有两个映射器来处理每一行。映射器正在生成中间键值对,其中特定单词的名称是键,其计数是它的值。例如对于数据Geeks For Geeks 对于键值对如下所示。
// Key Value pairs generated for data Geeks For Geeks For
(Geeks,1)
(For,1)
(Geeks,1)
(For,1)
Mapper 生成的键值对称为中间键值对或 Mapper 的中间输出。现在我们可以通过在我们的程序中为每个 Mapper 引入一个组合器来最小化这些键值对的数量。在我们的例子中,我们有 4 个由每个 Mapper 生成的键值对。由于这些中间键值对还没有准备好直接提供给 Reducer,因为这会增加网络拥塞,因此Combiner将在将它们发送到 Reducer 之前组合这些中间键值对。组合器根据它们的key组合这些中间键值对。对于上面的数据示例Geeks For Geeks For combiner 将通过根据它们的键值合并相同的对来部分减少它们,并生成新的键值对,如下所示。
// Partially reduced key-value pairs with combiner
(Geeks,2)
(For,2)
在Combiner 的帮助下,Mapper 输出的大小(键值对)部分减少,现在可以将其提供给Reducer 以获得更好的性能。现在,Reducer 将再次减少从组合器获得的输出,并生成存储在 HDFS(Hadoop 分布式文件系统)上的最终输出。
合路器的优势
- 减少将数据从 Mapper 传输到 Reducer 所需的时间。
- 减少 Mapper 生成的中间输出的大小。
- 通过最小化网络拥塞来提高性能。
合路器的缺点
- Mappers 生成的中间键值对存储在本地磁盘上,稍后将运行组合器以部分减少输出,从而导致昂贵的磁盘输入输出。
- map-Reduce 作业不能依赖于combiner 的函数,因为它的执行没有这样的保证。