MapReduce 和 HDFS 是 Hadoop 的两个主要组件,这使其使用起来非常强大和高效。 MapReduce 是一种编程模型,用于以分布式方式并行处理大型数据集。数据首先被拆分,然后组合以产生最终结果。 MapReduce 的库是用多种编程语言编写的,并进行了各种不同的优化。 Hadoop 中 MapReduce 的目的是映射每个作业,然后将其减少为等效的任务,以减少集群网络上的开销并降低处理能力。 MapReduce 任务主要分为 Map Phase 和 Reduce Phase 两个阶段。
MapReduce 架构:
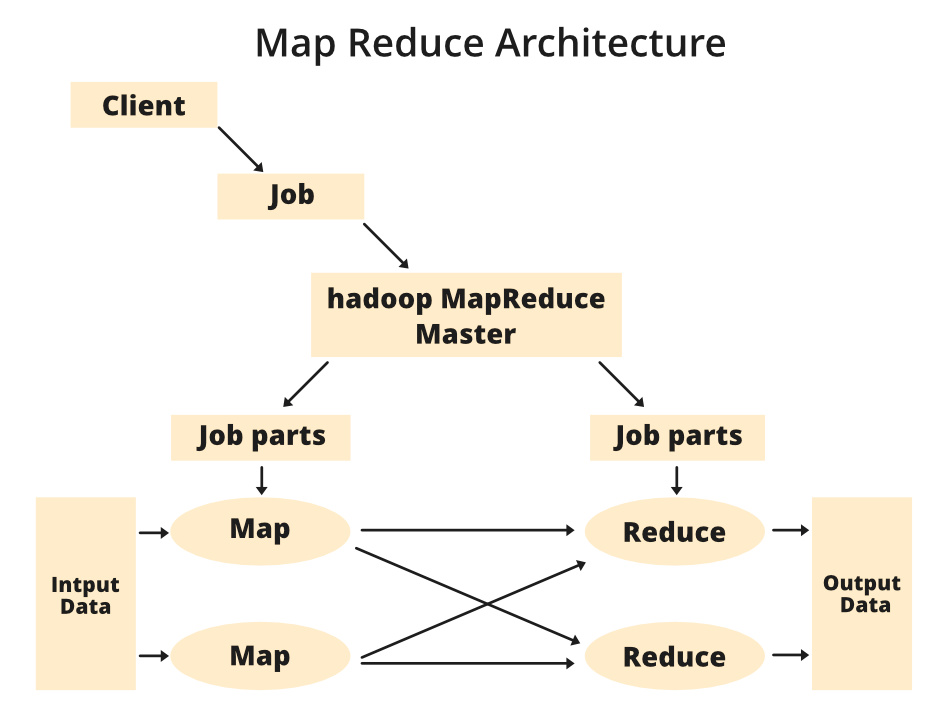
MapReduce 架构的组件:
- 客户端: MapReduce 客户端是将 Job 带到 MapReduce 进行处理的客户端。可以有多个客户端连续发送作业到 Hadoop MapReduce 管理器进行处理。
- 作业: MapReduce 作业是客户端想要做的实际工作,它由客户端想要处理或执行的许多小任务组成。
- Hadoop MapReduce Master:它将特定作业划分为后续作业部分。
- Job-Parts:主作业分工后得到的任务或子作业。所有作业部分的结果结合起来产生最终输出。
- 输入数据:提供给 MapReduce 进行处理的数据集。
- 输出数据:处理后得到最终结果。
在MapReduce 中,我们有一个客户端。客户端将特定大小的作业提交给 Hadoop MapReduce Master。现在,MapReduce master 将把这个工作分成更多等价的工作部分。然后,这些作业部分可用于 Map 和 Reduce 任务。这个 Map and Reduce 任务将根据特定公司正在解决的用例的要求包含程序。开发人员编写他们的逻辑来满足行业要求。我们使用的输入数据然后被馈送到 Map 任务,Map 将生成中间键值对作为其输出。 Map 的输出,即这些键值对,然后被馈送到 Reducer,最终输出存储在 HDFS 上。根据需要,可以有 n 个 Map 和 Reduce 任务可用于处理数据。 Map和Reduce的算法采用非常优化的方式,使得时间复杂度或空间复杂度最小。
让我们讨论 MapReduce 阶段以更好地了解其架构:
MapReduce 任务主要分为2 个阶段,即Map 阶段和Reduce 阶段。
- Map:顾名思义,它的主要用途是以键值对的形式映射输入数据。映射的输入可能是一个键值对,其中键可以是某种地址的 id,值是它保留的实际值。 Map()函数将在其内存存储库中对每个输入键值对执行,并生成中间键值对,用作 Reducer 或Reduce()函数。
- Reduce:作为 Reducer 输入的中间键值对被打乱并排序并发送到Reduce()函数。 Reducer 根据开发人员编写的 reducer 算法,根据其键值对对数据进行聚合或分组。
作业跟踪器和任务跟踪器如何处理 MapReduce:
- Job Tracker:Job Tracker的工作是管理集群中的所有资源和所有作业,并调度 Task Tracker 上运行在同一数据节点上的每个地图,因为集群中可能有数百个数据节点可用。
- 任务跟踪器:任务跟踪器可以被认为是按照作业跟踪器给出的指令工作的实际奴隶。这个 Task Tracker 部署在集群中每个可用节点上,这些节点按照 Job Tracker 的指示执行 Map 和 Reduce 任务。
MapReduce 架构中还有一个重要组件,称为Job History Server 。 Job History Server 是一个守护进程,用于保存和存储有关任务或应用程序的历史信息,例如作业执行期间或之后生成的日志存储在 Job History Server 上。