要在 Windows 10 中以伪分布式模式执行设置和安装 Hadoop,请使用下面给出的以下步骤。让我们一一讨论。
第 1 步:下载二进制包:
从以下站点下载最新的二进制文件,如下所示。
http://hadoop.apache.org/releases.html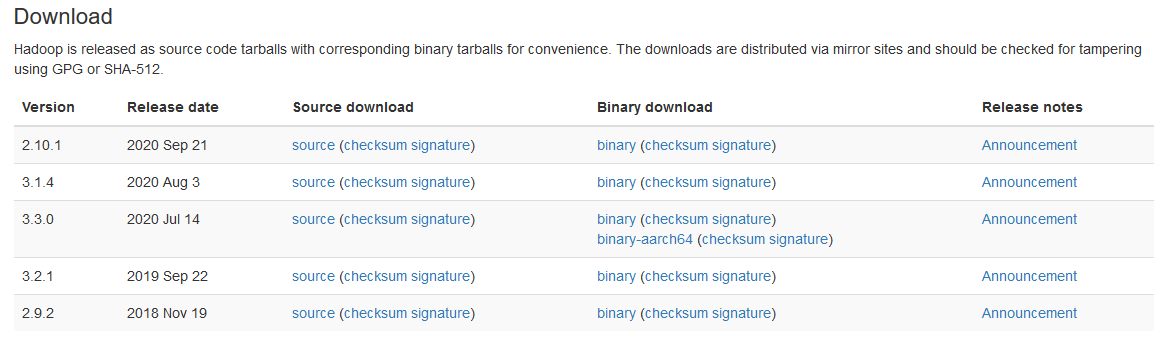
作为参考,您可以检查保存到文件夹中的文件,如下所示。
C:\BigData第二步:解压二进制包
打开Git Bash,将目录(cd)切换到你保存二进制包的文件夹,然后解压如下。
$ cd C:\BigData
MINGW64: C:\BigData
$ tar -xvzf hadoop-3.1.2.tar.gz对于我的情况,Hadoop 的双重性被解压缩到 C:\BigData\hadoop-3.1.2。
接下来,转到此 GitHub Repo 并以如下所示的速度下载容器管理器。集中压缩并将容器信封下的所有文件复制到 C:\BigData\hadoop-3.1.2\bin。也补充当前记录。
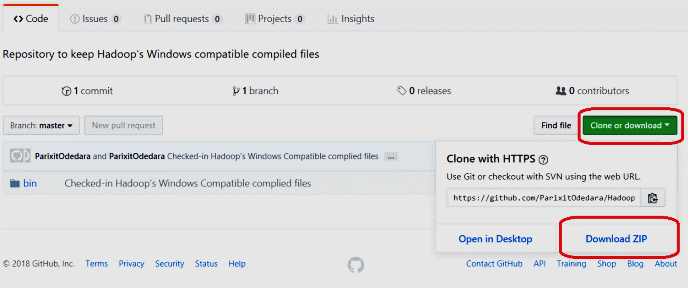
第 3 步:为 datanode 和 namenode 创建文件夹:
- 转到 C:/BigData/hadoop-3.1.2 并制作一个组织者“信息”。在“信息”信封内制作两个组织者“datanode”和“namenode”。您在 HDFS 上的文档将位于 datanode 信封下。
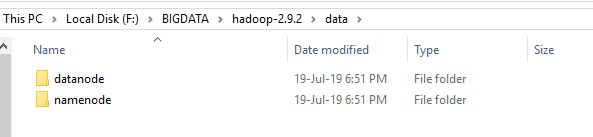
- 设置 Hadoop 环境变量
- Hadoop 需要设置以下环境变量。
HADOOP_HOME=” C:\BigData\hadoop-3.1.2”
HADOOP_BIN=”C:\BigData\hadoop-3.1.2\bin”
JAVA_HOME=” - 要设置这些变量,请导航到“我的电脑”或“这台电脑”。
Right-click -> Properties -> Advanced System settings -> Environment variables. - 单击新建以创建新的环境变量。
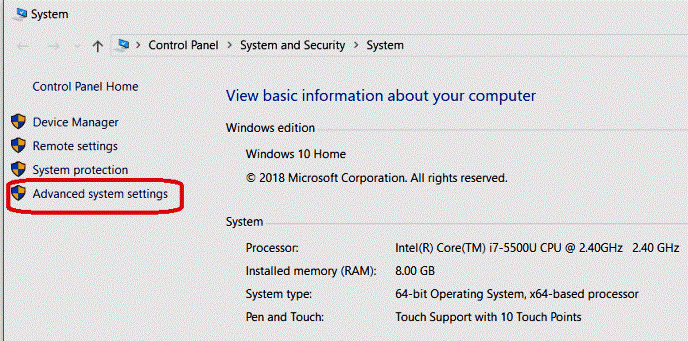
- 如果您没有引入Java 1.8,那么您必须先下载并引入它。如果现在设置了 JAVA_HOME 气候变量,此时检查路径中是否有任何空格(例如: C:\Program Files\ Java\… )。 JAVA_HOME 方式中的空格会导致您遇到问题。有一个特技可以绕过它。将’Program Files’ 补充到’Progra~1′ 中的变量值。保证Java的变体是 1.8 并且 JAVA_HOME 突出显示 JDK 1.8。
第 4 步:制作Java Home 路径的短名称


- 设置 Hadoop 环境变量
- 编辑 PATH 环境变量

- 单击新建并将 %JAVA_HOME%、%HADOOP_HOME%、%HADOOP_BIN%、%HADOOP_HOME%/sin 一一添加到您的 PATH 中。

- 现在我们已经设置了环境变量,我们需要验证它们。打开一个新的 Windows 命令提示符并对每个变量运行 echo 命令以确认它们被分配了所需的值。
echo %HADOOP_HOME%
echo %HADOOP_BIN%
echo %PATH%- 如果因素尚未确定,那么可能是因为您正在旧会议中尝试它们。确保您已打开另一个订单摘要来测试它们。
第 5 步:配置 Hadoop
设置环境变量后,我们需要通过编辑以下配置文件来配置 Hadoop。
hadoop-env.cmd
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
hadoop-env.cmd首先,让我们配置Hadoop环境文件。打开 C:\BigData\hadoop-3.1.2\etc\hadoop\hadoop-env.cmd 并在底部添加以下内容
set HADOOP_PREFIX=%HADOOP_HOME%
set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop
set YARN_CONF_DIR=%HADOOP_CONF_DIR%
set PATH=%PATH%;%HADOOP_PREFIX%\bin第 6 步:编辑 hdfs-site.xml
编辑core-site.xml后,需要设置复制因子以及namenode和datanode的位置。打开 C:\BigData\hadoop-3.1.2\etc\hadoop\hdfs-site.xml 和
dfs.replication
1
dfs.namenode.name.dir
C:\BigData\hadoop-3.2.1\data\namenode
dfs.datanode.data.dir
C:\BigData\hadoop-3.1.2\data\datanode
第 7 步:编辑 core-site.xml
现在,配置 Hadoop Core 的设置。打开 C:\BigData\hadoop-3.1.2\etc\hadoop\core-site.xml 和
fs.default.name
hdfs://0.0.0.0:19000
第 8 步:YARN 配置
编辑文件yarn-site.xml
确保以下条目存在,如下所示。
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
步骤 9:编辑 mapred-site.xml
最后,我们如何为 Map-Reduce 系统安排属性。打开 C:\BigData\hadoop-3.1.2\etc\hadoop\mapred-site.xml 和
mapreduce.job.user.name %USERNAME%
mapreduce.framework.name
yarn
yarn.apps.stagingDir /user/%USERNAME%/staging
mapreduce.jobtracker.address
local
检查 C:\BigData\hadoop-3.1.2\etc\hadoop\slaves 文件是否存在,如果不存在则创建一个并在其中添加 localhost 并保存它。
步骤 10:格式名称节点:
要组织名称节点,请打开另一个 Windows 命令提示符并运行下面的命令。它可能会给你一些忠告,不要理会它们。
- hadoop namenode -format

格式化 Hadoop 名称节点
第 11 步:启动 Hadoop:
打开另一个 Windows 命令简介,强调以管理员身份运行它以与授权错误保持战略距离。打开后,执行开头的all.cmd命令。由于我们已将 %HADOOP_HOME%\sbin 添加到 PATH 变量,因此您可以从任何信封运行此命令。如果您还没有这样做,那么请转到 %HADOOP_HOME%\sbin 管理器并运行该命令。

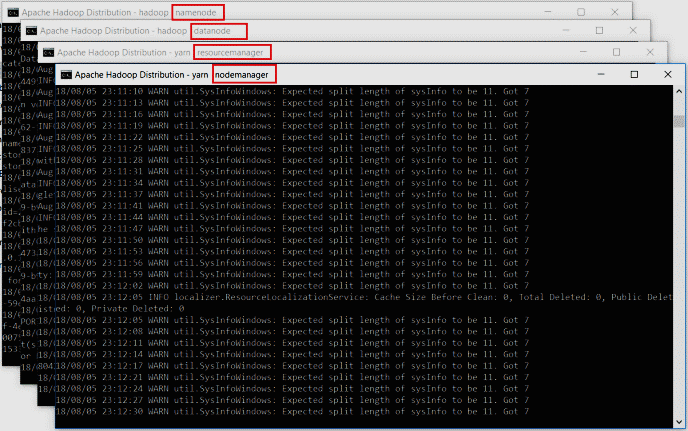
您可以查看下面给出的屏幕截图以供参考 将打开 4 个新窗口和 4 个守护进程的 cmd 终端,如下所示。
- 名称节点
- 数据节点
- 节点管理器
- 资源管理器
不要关闭这些窗口,将它们最小化。关闭窗口将终止守护进程。如果您不想看到这些窗口,可以在后台运行它们。
第 12 步:Hadoop Web UI
总之,我们如何筛选以了解 Hadoop 守护进程是如何相处的。您还可以将 Web UI 用于广泛的权威和观察目的。打开您的程序并开始。
第 13 步:资源管理器
打开 localhost:8088 打开资源管理器

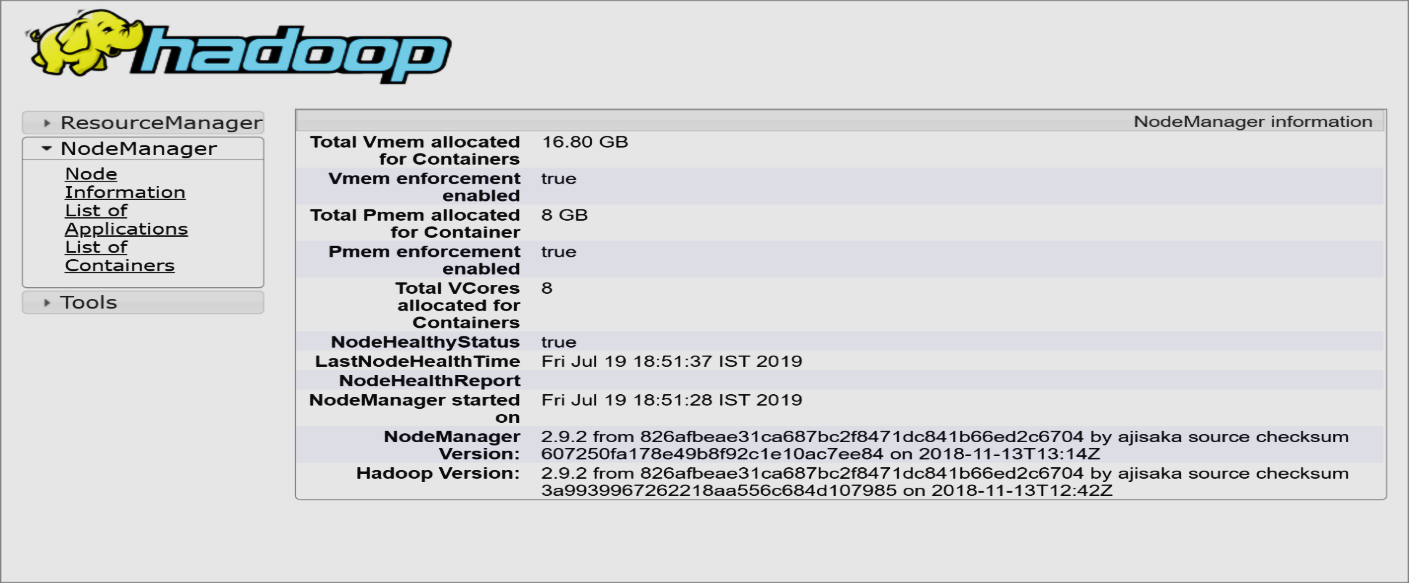
第 14 步:节点管理器
打开 localhost:8042 打开节点管理器
第 15 步:名称节点:
打开localhost:9870查看Name Node的健康
第 16 步:数据节点:
打开 localhost:9864 查看数据节点
