Hadoop 的 MapReduce 框架提供了缓存小到中等只读文件(如文本文件、zip 文件、jar 文件等)的工具,并将它们广播到运行 MapReduce 作业的所有数据节点(工作节点)。每个 Datanode 都会获得一份通过分布式缓存发送的文件副本(本地副本) 。作业完成后,这些文件将从 DataNode 中删除。
为什么要缓存文件?
MapReduce 作业需要一些文件,而不是每次从 HDFS 读取(增加寻道时间从而延迟) ,假设 100 次(如果 100 个 Mapper 正在运行),我们只需将文件副本发送到所有 Datanode一次.
让我们看一个例子,我们计算lyric.txt 中的单词,除了 stopWords.txt 中出现的单词。您可以在此处找到这些文件。
先决条件:
1. 将两个文件从本地文件系统复制到 HDFS。
bin/hdfs dfs -put ../Desktop/lyrics.txt /geeksInput
// this file will be cached
bin/hdfs dfs -put ../Desktop/stopWords.txt /cached_Geeks
2.获取NameNode服务器地址。由于文件必须通过 URI(统一资源标识符)访问,我们需要这个地址。它可以在core-site.xml 中找到
Hadoop_Home_dir/etc/hadoop/core-site.xml
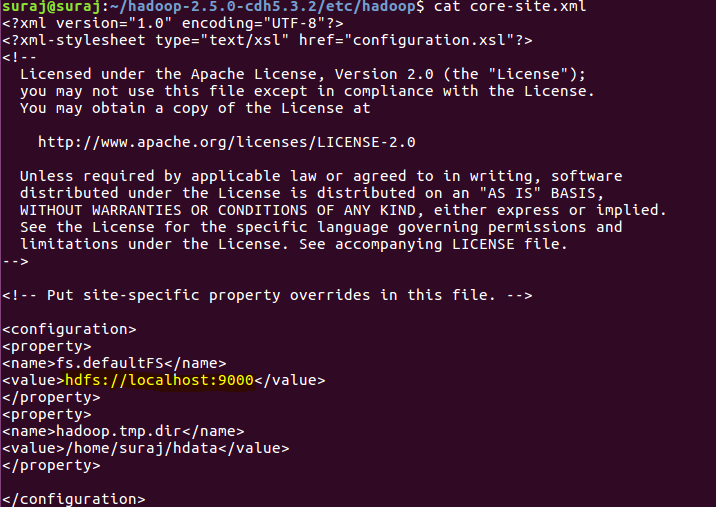
在我的 PC 中,它是hdfs://localhost:9000,它在您的 PC 中可能会有所不同。
映射器代码:
package word_count_DC;
import java.io.*;
import java.util.*;
import java.net.URI;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Cached_Word_Count extends Mapper {
ArrayList stopWords = null;
public void setup(Context context) throws IOException,
InterruptedException
{
stopWords = new ArrayList();
URI[] cacheFiles = context.getCacheFiles();
if (cacheFiles != null && cacheFiles.length > 0)
{
try {
String line = "";
// Create a FileSystem object and pass the
// configuration object in it. The FileSystem
// is an abstract base class for a fairly generic
// filesystem. All user code that may potentially
// use the Hadoop Distributed File System should
// be written to use a FileSystem object.
FileSystem fs = FileSystem.get(context.getConfiguration());
Path getFilePath = new Path(cacheFiles[0].toString());
// We open the file using FileSystem object,
// convert the input byte stream to character
// streams using InputStreamReader and wrap it
// in BufferedReader to make it more efficient
BufferedReader reader = new BufferedReader(new InputStreamReader(fs.open(getFilePath)));
while ((line = reader.readLine()) != null)
{
String[] words = line.split(" ");
for (int i = 0; i < words.length; i++)
{
// add the words to ArrayList
stopWords.add(words[i]);
}
}
}
catch (Exception e)
{
System.out.println("Unable to read the File");
System.exit(1);
}
}
}
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
String words[] = value.toString().split(" ");
for (int i = 0; i < words.length; i++)
{
// removing all special symbols
// and converting it to lowerCase
String temp = words[i].replaceAll("[?, '()]", "").toLowerCase();
// if not present in ArrayList we write
if (!stopWords.contains(temp))
{
context.write(new Text(temp), new LongWritable(1));
}
}
}
}
减速机代码:
package word_count_DC;
import java.io.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class Cached_Reducer extends Reducer {
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException
{
long sum = 0;
for (LongWritable val : values)
{
sum += val.get();
}
context.write(key, new LongWritable(sum));
}
}
驱动程序代码:
package word_count_DC;
import java.io.*;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Driver {
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException
{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2)
{
System.err.println("Error: Give only two paths for 如何执行代码?
- 将项目导出为 jar 文件并复制到您的 Ubuntu 桌面作为分布式示例.jar
- 启动您的 Hadoop 服务。进入 hadoop_home_dir 和终端类型
sbin/start-all.sh - 运行jar文件
bin/yarn jar jar_file_path packageName.Driver_Class_Name inputFilePath outputFilePath
bin/yarn jar ../Desktop/distributedExample.jar word_count_DC.Driver /geeksInput /geeksOutput

输出:
// will print the words starting with t bin/hdfs dfs -cat /geeksOutput/part* | grep ^t
在输出中,我们可以观察到不存在或这是我们想忽略的话。