Apache Hive最初由 Facebook 于 2010 年开发。它是一个数据仓库包,用于数据分析。 Hive用于管理和查询结构化数据,其查询语言称为 HQL 或 HIVEQL,与 SQL 查询语言非常相似。 Hadoop 提供了 MapReduce 作为在使用Java编程语言的 Hadoop 上工作的编程工具,因此 Facebook 开发人员引入了Hive ,以方便那些对 SQL 比Java更熟悉的用户。
Hive的特点:
- 数据存储在 HDFS 中
- MapReduce 代码可以轻松插入
- 对于容错,使用 Hadoop
- Hive中也提供了 JDBC/ODBC 驱动程序
Metastore记录了数据库模式和其他相关信息,如表元数据、表中的列及其数据类型等。默认情况下, Hive使用由 Derby 数据库组成的 Metastore,这对于测试目的很有用,但是当涉及到生产,用MySql类型的Metastore就好了。使用 Derby 数据库的一个主要缺点是我们无法访问多个Hive实例,因此我们将 MySql 用于生产目的。
先决条件:您必须预先安装Hadoop和Java才能安装 Apache Hive。
为Hive下载和配置 MySql Metastore 的步骤
步骤 1:通过单击此链接从其官方网站下载Hive ,并下载下图所示的 tar 文件,其大小约为143MB 。
将文件下载到/downloads文件夹中后,使用以下命令解压缩该文件,方法是转到/Downloads目录,然后将其放置在所需位置。就我而言,我将其移动到/Documents文件夹,因为我的 Hadoop 也安装在此目录中。
tar -xvf apache-hive-2.1.1-bin.tar.gz
第 2 步:现在下载Hive,使用以下命令安装 MySQL Java连接器。
sudo apt-get install libmysql-java
然后在 jar 文件和 hive lib 文件夹之间创建一个链接,并将 jar 复制到 lib 文件夹。
sudo ln -s /usr/share/java/mysql-connector-java.jar $HIVE_HOME/lib/mysql-connector-java.jar
步骤 3:移动到 apache-hive-2.1.1-bin 文件夹内的 /lib 文件夹,然后删除文件log4j-slf4j-impl-2.4.1.jar 。我们已删除此文件,因为 Hadoop 文件夹中也存在相同的文件,因此有时会出现错误。
第 4 步:现在使用以下命令启动 Hadoop:
start-dfs.shstart-yarn.sh
纱线用

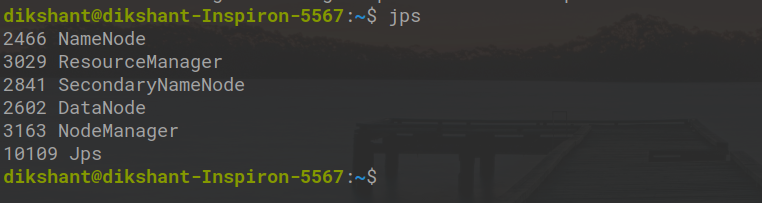
您可以使用命令jps确认所有守护进程是否开始正常工作。
第 5 步:一旦您的 Hadoop 启动,我们将为配置单元创建目录。在终端中执行以下命令以创建目录。
hdfs dfs -mkdir -p /user/hive/warehousehdfs dfs -mkdir -p /tmp/hive在 Warehouse 中,我们将存储我们的数据库和表的所有数据。所有这个目录都是默认的并且已经配置好了。

第 6 步:现在我们将使用以下命令更改所有此目录的权限。
hdfs dfs -chmod 777 /tmp/hdfs dfs -chmod 777 /user/hive/warehousehdfs dfs -chmod 777 /tmp/hive
第 7 步:现在我们将使用以下命令安装 MySQL。
sudo apt-get install mysql-server
第 8 步:进入 MySQL 终端后创建 Metastore 数据库,执行以下所有命令(使用root作为 SQL 的密码)。
mysql> sudo mysql -u root -p
mysql> CREATE DATABASE metastore_db;mysql> USE metastore_db;
如果用户名不同,请根据您和路径更改用户名。
mysql> SOURCE /home/{user-name}/Documents/apache-hive-2.1.1-bin/scripts/metastore/upgrade/mysql/hive-schema-0.14.0.mysql.sql;
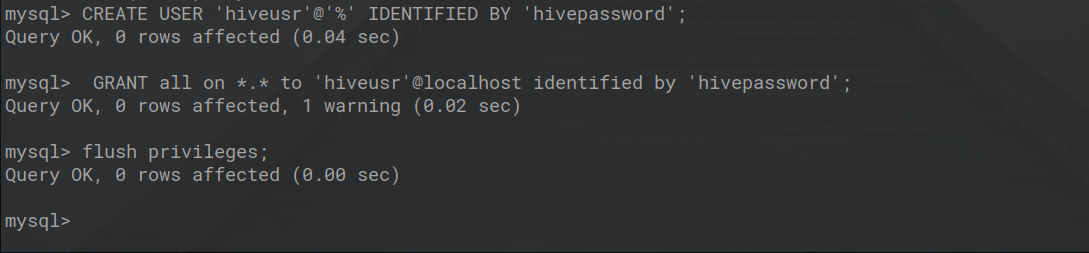
第 9 步:现在在mysql终端上使用以下命令创建 hive 用户和 hive 密码。
mysql> CREATE USER 'hiveusr'@'%' IDENTIFIED BY 'hivepassword';mysql> GRANT all on *.* to 'hiveusr'@localhost identified by 'hivepassword';mysql> flush privileges;就我而言,我的 hive 用户的名称是hiveusr ,密码是hivepassword 。默认情况下,您的 hive 用户是APP ,密码是我的,您可以根据需要更改用户名和密码。
然后输入 exit 退出 MySQL 终端。
mysql> exit
第 10 步:现在转到apache-hive-2.1.1-bin然后转到conf文件夹并将 hive-default.xml.template 重命名为hive-site.xml并将 hive-env.sh.template 重命名为hive-env.sh
第 11 步:现在我们开始配置 hive,因此转到hive-site.xml并更改以下属性。(使用 clrl+f 在文件中搜索属性)
答:连接网址
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost/metastore_db?createDatabaseIfNotExist=true

B:连接用户名
javax.jdo.option.ConnectionUserName
hiveusr
// 如果您在上面更改了用户名,请更改其值。

C:连接密码
javax.jdo.option.ConnectionPassword
hivepassword
// 如果您在上面更改密码,请更改密码。

D:连接驱动程序名称
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
MySQL JDBC driver class

第 12 步:现在打开hive-env.sh并在其中添加您的 hadoop 路径。
export HADOOP_HOME=/home/dikshant/Documents/hadoop
第 13 步:同时替换 hive-site.xml 中的以下值(使用 ctrl+f 搜索属性并在搜索框中输入名称)
A:替换这个属性
hive.exec.local.scratchdir
${system:java.io.tmpdir}/${system:user.name}
Local scratch space for Hive jobs
有了这个属性
hive.exec.local.scratchdir
/tmp/${user.name}
Local scratch space for Hive jobs

B:替换这个属性
hive.downloaded.resources.dir
${system:java.io.tmpdir}/${hive.session.id}_resources
Temporary local directory for added resources in the remote file system.
有了这些属性
hive.downloaded.resources.dir
/tmp/${user.name}_resources
Temporary local directory for added resources in the remote file system.

第 14 步:现在最重要的部分是在我们的.bashrc文件中设置Hive 的路径,因此使用以下命令打开.bashrc 。
sudo gedit ~/.bashrc复制下图所示的Hive路径并根据您的Hive路径(如果不同)更新它。
#Hive Path
export HIVE_HOME=/home/dikshant/Documents/apache-hive-2.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin

然后使用以下命令获取此文件。
source ~/.bashrc
第 15 步:现在运行以下命令来初始化 MySQL 数据库的架构。
schematool -initSchema -dbType mysql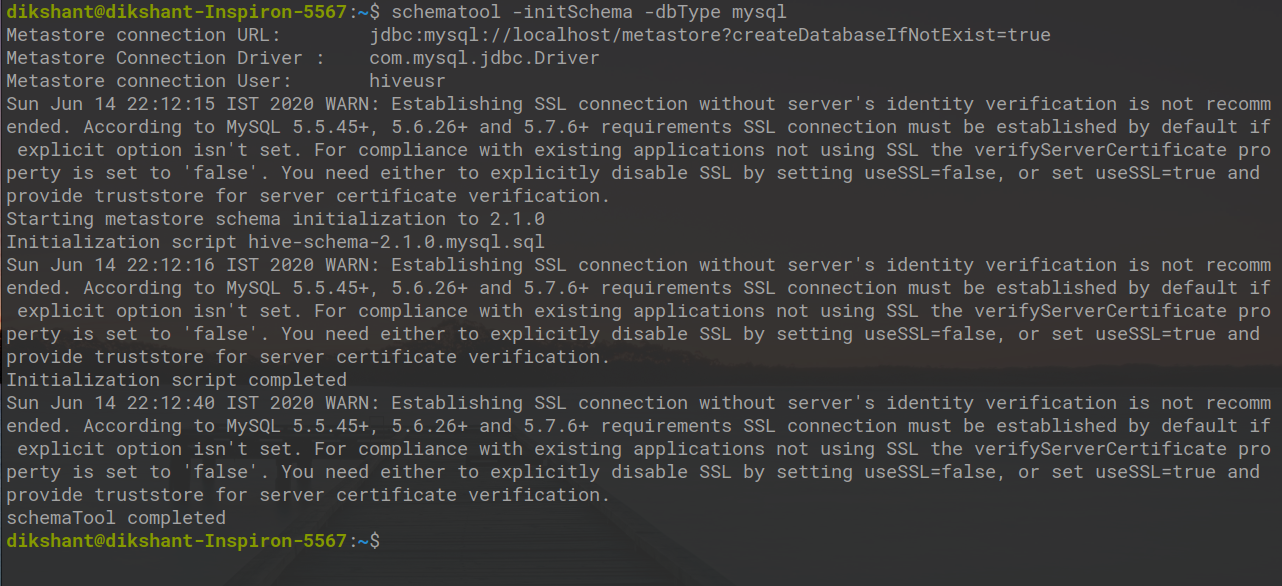
第 16 步:现在通过在终端中键入 hive 来运行 hive shell。
hive
