Map-Reduce 是一个处理框架,用于处理大量机器上的数据。 Hadoop 使用 Map-Reduce 来处理分布在 Hadoop 集群中的数据。 Map-Reduce 与其他常规处理框架(如 Hibernate、JDK、.NET 等)不同。所有这些以前的框架都旨在与数据存储在单个位置(如网络文件系统、Oracle 数据库)的传统系统一起使用等。但是当我们处理大数据时,数据在 HDFS 的帮助下位于多台商品机器上。
因此,当数据存储在多个节点上时,我们需要一个处理框架,它可以将程序复制到数据所在的位置,也就是将程序复制到数据所在的所有机器上。在这里,Map-Reduce 出现在通过分布式系统处理 Hadoop 上的数据的画面中。 Hadoop 具有跨交换机网络流量的主要缺点,这是由于海量数据造成的。 Map-Reduce 带有一个称为Data-Locality的功能。数据局部性是使计算更接近机器上实际数据位置的潜力。
由于 Hadoop 旨在在商品硬件上工作,因此它使用 Map-Reduce,因为它被广泛接受,它提供了一种在多个节点上处理数据的简单方法。 Map-Reduce 不是唯一的并行处理框架。如今,Spark 也是一种流行的框架,用于分布式计算,如 Map-Reduce。我们也有HAMA,MPI论文也是不同的分布式处理框架。
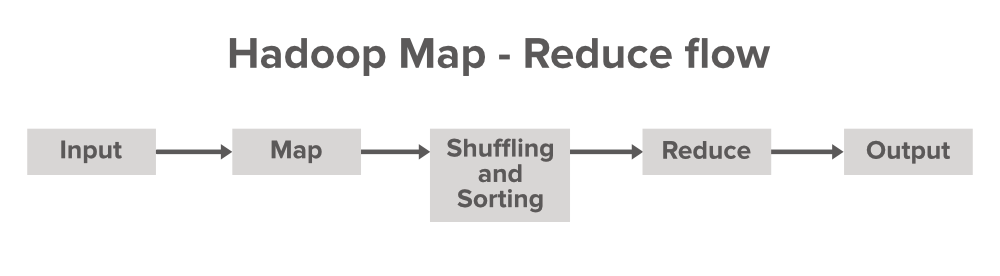
让我们了解 Map-Reduce 中的数据流
Map Reduce 是Map Phase和Reducer Phase附带的一个术语。 map 用于转换,而 Reducer 用于聚合类操作。 Map 和Reduce 的术语源自一些函数式编程语言,如Lisp、Scala 等。Map-Reduce 处理框架程序带有3 个主要组件,即我们的驱动程序代码、 Mapper (用于转换)和Reducer (用于聚合)。
让我们举一个例子,您有一个 10TB 的文件要在 Hadoop 上处理。 10TB 的数据首先分布在 Hadoop 上的多个节点上,使用 HDFS。现在我们必须处理它,因为我们有一个 Map-Reduce 框架。因此,为了使用 Map-Reduce 处理这些数据,我们有一个名为Job的驱动程序代码。如果我们使用Java编程语言处理 HDFS 上的数据,那么我们需要使用 Job 对象启动这个 Driver 类。假设您有一辆汽车,它是您的框架,而不是用于启动汽车的启动按钮类似于 Map-Reduce 框架中的此驱动程序代码。我们需要启动驱动程序代码来利用这个 Map-Reduce 框架的优势。
该框架还提供了Mapper和Reducer类,这些类是由开发人员根据组织要求预定义和修改的。
Mapper 的简要工作
Mapper 是最初与输入数据集交互的初始代码行。假设,如果我们正在分析的数据集有 100 个数据块,那么在这种情况下,将有 100 个 Mapper 程序或进程在机器(节点)上并行运行并产生自己的输出,称为中间输出,然后存储在本地磁盘上,而不是 HDFS 上。映射器的输出作为 Reducer 的输入,它对数据执行一些排序和聚合操作并产生最终输出。
减速机的简要工作
Reducer 是 Map-Reduce 编程模型的第二部分。 Mapper 以键值对的形式产生输出,作为 Reducer 的输入。但是在将这个中间键值对直接发送到 Reducer 之前,将完成一些过程,根据键值对键值对进行混洗和排序。 Reducer 生成的输出将是最终输出,然后存储在 HDFS(Hadoop 分布式文件系统)上。 Reducer 主要执行一些计算操作,如加法、过滤和聚合。
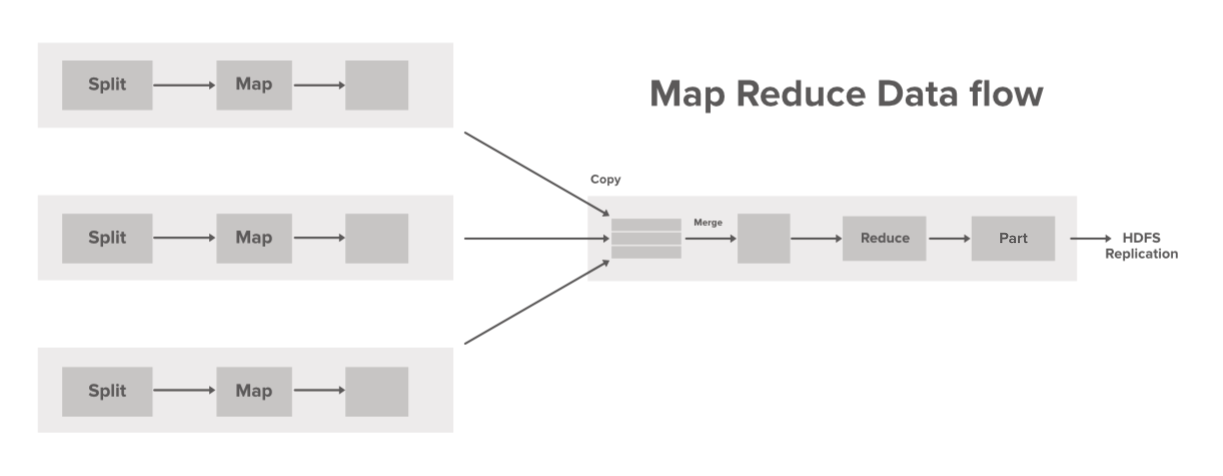
数据流步骤:
- 一次处理单个输入拆分。 Mapper 由开发人员根据业务逻辑覆盖,这个 Mapper 以并行方式在我们集群中的所有机器上运行。
- Mapper 生成的中间输出存储在本地磁盘上并混洗到reducer 以减少任务。
- 一旦 Mapper 完成他们的任务,输出就会被排序和合并并提供给 Reducer。
- Reducer 执行一些减少任务,如聚合和其他组合操作,然后最终输出存储在 HDFS 上的 part-r-00000(默认创建)文件中。