制表网
TabNet 由 Google Cloud 的研究人员于 2019 年提出。TabNet 背后的想法是将深度神经网络有效地应用于表格数据,这些表格数据仍然包含大量用户和跨各种应用程序(如医疗保健、银行、零售)的处理数据、金融、营销等
将深度学习应用于表格数据集的一个动机来自于其他领域,例如(图像、语言、语音)数据,当应用于它时,与其他机器学习技术相比,大型数据集的性能显着提高。因此,我们可以期望它适用于表格数据。另一个原因可能是那些与深度神经网络不同的基于树的算法无法通过使用梯度下降等技术有效地学习减少错误。
TabNet 提供了一种高性能且可解释的表格数据深度学习架构。它使用一种称为顺序注意机制的方法来启用选择哪个特征来导致高可解释性和高效训练。
建筑学:
TabNet 编码器
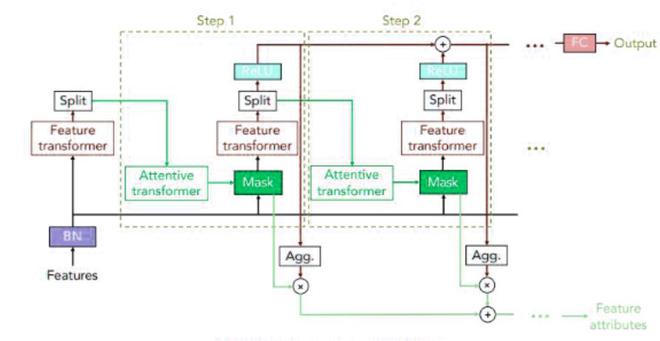
TabNet 编码器架构
TabNet 架构基本上由多个顺序的步骤组成,将输入从一个步骤传递到另一个步骤。根据容量有不同的方法来决定步数。每个步骤由以下步骤组成:
- 在初始步骤中,将完整的数据集输入到模型中,无需任何特征工程。然后通过批量归一化层,然后再通过特征变换器。
- 特征转换器:它由 n 个(例如 4 个)不同的 GLU 块组成。每个 GLU 块由以下层组成:
GLU block = Fully-Connected - Batch Normalization - GLU (Gated Linear Unit)其中 , GLU(x) = 
对于 4 层 GLU 块,2 个 GLU 块应该是共享的,2 个应该是独立的,这有助于鲁棒和高效的学习。有一个跳过连接也存在 b/w 两个连续的块。在每个块之后,我们执行归一化 为了获得稳定性并确保方差不会发生很大变化。特征转换器输出两个输出:
为了获得稳定性并确保方差不会发生很大变化。特征转换器输出两个输出:
 它是特定步骤的输出决策,给出了对连续值/类别的预测。
它是特定步骤的输出决策,给出了对连续值/类别的预测。  下一个循环开始的下一个注意力转换器的输出。
下一个循环开始的下一个注意力转换器的输出。
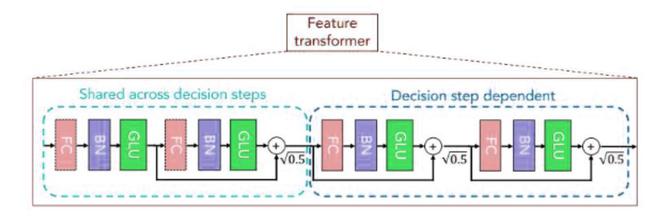
特征转换器
- Attentive Transformer: Attentive Transformer 由全连接 (FC) 层、BatchNorm 层、Prior scales 层和 Sparsemax 层组成。它接收输入 \mathbb{n_a} 并在通过全连接层和批量归一化层后,然后通过先前的尺度层。
- 这个先前的比例层聚合了在当前决策步骤之前每个特征已经使用了多少。
 ;所有功能都是平等的。
;所有功能都是平等的。
P_i = \prod_{j=1}^{i} (\gamma – M ) ; γ 的值越小,步长越独立,  看不同的特征。
看不同的特征。
Sparsemax 层:用于系数的归一化(类似于 softmax),导致特征的稀疏选择:

如果很多特征都为零,那么我们将应用实例特征选择,其中只有不同特征的一个子集用于不同的步骤。
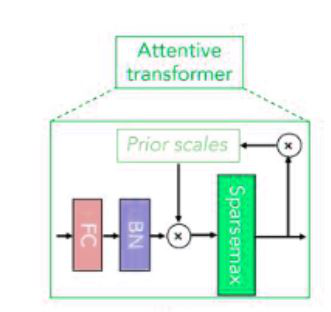
贴心的变压器
- 注意掩码:注意力变换步骤的输出,然后被输入到注意力掩码中,它有助于识别选定的特征。除了对每个步骤的分析之外,它还量化了聚合特征的重要性。组合不同步骤的掩码需要一个系数,该系数可以衡量决策中每个步骤的相对重要性。因此,作者提出:
![\eta_b [i] = \sum_{c=1}^{N_d} ReLU(d_{b,c} [i])](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/TabNet_10.png "由 QuickLaTeX.com 渲染") 表示第 b 个样本在第 i 个决策步骤的总决策贡献。在每个决策步骤缩放决策掩码
表示第 b 个样本在第 i 个决策步骤的总决策贡献。在每个决策步骤缩放决策掩码![\eta_b [i]](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/TabNet_11.png "由 QuickLaTeX.com 渲染") ,作者提出聚合特征重要掩码:
,作者提出聚合特征重要掩码:
![M_{agg - b,j} = \frac{\sum_{i=1}^{N_{steps}} \eta_b [i] M_{b,j} [i]}{\sum_{j=1}^{D} \sum_{i=1}^{N_{steps}} \eta_b [i] M_{b,j} [i]^{2}}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/TabNet_12.png "由 QuickLaTeX.com 渲染")
TabNet 解码器
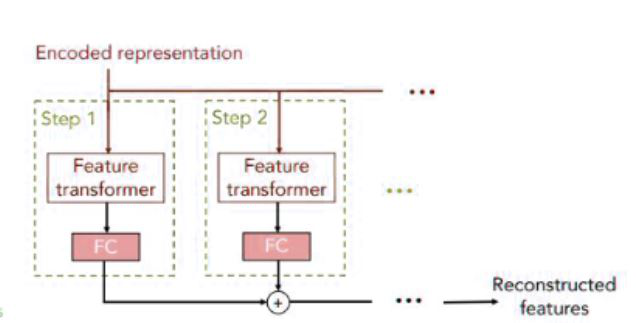
TabNet 解码器
TabNet 解码器架构由一个特征变换器组成,然后是决策步骤的全连接层。然后将输出与重建的特征相加。自监督阶段的重建损失函数:

执行
我们将在此实现中使用 TabNet 的 Pytorch 实现。对于数据集,我们将使用 Loan Approval 预测,一个人是否会获得它申请的贷款:
Python3
# Install TabNet
pip install pytorch-tabnet
# imports necessary modules
from pytorch_tabnet.tab_model import TabNetClassifier
import os
import torch
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder, MinMaxScalar
from sklearn.metrics import accuracy_score
# Load training and test data
data =pd.read_csv('/content/train.csv')
data.head()
data.isna().sum()
# load test data
test_data = pd.read_csv('/content/test.csv')
test_data.head()
test_data.isna().sum()
# set index column
data.set_index('Loan_ID', inplace=True)
test_data.set_index('Loan_ID', inplace=True)
# Replace NAs
data.fillna(method="bfill", inplace=True)
test_data.fillna(method="bfill", inplace=True)
# convert categorical column to integer Labels
gen = LabelEncoder().fit(data['Gender'])
data['Gender'] = gen.transform(data['Gender'])
s_type= LabelEncoder().fit(data['Married'])
data['Married'] = s_type.transform(data['Married'])
n_dep= LabelEncoder().fit(data['Dependents'])
data['Dependents'] = n_dep.transform(data['Dependents'])
edu= LabelEncoder().fit(data['Education'])
data['Education'] = edu.transform(data['Education'])
s_emp = LabelEncoder().fit(data['Self_Employed'])
data['Self_Employed'] = s_emp.transform(data['Self_Employed'])
c_history = LabelEncoder().fit(data['Credit_History'])
data['Credit_History'] = c_history.transform(data['Credit_History'])
p_area = LabelEncoder().fit(data['Property_Area'])
data['Property_Area'] = p_area.transform(data['Property_Area'])
l_status = LabelEncoder().fit(data['Loan_Status'])
data['Loan_Status'] = l_status.transform(data['Loan_Status'])
# For test data
test_data['Gender'] = gen.transform(test_data['Gender'])
test_data['Married'] = s_type.transform(test_data['Married'])
test_data['Dependents'] = n_dep.transform(test_data['Dependents'])
test_data['Education'] = edu.transform(test_data['Education'])
test_data['Self_Employed'] = s_emp.transform(test_data['Self_Employed'])
test_data['Credit_History'] = c_history.transform(test_data['Credit_History'])
test_data['Property_Area'] = p_area.transform(test_data['Property_Area'])
# select feature and target variable
X = data.loc[:,data.columns != 'Loan_Status']
y = data.loc[:,data.columns == 'Loan_Status']
X.shape, y.shape
# convert to numpy
X= X.to_numpy()
y= y.to_numpy()
y= y.flatten()
# define and train the Tabnet model with cross validation
kf = KFold(n_splits=5, random_state=42, shuffle=True)
CV_score_array =[]
for train_index, test_index in kf.split(X):
X_train, X_valid = X[train_index], X[test_index]
y_train, y_valid = y[train_index], y[test_index]
tb_cls = TabNetClassifier(optimizer_fn=torch.optim.Adam,
optimizer_params=dict(lr=1e-3),
scheduler_params={"step_size":10, "gamma":0.9},
scheduler_fn=torch.optim.lr_scheduler.StepLR,
mask_type='entmax' # "sparsemax"
)
tb_cls.fit(X_train,y_train,
eval_set=[(X_train, y_train), (X_val, y_val)],
eval_name=['train', 'valid'],
eval_metric=['accuracy'],
max_epochs=1000 , patience=100,
batch_size=28, drop_last=False)
CV_score_array.append(tb_cls.best_cost)
# Test model and generate prediction
predictions =[ 'N' if i < 0.5 else 'Y' for i in tb_cls.predict(X_test)]Collecting pytorch-tabnet
Downloading pytorch_tabnet-3.1.1-py3-none-any.whl (39 kB)
Requirement already satisfied: numpy<2.0,>=1.17 in /usr/local/lib/python3.7/dist-packages (from pytorch-tabnet) (1.19.5)
Requirement already satisfied: scikit_learn>0.21 in /usr/local/lib/python3.7/dist-packages (from pytorch-tabnet) (0.22.2.post1)
Requirement already satisfied: torch<2.0,>=1.2 in /usr/local/lib/python3.7/dist-packages (from pytorch-tabnet) (1.9.0+cu102)
Requirement already satisfied: scipy>1.4 in /usr/local/lib/python3.7/dist-packages (from pytorch-tabnet) (1.4.1)
Requirement already satisfied: tqdm<5.0,>=4.36 in /usr/local/lib/python3.7/dist-packages (from pytorch-tabnet) (4.62.2)
Requirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit_learn>0.21->pytorch-tabnet) (1.0.1)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from torch<2.0,>=1.2->pytorch-tabnet) (3.7.4.3)
Installing collected packages: pytorch-tabnet
Successfully installed pytorch-tabnet-3.1.1# train data
Loan_ID Gender Married Dependents Education Self_Employed ApplicantIncome CoapplicantIncome LoanAmount Loan_Amount_Term Credit_History Property_Area Loan_Status
0 LP001002 Male No 0 Graduate No 5849 0.0 NaN 360.0 1.0 Urban Y
1 LP001003 Male Yes 1 Graduate No 4583 1508.0 128.0 360.0 1.0 Rural N
2 LP001005 Male Yes 0 Graduate Yes 3000 0.0 66.0 360.0 1.0 Urban Y
3 LP001006 Male Yes 0 Not Graduate No 2583 2358.0 120.0 360.0 1.0 Urban Y
4 LP001008 Male No 0 Graduate No 6000 0.0 141.0 360.0 1.0 Urban Y
# null values
Loan_ID 0
Gender 13
Married 3
Dependents 15
Education 0
Self_Employed 32
ApplicantIncome 0
CoapplicantIncome 0
LoanAmount 22
Loan_Amount_Term 14
Credit_History 50
Property_Area 0
Loan_Status 0
dtype: int64# test data
Loan_ID Gender Married Dependents Education Self_Employed ApplicantIncome CoapplicantIncome LoanAmount Loan_Amount_Term Credit_History Property_Area
0 LP001015 Male Yes 0 Graduate No 5720 0 110.0 360.0 1.0 Urban
1 LP001022 Male Yes 1 Graduate No 3076 1500 126.0 360.0 1.0 Urban
2 LP001031 Male Yes 2 Graduate No 5000 1800 208.0 360.0 1.0 Urban
3 LP001035 Male Yes 2 Graduate No 2340 2546 100.0 360.0 NaN Urban
4 LP001051 Male No 0 Not Graduate No 3276 0 78.0 360.0 1.0 Urban
# Null values
Loan_ID 0
Gender 11
Married 0
Dependents 10
Education 0
Self_Employed 23
ApplicantIncome 0
CoapplicantIncome 0
LoanAmount 5
Loan_Amount_Term 6
Credit_History 29
Property_Area 0
dtype: int64# x, y shape
((614, 11), (614, 1))Device used : cpu
Early stopping occurred at epoch 137 with best_epoch = 37 and best_valid_accuracy = 0.84416
Best weights from best epoch are automatically used!
Device used : cpu
Early stopping occurred at epoch 292 with best_epoch = 192 and best_valid_accuracy = 0.86364
Best weights from best epoch are automatically used!
Device used : cpu
Early stopping occurred at epoch 324 with best_epoch = 224 and best_valid_accuracy = 0.85065
Best weights from best epoch are automatically used!
Device used : cpu
Early stopping occurred at epoch 143 with best_epoch = 43 and best_valid_accuracy = 0.84416
Best weights from best epoch are automatically used!
Device used : cpu
Early stopping occurred at epoch 253 with best_epoch = 153 and best_valid_accuracy = 0.84416
Best weights from best epoch are automatically used!参考:
- TabNet 纸