在 PySpark 数据框中添加具有默认值的新列
在本文中,我们将了解如何在 PySpark Dataframe 中添加具有默认值的新列。
将列作为具有默认值的 DataFrame 添加到 PandPySpark 的三种方法。
- 使用 pyspark.sql.DataFrame.withColumn(colName, col)
- 使用 pyspark.sql.DataFrame.select(*cols)
- 使用 pyspark.sql.SparkSession.sql(sqlQuery)
方法一:使用pyspark.sql.DataFrame.withColumn(colName, col)
它向 DataFrame 添加一列或替换具有相同名称的现有列,并将包含所有现有列的新 DataFrame 返回到新列。列表达式必须是此 DataFrame 上的表达式,并且从其他某个 DataFrame 添加列将引发错误。
Syntax: pyspark.sql.DataFrame.withColumn(colName, col)
Parameters: This method accepts the following parameter as mentioned above and described below.
- colName: It is a string and contains name of the new column.
- col: It is a Column expression for the new column.
Returns: DataFrame
首先,创建一个简单的 DataFrame。
Python3
import findspark
findspark.init()
# Importing the modules
from datetime import datetime, date
import pandas as pd
from pyspark.sql import SparkSession
# creating the session
spark = SparkSession.builder.getOrCreate()
# creating the dataframe
pandas_df = pd.DataFrame({
'Name': ['Anurag', 'Manjeet', 'Shubham',
'Saurabh', 'Ujjawal'],
'Address': ['Patna', 'Delhi', 'Coimbatore',
'Greater noida', 'Patna'],
'ID': [20123, 20124, 20145, 20146, 20147],
'Sell': [140000, 300000, 600000, 200000, 600000]
})
df = spark.createDataFrame(pandas_df)
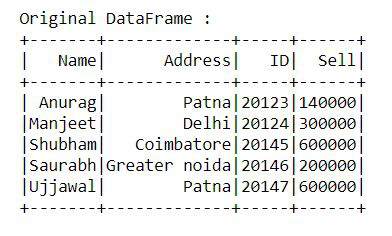
print("Original DataFrame :")
df.show()Python3
# Add new column with NUll
from pyspark.sql.functions import lit
df = df.withColumn("Rewards", lit(None))
df.show()
# Add new constanst column
df = df.withColumn("Bonus Percent", lit(0.25))
df.show()Python3
import findspark
findspark.init()
# Importing the modules
from datetime import datetime, date
import pandas as pd
from pyspark.sql import SparkSession
# creating the session
spark = SparkSession.builder.getOrCreate()
# creating the dataframe
pandas_df = pd.DataFrame({
'Name': ['Anurag', 'Manjeet', 'Shubham',
'Saurabh', 'Ujjawal'],
'Address': ['Patna', 'Delhi', 'Coimbatore',
'Greater noida', 'Patna'],
'ID': [20123, 20124, 20145, 20146, 20147],
'Sell': [140000, 300000, 600000, 200000, 600000]
})
df = spark.createDataFrame(pandas_df)
print("Original DataFrame :")
df.show()Python3
# Add new column with NUll
from pyspark.sql.functions import lit
df = df.select('*', lit(None).alias("Rewards"))
# Add new constanst column
df = df.select('*', lit(0.25).alias("Bonus Percent"))
df.show()Python3
import findspark
findspark.init()
# Importing the modules
from datetime import datetime, date
import pandas as pd
from pyspark.sql import SparkSession
# creating the session
spark = SparkSession.builder.getOrCreate()
# creating the dataframe
pandas_df = pd.DataFrame({
'Name': ['Anurag', 'Manjeet', 'Shubham',
'Saurabh', 'Ujjawal'],
'Address': ['Patna', 'Delhi', 'Coimbatore',
'Greater noida', 'Patna'],
'ID': [20123, 20124, 20145, 20146, 20147],
'Sell': [140000, 300000, 600000, 200000, 600000]
})
df = spark.createDataFrame(pandas_df)
print("Original DataFrame :")
df.show()Python3
# Add columns to DataFrame using SQL
df.createOrReplaceTempView("GFG_Table")
# Add new column with NUll
df=spark.sql("select *, null as Rewards from GFG_Table")
# Add new constanst column
df.createOrReplaceTempView("GFG_Table")
df=spark.sql("select *, '0.25' as Bonus_Percent from GFG_Table")
df.show()输出:

添加具有默认值的新列:
蟒蛇3
# Add new column with NUll
from pyspark.sql.functions import lit
df = df.withColumn("Rewards", lit(None))
df.show()
# Add new constanst column
df = df.withColumn("Bonus Percent", lit(0.25))
df.show()
输出:

方法二:使用pyspark.sql.DataFrame.select(*cols)
我们可以使用 pyspark.sql.DataFrame.select() 在 DataFrame 中创建一个新列并将其设置为默认值。它投影一组表达式并返回一个新的 DataFrame。
Syntax: pyspark.sql.DataFrame.select(*cols)
Parameters: This method accepts the following parameter as mentioned above and described below.
- cols: It contains column names (string) or expressions (Column)
Returns: DataFrame
首先,创建一个简单的 DataFrame。
蟒蛇3
import findspark
findspark.init()
# Importing the modules
from datetime import datetime, date
import pandas as pd
from pyspark.sql import SparkSession
# creating the session
spark = SparkSession.builder.getOrCreate()
# creating the dataframe
pandas_df = pd.DataFrame({
'Name': ['Anurag', 'Manjeet', 'Shubham',
'Saurabh', 'Ujjawal'],
'Address': ['Patna', 'Delhi', 'Coimbatore',
'Greater noida', 'Patna'],
'ID': [20123, 20124, 20145, 20146, 20147],
'Sell': [140000, 300000, 600000, 200000, 600000]
})
df = spark.createDataFrame(pandas_df)
print("Original DataFrame :")
df.show()
输出:

添加具有默认值的新列:
蟒蛇3
# Add new column with NUll
from pyspark.sql.functions import lit
df = df.select('*', lit(None).alias("Rewards"))
# Add new constanst column
df = df.select('*', lit(0.25).alias("Bonus Percent"))
df.show()
输出:

方法三:使用pyspark.sql.SparkSession.sql(sqlQuery)
我们可以使用 pyspark.sql.SparkSession.sql() 在 DataFrame 中创建一个新列并将其设置为默认值。它返回一个表示给定查询结果的 DataFrame。
Syntax: pyspark.sql.SparkSession.sql(sqlQuery)
Parameters: This method accepts the following parameter as mentioned above and described below.
- sqlQuery: It is a string and contains the sql executable query.
Returns: DataFrame
首先,创建一个简单的 DataFrame:
蟒蛇3
import findspark
findspark.init()
# Importing the modules
from datetime import datetime, date
import pandas as pd
from pyspark.sql import SparkSession
# creating the session
spark = SparkSession.builder.getOrCreate()
# creating the dataframe
pandas_df = pd.DataFrame({
'Name': ['Anurag', 'Manjeet', 'Shubham',
'Saurabh', 'Ujjawal'],
'Address': ['Patna', 'Delhi', 'Coimbatore',
'Greater noida', 'Patna'],
'ID': [20123, 20124, 20145, 20146, 20147],
'Sell': [140000, 300000, 600000, 200000, 600000]
})
df = spark.createDataFrame(pandas_df)
print("Original DataFrame :")
df.show()
输出:
添加具有默认值的新列:
蟒蛇3
# Add columns to DataFrame using SQL
df.createOrReplaceTempView("GFG_Table")
# Add new column with NUll
df=spark.sql("select *, null as Rewards from GFG_Table")
# Add new constanst column
df.createOrReplaceTempView("GFG_Table")
df=spark.sql("select *, '0.25' as Bonus_Percent from GFG_Table")
df.show()
输出:
