MultiLabel分类简介
监督机器学习技术最常用的功能之一是对内容进行分类,在许多情况下使用,例如判断给定餐厅评论是正面还是负面,或者推断图像上是否有猫或狗。该任务可分为三个领域,二元分类、多类分类和多标签分类。在本文中,我们将解释这些类型的分类以及它们彼此不同的原因,并展示可以使用多标签分类的真实场景。
分类类型的区别
- 二进制分类:
当只有两个不同的类别并且我们要分类的数据仅属于其中一个类别时使用它,例如,将关于给定产品的帖子分类为正面或负面; - 多类分类:当有三个或更多类并且我们要分类的数据只属于其中一个类时使用,例如对图像上的信号量是红色、黄色还是绿色进行分类;
- 多标签分类:
当有两个或更多类并且我们要分类的数据可能不属于任何一个类或同时属于所有类时使用它,例如分类图像中包含哪些交通标志。
真实世界的多标签分类场景
我们将在本教程中解决的问题是从 twitter 中提取餐厅评论的方面。在这种情况下,文本的作者可能不提及或提及预设列表的所有方面,在我们的例子中,该列表由五个方面组成:服务、食物、轶事、价格和氛围。为了训练模型,我们将使用最初在 2014 年国际语义评估研讨会上为竞赛提出的数据集,它被称为 SemEval-2014,包含有关文本中各个方面及其各自极性的数据,用于本教程我们仅使用有关方面的数据,有关原始比赛及其数据的更多信息可以在他们的网站上找到。
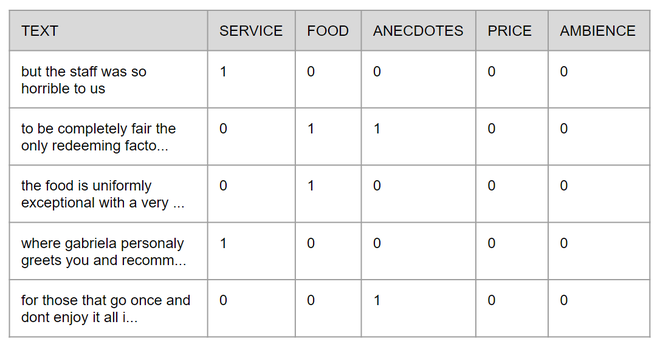
为简单起见,本教程将原始 XML 文件转换为 CSV 文件,该文件将在 GitHub 上提供完整代码。每行由文本及其包含的方面组成,这些方面的存在或不存在分别由 1 和 0 表示,下图显示了表格的外观。
我们需要做的第一件事是导入所需的库,所有这些库都在下面的代码片段中,如果您熟悉机器学习,您可能会认出其中的一些。
代码:导入库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from skmultilearn.adapt import MLkNN
from sklearn.metrics import hamming_loss, accuracy_score
之后,我们必须导入文本并正确拆分它们以训练模型,但是原始文本本身对机器学习算法没有多大意义,因此我们必须以不同的方式表示它们,有很多不同的形式来表示文本,这里我们将使用一种简单但非常强大的技术,称为 TF-IDF,它代表 Term Frequency – Inverse Document Frequency,简而言之,它用于表示文本语料库中每个单词的重要性,您可以在这篇令人难以置信的文章中找到有关 TF-IDF 的更多详细信息。在下面的代码中,我们将文本集分配给 X 并将每个文本中包含的方面分配给 y,为了将数据从行文本转换为 TF-IDF,我们将使用函数fit创建类 TfidfVectorizer 的实例为它提供完整的文本集,以便稍后我们可以使用这个类来转换拆分集,最后,我们将使用 70% 的数据在训练数据和测试数据之间拆分数据进行训练,其余的进行测试最终模型,并使用我们之前创建的 TfidfVectorizer 实例的函数transform转换每个集合。
代码:
aspects_df = pd.read_csv('semeval2014.csv')
X = aspects_df["text"]
y = np.asarray(aspects_df[aspects_df.columns[1:]])
# initializing TfidfVectorizer
vetorizar = TfidfVectorizer(max_features=3000, max_df=0.85)
# fitting the tf-idf on the given data
vetorizar.fit(X)
# splitting the data to training and testing data set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)
# transforming the data
X_train_tfidf = vetorizar.transform(X_train)
X_test_tfidf = vetorizar.transform(X_test)
现在一切都设置好了,所以我们可以实例化模型并训练它!可以使用多种方法来执行多标签分类,这里使用的一种是 MLKnn,它是著名的 Knn 算法的改编版,就像它的前身 MLKnn 根据目标与来自数据的距离来推断目标的类别一样训练基地,但假设它可能不属于任何班级或所有班级。
代码:
# using Multi-label kNN classifier
mlknn_classifier = MLkNN()
mlknn_classifier.fit(X_train_tfidf, y_train)
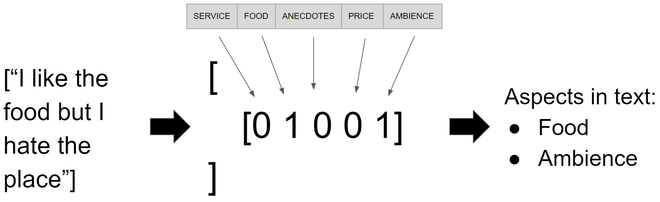
训练模型后,我们可以运行一个小测试,看看它适用于任何句子,我将使用句子“我喜欢食物,但我讨厌这个地方” ,但可以随意使用任何你喜欢的句子。正如我们对训练和测试数据所做的那样,我们需要将新句子的向量转换为 TF-IDF,然后使用模型实例中的函数predict ,这将为我们提供一个可以转换为数组的稀疏矩阵函数toarray返回一个数组数组,其中每个数组上的每个元素都推断出一个方面的存在,如图 2 所示。
代码:
new_sentences = ["I like the food but I hate the place"]
new_sentence_tfidf = vetorizar.transform(new_sentences)
predicted_sentences = mlknn_classifier.predict(new_sentence_tfidf)
print(predicted_sentences.toarray())
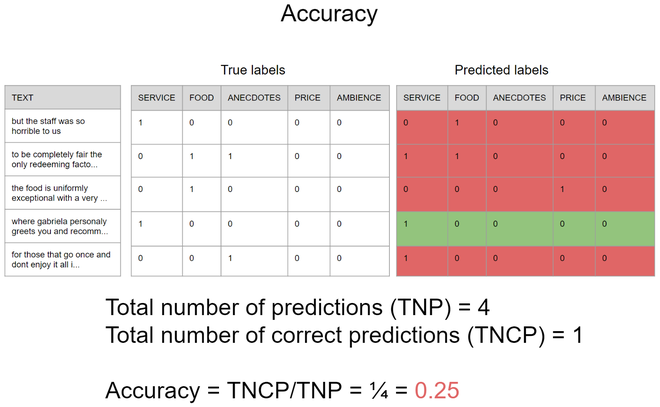
现在,我们必须做机器学习管道中最重要的部分之一,即测试。在这部分,与多类问题有一些显着差异,例如,我们不能以相同的方式使用准确率,因为一个单一的预测会同时推断出许多类,如图 3 所示的假设场景,请注意当使用准确度时,只有与真实标签完全相等的预测才被认为是正确的预测,因此准确度为 0.25,这意味着如果您试图预测 100 个句子中只有 25 个句子的方面,那么所有句子的存在和不存在方面将同时被正确预测。
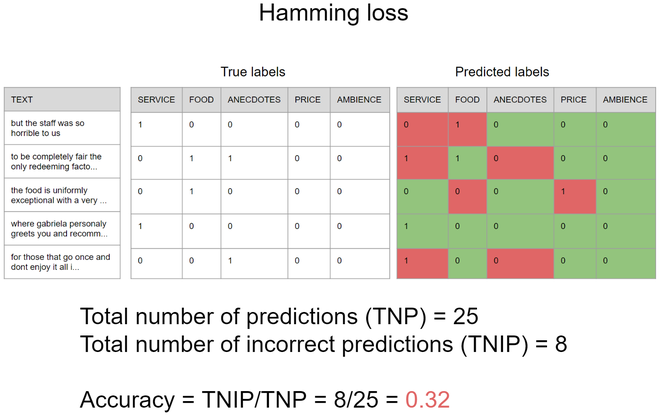
另一方面,有一个更合适的指标可以用来衡量模型独立预测每个方面的存在有多好,这个指标称为汉明损失,它等于不正确预测的数量除以模型的输出可能包含一个或多个预测的预测总数,下图使用上一个示例的相同场景说明了它是如何工作的,重要的是要注意,汉明损失的准确性不太可能,结果越小模型越好。因此,在这种情况下,汉明损失为 0.32,这意味着如果您尝试预测 100 个句子的方面,该模型将错误地预测大约 32% 的独立方面。
尽管第二个指标似乎更适合此类问题,但重要的是要记住所有机器学习问题彼此不同,因此它们中的每一个都可以像往常一样结合一组不同的指标来更好地理解模型的性能,没有灵丹妙药。要使用这些,我们将使用 sklearn 的度量模块,该模块使用模型使用测试数据执行的预测并与真实标签进行比较。
代码:
predicted = mlknn_classifier.predict(X_test_tfidf)
print(accuracy_score(y_test, predicted))
print(hamming_loss(y_test, predicted))
所以现在如果一切都正确,准确度接近 0.47 ,汉明损失接近0.16 !