探索分类数据
分类变量/数据(或名义变量):
此类变量具有固定且有限数量的可能值。例如——等级、性别、血型等。此外,在分类变量的情况下,逻辑顺序与分类数据不同,例如“一”、“二”、“三”。但是这些变量的排序使用逻辑顺序。例如,性别是一个分类变量,有类别——男性和女性,类别没有内在顺序。纯分类变量是一种仅允许您分配类别,但您无法清楚地对变量进行排序的变量。
与变异性度量相关的术语:
- 模式:给定数据中最常出现的值
例子-Data = ["Car", "Bat", "Bat", "Car", "Bat", "Bat", "Bat", "Bike"] Mode = "Bat" - 期望值:在机器学习中工作时,类别必须与数值相关联,以便理解机器。这给出了基于类别发生概率的平均值,即预期值。
它的计算方式是——-> Multiply each outcome by its probability of occurring. -> Sum these values因此,它是值的总和乘以它们的发生概率,通常用于总结因子变量水平。
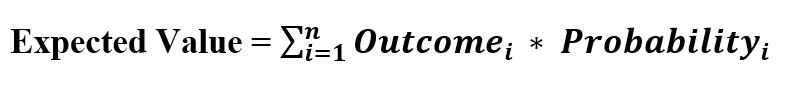
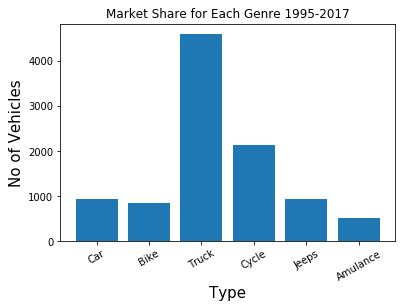
- 条形图:每个类别的频率绘制为条形图。
加载库 –
import matplotlib.pyplot as plt import numpy as np数据 -
label = ['Car', 'Bike', 'Truck', 'Cycle', 'Jeeps', 'Amulance'] no_vehicle = [941, 854, 4595, 2125, 942, 509]索引数据 –
index = np.arange(len(label)) print ("Total Labels : ", len(label)) print ("Indexing : ", index)输出:
Total Labels : 6 Indexing : [0 1 2 3 4 5]条状图 -
plt.bar(index, no_vehicle) plt.xlabel('Type', fontsize = 15) plt.ylabel('No of Vehicles', fontsize = 15) plt.xticks(index, label, fontsize = 10, rotation = 30) plt.title('Market Share for Each Genre 1995-2017') plt.show()输出:
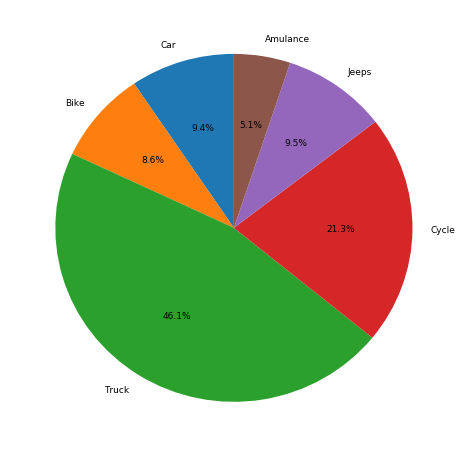
- 饼图:每个类别的频率绘制为饼图或楔形图。它是一个圆形图,其中每个切片的弧长与其表示的数量成正比。
plt.figure(figsize =(8, 8)) plt.pie(no_vehicle, labels = label, startangle = 90, autopct ='%.1f %%') plt.show()输出: